2024年月底在美國聖地牙哥舉行的OFC2024上,英特爾展示了將CPU與先進光學運算互聯(OCI)Chiplet共同封裝的原型CPU。本文將介紹這項技術的部分細節,以及這項技術突破對運算產業的影響。
使用AI的應用程式越來越多地被部署和定位為全球經濟的驅動力,並影響我們整個社會的演變。大型語言模型(LLM)和生成式AI的最新發展只會加速這一趨勢。
更大、更高效的機器學習(ML)模型將在滿足AI加速工作負載的新興需求方面發揮關鍵作用。顯著擴展未來運算結構的需求推動了I/O頻寬的指數級成長,並延長了連接範圍,以支援更大的XPU集群,以及具有更高效資源利用率的架構,例如GPU分解和記憶體池。
電氣I/O(即銅線連接)支援高頻寬密度和低功耗,但僅限於約1米或更短的距離。當前數據中心和早期AI集群中使用的可插拔光收發器模組可以擴大覆蓋範圍,但其成本和功率水準無法滿足AI工作負載的擴展要求。
共同封裝的XPU(CPU、GPU、IPU)光學I/O解決方案可以支援更高的頻寬、高功率效率、低延遲和更長的覆蓋範圍,這正是AI/ML基礎設施擴展所需要的。
基於Intel Silicon Photonics的光學I/O解決方案
Intel基於Intel內部的矽光子技術開發了一款4Tbps雙向完全整合的OCI Chiplet(圖1),以滿足AI基礎設施對頻寬的巨大需求並支援未來的可擴充性。此OCI Chiplet包含一個帶有雷射的單個矽光子積體電路(PIC)、一個電氣積體電路(EIC),和一個用於整合可拆卸/可重複使用的光連接器。
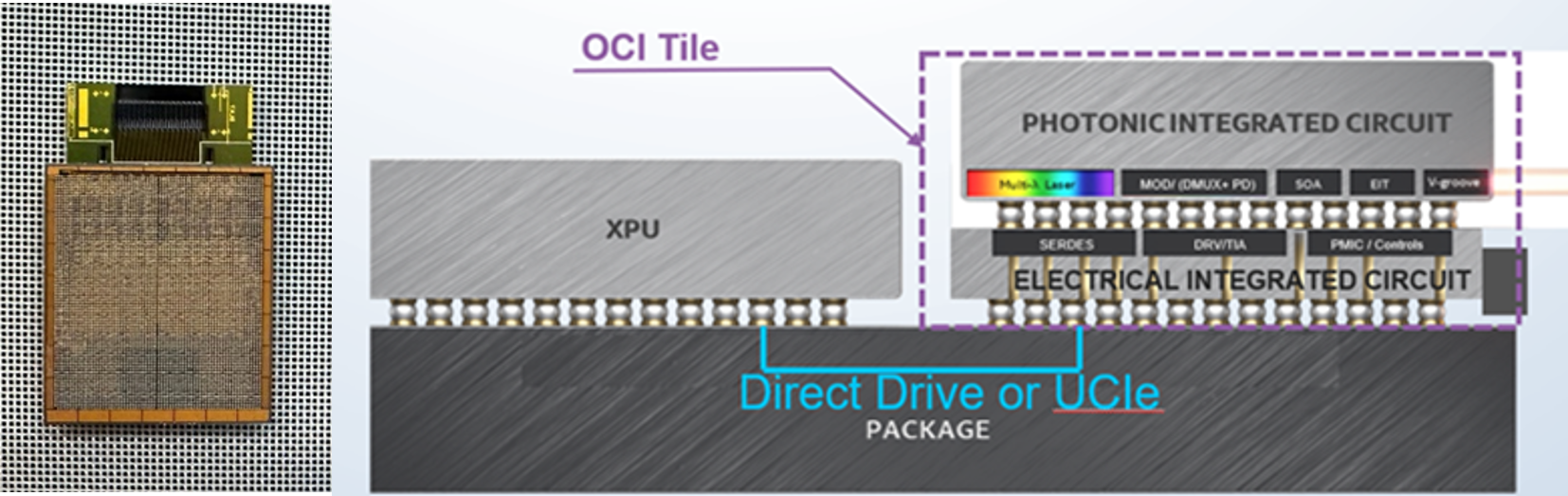 圖1 Intel 4Tbps光運算互連(OCI)Chiplet
圖1 Intel 4Tbps光運算互連(OCI)Chiplet
OCI Chiplet可以與下一代CPU、GPU、IPU和其他具有高頻寬需求的系統單晶片(SoC)共同封裝。第一個OCI Chiplet的成功,為後續提供多TB光連接打下穩固基礎。與PCIe Gen6相比,這個OCI Chiplet實作的邊緣頻寬密度(Shoreline Desity)提高了超過4倍,能源效率為3pJ/bit以下,延遲則低於10ns(+tof),訊號傳輸距離可超過100米。
英特爾於3月26日至28日在聖地牙哥舉行的OFC 2024上,展示其第一代整合了CPU與OCI Chiplet的原型產品(圖2、圖3)。該原型處理器可以在光纖上運行無錯誤(Error Free)鏈路,在PRBS31模式下,BER<10e-12。其OCI是一個與PCIe Gen5相容的4Tbps雙向Chiplet,可以在數十公尺的距離內支援雙向64個32Gbps數據通道。其所使用的光纖數量為8對,每對光纖可承載8個DWDM波長。在這款OCI之後,英特爾後續還將推出支援32Tbps的OCI Chiplet。
 圖2 英特爾在OFC 2024中展示的CPU+OCI原型裝置
圖2 英特爾在OFC 2024中展示的CPU+OCI原型裝置
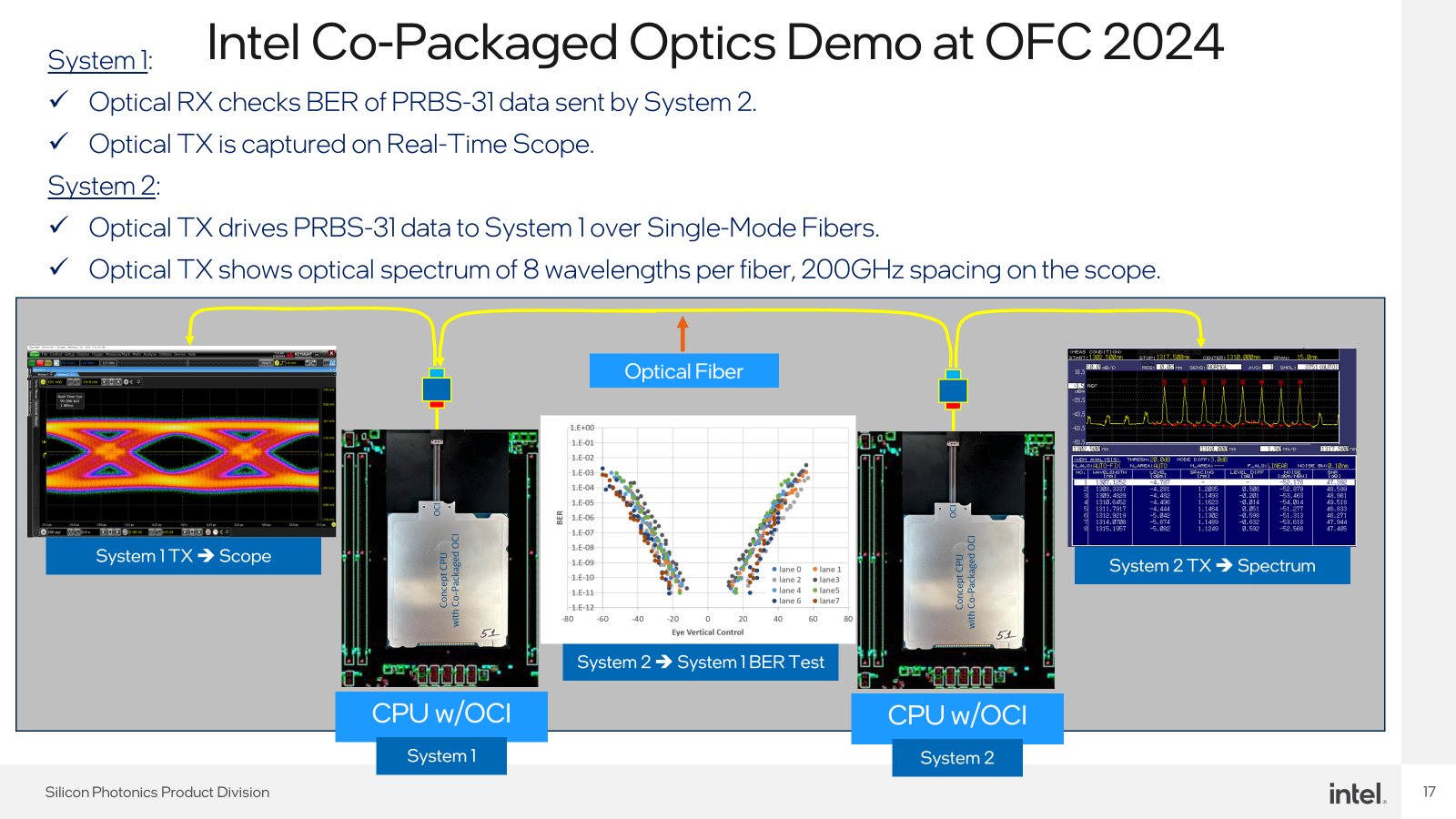 圖3 英特爾在OFC 2024上的展示內容
圖3 英特爾在OFC 2024上的展示內容
在這個展示元件中的單個PIC可支援高達8Tbps的雙向應用,並且包含一個完整的光學子系統。英特爾具有在PIC上整合DWDM雷射陣列和光放大器的能力,可提供比傳統磷化銦(InP)雷射高幾個數量級的可靠性。這些整合的矽光子晶片在英特爾位於美國的一家晶圓廠生產,該晶圓廠已經出貨超過800萬個PIC,上面搭載了超過3200萬個片上(On-die)雷射器。這些PIC被應用在資料中心網路的可插拔光收發器中,具有領先業界的可靠性。
除了性能優勢和經過驗證的可靠性外,片上雷射技術還支援真正的晶圓級製造、老化和測試,而讓子系統的結構更簡化,也更可靠(因為沒有光纖連接外部雷射源和PIC),製造效率也更好。
另一個差異化優勢是,OCI使用廣泛部署的標準單模光纖(SMF-28),而無需像市場上的其他技術方法那樣需要採用保偏光纖(Polarization Maintaining Fiber, PMF)。圖4是該OCI發射器透過一條標準單模光纖傳送出的訊號。因為系統振動和光纖擺動會對PMF的性能和相關的鏈路預算產生負面影響,故PMF很少被大量部署在實際應用中。
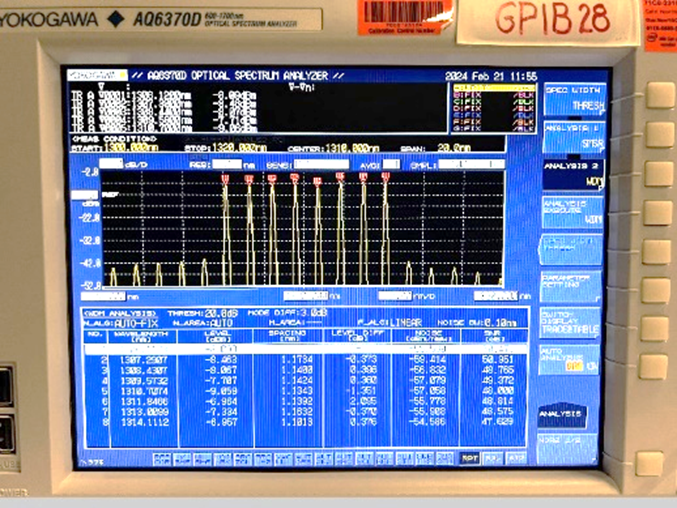 圖4 OCI發射器:在一條標準單模光纖上的八波長光學頻譜
圖4 OCI發射器:在一條標準單模光纖上的八波長光學頻譜
OCI是實現AI普及的關鍵
OCI是將晶片I/O從電轉向光的關鍵技術。這次展示重點介紹了英特爾如何利用其晶片製造、光學、封裝和平台整合能力,為業界提供完整的下一代運算解決方案。
英特爾經過驗證的矽光子技術和平台,可以提供最高性能和最可靠的光學連接解決方案,使無處不在的人工智慧成為可能。
(本文作者任職於英特爾)