記憶體內運算(Computing in Memory)可說是AI加速器架構的一種,實際運算過程是經過記憶體的數據資料,直接在記憶體內先行運算,而後將實際得到的分析結果傳送至處理器,由此打破傳統馮紐曼型架構(von Neumann Architecture)完全透過處理器進行分析,即使處理器的運算速度遠快於記憶體讀寫,資料處理速度仍會受記憶體傳輸頻寬所局限,使其運算速度受到影響。相較之下,記憶體內運算能以低功耗、高效率的方式,在終端裝置上進行影像或語音辨識的能力。
目前大多數的AI運算都是透過軟體的類神經網路實現,最初概念來自於生物的神經網路,其運作方式為模擬生物或人類的神經元,建立一個數學的模型。將這個簡單的數學模型複製再複製後,即能成就一個深度學習網路,進行許多訊號的處理(如影像處理),其處理速度遠比人腦還快。然而,要打造更高性能且分析速度快的AI應用,需要很大量的運算,亟需使用硬體來加速運算效能,也因此興起一波記憶體內運算的風潮。
甚麼是記憶體內運算呢?近期所看到的Computing in Memory與In-Memory Computing是否為相同的東西?工研院電子與光電系統研究所半導體晶片與設計組組長許世玄(圖1)表示,目前記憶體內運算的定義非常混亂,但整體而言可分成兩種,一種是將Computing in Memory與In-Memory Computing畫上等號,屬於類比運算的一種。而另一種提到的In-Memory Computing,則是採用Systolic Array類型的架構,或稱Near In-Memory Computing,此種方式是將運算單元與記憶體整合在一起進行運算,目前代表廠商為Google(如TPU架構)、Gyrfalcon(圖2)。
 圖1 工研院電子與光電系統研究所半導體晶片與設計組組長許世玄表示,記憶體內運算主要採用類比式運算方式,可提供高能效的優勢,非常適用於辨識相關應用。
圖1 工研院電子與光電系統研究所半導體晶片與設計組組長許世玄表示,記憶體內運算主要採用類比式運算方式,可提供高能效的優勢,非常適用於辨識相關應用。
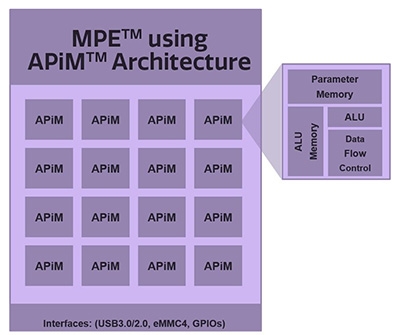 圖2 Systolic Array類型的運算架構圖
圖2 Systolic Array類型的運算架構圖
資料來源:Gyrfalcon
四大AI運算架構
所謂的AI運算,也就是計算矩陣的乘法與加法。整體而言AI運算可分成四種類型,一種是CPU的架構,記憶體傳遞資料到CPU,由CPU進行運算處理,再將分析好的資料回傳給記憶體;第二種則是採用GPU的運算方式,GPU是由許多運算能力高的運算單元所組成的架構,一樣將記憶體內的資料丟入GPU進行平行運算,運算完後將結果送到記憶體內。這兩種方式都是採用數位邏輯的運算方式進行處理。
第三者種則是類似於Google TPU架構,其運算單元都各自搭配自己的小記憶體形成的運算架構,可以就近互相搬移資料做運算,不受單一記憶體運算所影響。最後則是類比式運算架構,也就是第一種Computing in Memory架構(圖3)。記憶體運算本身就是一個類比運算的概念,從類比運算得到的電流值,推算出所有乘加結果,所以它的效益與能量效益很高,這也是它特別之處。
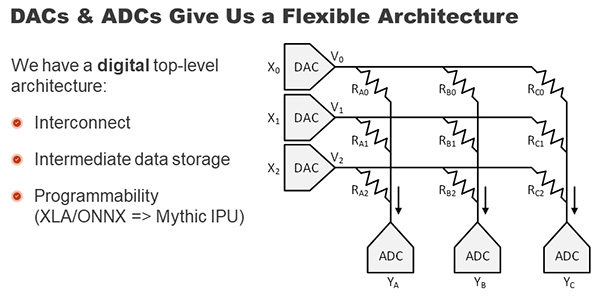 圖3 類比式運算架構圖
圖3 類比式運算架構圖
資料來源:Mythic
許世玄談到,傳統馮紐曼型架構最大問題在於傳輸頻寬不足,所有運算速度都被記憶體頻寬限制住了,無論是CPU或GPU在進行資料搬移時,會受限於記憶體頻寬不足的問題,延長資料搬移的時間,即便運算速度再怎麼提升,仍會拖累處理速度。
挾高能效優勢 類比運算強勢進駐
相較於傳統馮紐曼型架構採數位邏輯處理方式,類比式記憶體運算架構可說是當紅的AI運算架構。據了解,記憶體內運算架構近幾年來開始吸引許多人進行研究,這些架構目前已被廣泛應用於仿神經型態運算晶片及人工智慧處理晶片上。記憶體可使用SRAM、DRAM、Flash、MRAM、RRAM、PCM、FeRAM等進行設計與規畫。
許世玄指出,AI運算方式正在向高能效的目標邁進,相較於傳統CPU、GPU運算,記憶體內運算架構可提供的能效高達10~100倍以上,近期業界更有聲浪表示能效達1,000倍,其運算效率已經逼近於人腦的運算。
乘載著高能效的優勢,記憶體內運算已逐漸朝商品化邁進。許世玄表示,目前國際大廠已開始積極研發推進記憶體內運算產品化,而工研院亦朝系統產品研發角度,協助台灣廠商進行產品化。
手寫辨識應用成形 記憶體內運算方案出籠
日前工研院所舉辦的「工研菁英獎」活動中發表記憶體內運算技術,其透過FPGA送訊號到記憶體,讓記憶體直接進行運算,當場也展示應用於手寫辨識應用。不僅是如此,該技術同樣也可滿足影像辨識或語音辨識的應用,有望解決過去視訊監控錄影,通常都是透過手動方式尋找事件,其運算處理能效低,且無法隨身攜帶的缺點。
工研院超低功耗記憶體內運算技術,可提供高達10倍以上的能效,應用於AI、事件辨識預警、AI輔助決策等應用。許世玄表示,工研院記憶體內運算僅需搭配低階的CPU,即能滿足AI辨識所需要運算效果。
目前工研院已與部分廠商開始合作一些影像辨識及語音辨識的系統開發。在記憶體產品化過程中,最大問題在於記憶體元件物理特性及製程特性導致的偏移問題,因此這項技術會建立在成熟度高的記憶體內。預計最快看到商品化的記憶體類型為SRAM,其次為Flash與RRAM的產品類型。
據了解,工研院團隊在記憶體的產業效益已達台幣14億以上,其中RRAM技轉國際半導體均已量產,帶動半導體產業升級。2020年產業效益預估可達8,000萬,包含國內外半導體大廠技術合作、專利技轉等。
許世玄分析,台灣在記憶體內運算技術中掌握兩大優勢,第一是台灣本身有良好的半導體製造產業,擁有最好的邏輯製程技術;再者台灣有許多記憶體廠商,包含旺宏、華邦與力積電等廠商,研發實力不容小覷,將有助於台灣打造下世代AI加速器的開闊未來。