GPU互連已成AI晶片大廠間的兵家必爭之地。除了居於領先地位的NVLink,以及獲得眾多生態系成員支持的開放標準UALink外,近期博通(Broadcom)也推出了基於乙太網技術的ESUN。ESUN的出現,會如何影響GPU互連的生態系發展與勢力版圖分配?
NVIDIA GPU因GenAI/LLM的興起而水漲船高,一是眾多AI程式師倚賴NVIDIA CUDA軟體訓練AI模型,從而不得不倚賴NVIDIA GPU晶片,另一是單顆NVIDIA GPU效能仍是侷限,NVIDIA透過其專屬的NVLink介面連接多顆GPU,從而構成更強大的AI系統。
因此,即便有其他業者的AI硬體加速晶片,具備可媲美NVIDIA GPU的效能,其銷售依然不樂觀,因為開發者不熟CUDA以外的軟體開發工具,或即便願意改換工具,為了加快模型訓練通常需要用及頂級AI系統,競爭晶片缺乏如NVLink的高速連接,其頂級系統效能不若NVIDIA的方案。
為了制衡與挑戰NVLink,業界於2024年發起UALink,有十餘家科技大廠支持,如超微(AMD)、英特爾(Intel)、微軟(Microsoft)、Google等,並在2025年頒布1.0版正式標準。
面對以產業聯盟型態發展的UALink,NVIDIA也未坐以待斃,提出NVLink Fusion主張,即維持NVLink專屬技術發展路線,但拉攏更多半導體業者採行NVLink技術,如今有AsteraLabs、英特爾(因NVIDIA入股)、聯發科、富士通(Fujitsu)、邁威爾(Marvell)、高通(Qualcomm)等晶片商加入;另外晶片設計服務商世芯、矽智財授權商安謀(Arm)也加入;近期也傳聞AWS將加入,預計在新一代的Trainium4晶片中採用NVLink。
而在UALink正式標準出爐後,UALink陣營的一名重要成員博通(Broadcom)卻選擇另闢路線,於2025年6月提出SUE(Scale-Up Ethernet)技術,更之後於10月於OCP峰會期間揭露ESUN(Ethernet for Scale-Up Network)技術,並於隨後退出UALink董事會運作,但仍保有一般成員身份。不過,由於SUE與ESUN兩詞過於相似,博通現已將SUE改稱SUE-Transport或SUE-T,以加強區別。
SUE-T與ESUN的提出,讓AI系統的機內擴展(Scale-up)連接技術方案再起變數,更多晶片商與系統商不知該選擇NVLink、UALink或SUE-T+ESUN?且ESUN的提出也不全然受抵制,包含NVIDIA、超微也在首波表態支持ESUN的業者陣營中。
由此可知ESUN並非全然為技術抗衡而提,而是帶有既競爭又合作的意涵,本文以下將對ESUN進行更多技術觀察,並推測後續對產業的影響。
ESUN強調協定包容性
ESUN主張的一個大重點在於它不涉及高效能晶片間的傳輸內容與機制,而是運用乙太網路(Ethernet)原有的傳輸特性作為底層,與其上可包裝運載各種晶片間的傳輸協定。
因此,ESUN之上可以是SUE-T,也可以是UALink或其他協定,更上層的協定負責負載平衡、記憶體存取、排程等,而位於底層的ESUN負責傳輸時的錯誤修正、減少傳輸開銷(Overhead)等(圖1)。
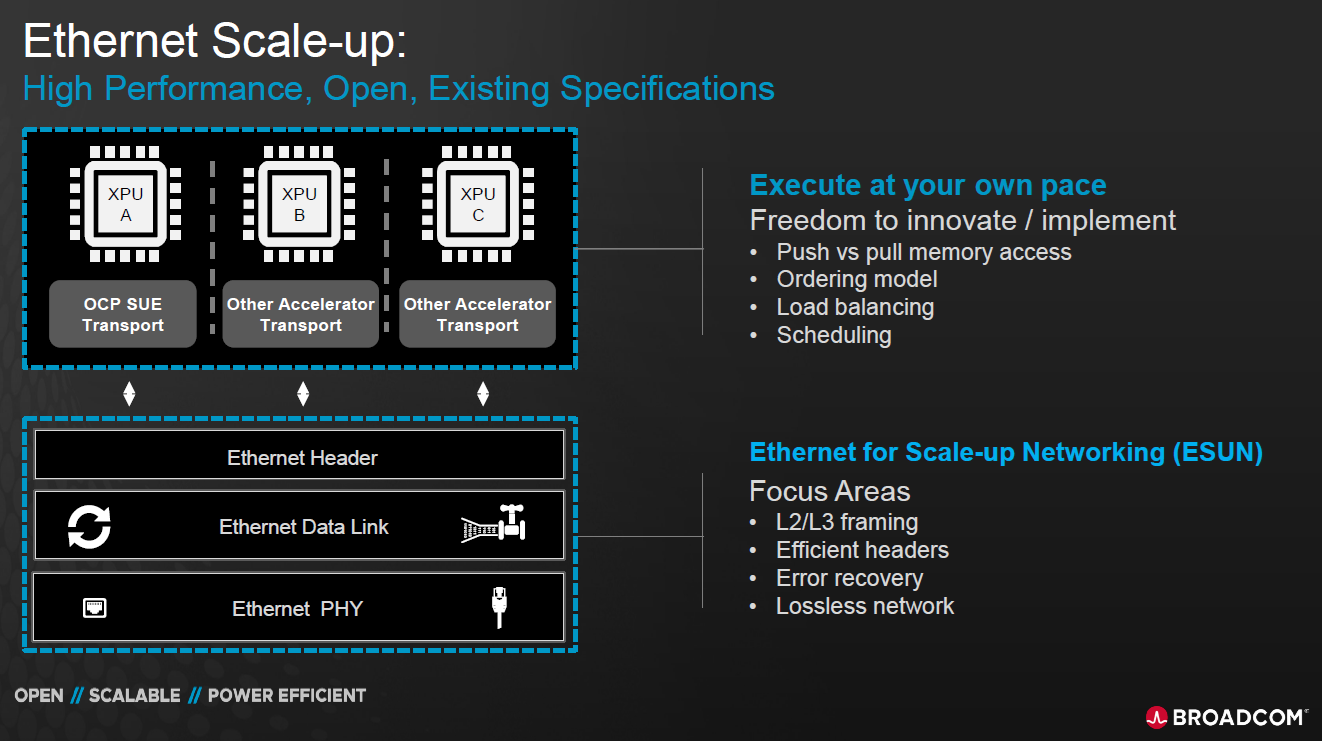 圖1 ESUN強調與xPU協定並存運作(圖片來源:博通)
圖1 ESUN強調與xPU協定並存運作(圖片來源:博通)
更簡單說,ESUN方案需要以類似NVLink Switch晶片(NVIDIA獨家供貨)或UALink Switch晶片(目前尚少見)的方式來實現。因此,博通必然會以其Tomahawk Ultra晶片來擴展延伸,使其充當ESUN Switch晶片的角色。
事實上,UALink確實能以不同的底層實現傳輸,例如xGMI介面、CHI C2C介面或今日高速晶片普遍具備的PCIe介面等,但目前仍以UALink原生搭配的IEEE 802.3dj介面速率最快,可達200Gbps,PCIe若為最新的第七代則為128Gbps。
ESUN強調技術規格數據
ESUN既然定位在「可在底層包容、肩負各種高速晶片間協定」,自然必須有強大的技術能耐,反之若自身技術成為效能傳輸瓶頸,自然不會被業界採納,最終難以推展。
依據博通在2025年10月OCP峰會上的揭露ESUN,其傳輸頻寬可達102Tbps,不僅能支援現行GPU、AI ASISC(如AWS Trainium系列、Google Cloud TPU系列)常搭配的HBM3e記憶體,也能支援後續推出的HBM4記憶體。
強大的傳輸率是ESUN第一個包容保證,其次是晶片的連接數,此前UALink已強調其可達1024個連接,而ESUN則可提供2048個連接,言下之意可實現更強大的單一AI系統。
目前NVIDIA最頂級的AI系統為NVIDIA GB200 NVL72,內有72顆GPU與36顆CPU,更後續將推出NVL576(研發代號Vera Rubin),意即單一系統最高可達576顆GPU(單一封裝內有4個GPU裸晶,算4顆晶片),另外再加上CPU等,確實已接近1024顆。
其三是低傳輸延遲。博通期望將ESUN Switch晶片的傳輸延遲壓在250奈秒(ns)內,同時若2顆xPU晶片間的讀取、寫入動作能壓在150ns內,傳輸延遲將低於400ns(圖2)。
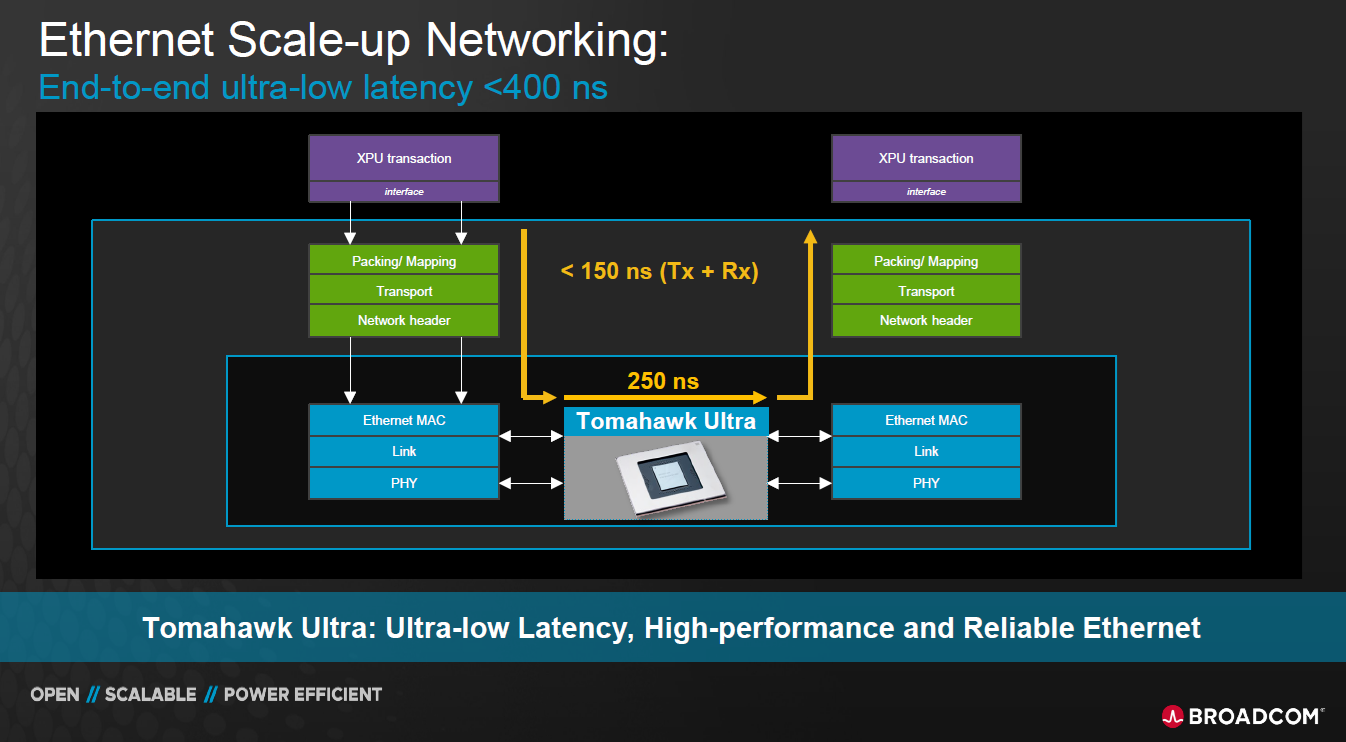 圖2 ESUN期望讓xPU間的傳輸延遲在400nS內(圖片來源:博通)
圖2 ESUN期望讓xPU間的傳輸延遲在400nS內(圖片來源:博通)
ESUN接軌機外擴展
ESUN方案主要用於機內擴展(Scale-up),而今日的大型資訊系統已不再是單一大機箱的設計,而是以多個低矮輕薄機箱,以模組方式堆砌成單一大系統,故ESUN不只是在單一系統電路板上傳輸,也有機會短距離跨連鄰近的機箱,但即便如此,透過ESUN連接的多個機箱,在運作機理上仍被視為一個單一連續的系統。
事實上,NVLink與UALink也是如此。透過在機內連接更多晶片、記憶體等組件,以實現效能提升,此稱為Scale-Up。但效能的提升除了Scale-Up外,也有其他作法,例如運用網路連接多個機箱系統,從而獲得更高的整體效能,此稱為機外擴展(Scale-out)。
機外擴充所用的網路目前也有多個方案,以NVIDIA而言,可推行其近乎專屬的InfiniBand,而超微與多數大廠則是力主以Ethernet技術為基礎,針對AI系統與應用進行相關調整,從而成為UEC(Ultra Ethernet Consortium)方案。
而對博通而言,由於該公司已是Ethernet交換器晶片的領導業者,自然也是強調在Scale-out上採行Ethernet方案,Broadcom自身也是UEC主要成員之一。
由於Scale-up的ESUN根基於Ethernet,而Scale-out可用標準Ethernet或UEC,故採行ESUN的另一好處是更易於內外接軌,用戶不用拘泥於追求單一系統的極致高效能,而是透過多部系統共同協定,同樣能加速AI模型訓練工作。
對此,博通強調其Tomahawk 6晶片已可達到128k個GPU連接,在2層次的網路連接上每個交換器能有102Tbps傳輸率,若為3層次則每個交換器有51Tbps傳輸率。另也有跨甲地、乙地或多地的網路連接加速方案,此對NVIDIA而言稱為Scale-across,但博通仍將這種應用情境稱為Scale-out。
NVIDIA、超微各有盤算 UALink最受衝擊
為何NVIDIA與AMD也在ESUN首波支持業者名單中?此或許可以從多個層面來解釋。
一,NVIDIA與AMD並沒有完全堅持自有介面技術,NVIDIA的GPU既可用NVLink連接也能用PCIe連接,視系統商與用戶需求而定,而超微力主的UALink如前所述,其底層可使用原生自有介面也可用PCIe。
事實上Scale-up介面在少數晶片間的連接時,可以讓晶片間直接互接,不需要透過交換器晶片。初階系統大多採用這種互連方式,只有中高階系統因晶片連接數多,才會用上Switch晶片。
其次,Scale-up介面的交換器晶片不是NVIDIA、超微的主要業務,銷售顆數必然少於GPU,但卻需要極高的傳輸能耐(高傳輸率、多連接、低延遲等),工程挑戰高,對於以處理晶片設計為主的晶片商,能額外提撥多少研發能量於高速交換器晶片,實為一大考驗。
即便有了效能表現佳的Scale-up交換器晶片,因技術難度高、用量少,在量價均攤的長期競爭下,是否能與相對開放、大用量的Ethernet交換器晶片競爭,也有挑戰,故NVIDIA、超微可將ESUN視為備胎方案,一方面保有自身上層協定,但底層傳輸的仍有其他選擇,一直是近年來各種介面融合的常態作法。
不過,ESUN仍是對UALink陣營較大傷害,畢竟博通的淡出,會減弱UALink陣營的氣勢,且UALink交換器才剛起步,相較於2017年、2018年便有的NVLink交換器落後多年,同時以產業聯盟型態發展的技術,通常技術推進速度不若專屬技術。
歸結而言,在開放(基於Ethernet)與多年量價均攤上,ESUN均處於有利位置,在長期技術推進速度上專屬封閉的NVLink也有優勢,使UALink有些前後失據,不過ESUN在爭取夥伴方面的進展慢於NVLink Fusion,短期內三種技術路線都將持續面臨市場考驗。