嵌入式電腦視覺系統與人類的視覺系統非常相似,可對來自各式各樣產品的視訊進行擷取和分析,並執行與人類視覺系統相同的視覺功能。特別是智慧型手機、數位相機和可攜式攝錄影機等裝置的開發人員,皆須在有限的尺寸、成本和功耗條件下提供較高性能,透過視覺演算法識別場景中的物體,然後產生一個比其他圖像區域更重要的圖像區。例如,物體和人臉偵測可用於增強視頻會議體驗、公共安全檔案管理,以及基於內容的檢索和許多其他領域。
視覺辨識系統可對圖像進行剪裁和調整尺寸,以便適當地將圖像放在人臉中心。在本文中,將以偵測數位圖像中人臉與剪裁選定主要人臉當作應用實例(圖1),並將調整尺寸到固定尺寸輸出圖像。
 |
| 圖1 人臉偵測應用 |
由於視覺辨識可應用在單一圖像或在視訊串流上,並且其系統設計是可執行即時運作,因此只要人們把焦點集中在行動產品上的即時人臉偵測,就可實現即時輸送量。在本例中,開發人員提出了在可編程向量處理器上執行即時人臉偵測應用的部署步驟,這些步驟可應用在任何行動產品上執行類似的電腦視覺演算法。
導入可編程向量處理器 人臉智慧辨識應用有譜
由於需要更多的處理步驟才能完成物體的偵測和區分,因此電腦視覺演算法的記憶體系統設計極具挑戰性。由於19×19畫素大小的人臉圖形可能的灰度值組合就有256361種,所以需要極高的三維空間,基於人臉圖像的複雜性相當高,明確描述人臉特徵具有一定的難度,因此建立以統計模型為基礎的方法相當重要。此一方法係將人臉區域視為一個圖形,通過對許多人臉和非人臉樣本的訓練來建構分類器(Classifier),然後藉由分析偵測區域的圖形來確定圖像是否包含人臉。
人臉偵測演算法須克服的其他技術挑戰還包括姿態角度、結構性部分、人臉表情、遮擋、圖像取向(Image Orientation)及成像條件。雖然在許多的文獻中已介紹過各種的人臉偵測演算法,但是,只有少數的演算法能夠滿足行動產品的即時限制性。雖然很多人臉偵測演算法皆具有高偵測率,但是,由於手機、平板等行動產品在計算和記憶體方面的限制,很少有演算法能滿足行動產品對即時性的要求。
通常人臉偵測演算法的即時執行是在中央處理器(CPU)較強大和記憶體容量較大的PC電腦上執行。針對現有人臉偵測產品的檢視顯示,Viola和Jones在2001年推出的演算法已經廣為業界所採用,可讓採用基於外表的方法(Appearance-based Method)以即時方式運行,同時還可保持相同或更高的準確度。
此一演算法利用簡單特徵的增強級聯(A Boosted Cascade of Simple Features),並可分為三個主要部分:首先是積分圖(Integral Graph),用於快速特徵評估的高效卷積(Convolution);其次是使用用於特徵選擇的Adaboost,並按照重要性順序來篩選它們。每個特徵可作為一個簡單的分類器使用;第三是使用Adaboost來了解將最不可能包含人臉的區域濾出的級聯分類器。圖2是分類器級聯的示意圖,在圖像中,大多數子圖像並不是人臉的實例。
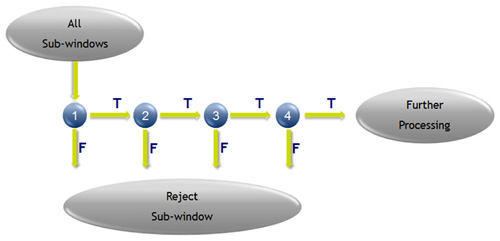 |
| 圖2 分類器級聯架構 |
在人臉偵測演算法的第一級,利用被稱為積分圖像中間表示(Intermediate Representation)可很快算出矩形特徵。如圖3所示,點(x,y)的積分圖像值是上部和左部所有畫素的總和,D區域內畫素的總和可以計算為4+1-(2+3)。
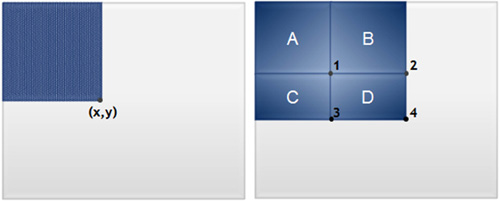 |
| 圖3 利用積分圖像對矩形特徵進行快速評估示意圖 |
為了在嵌入式產品上執行即時人臉偵測應用,需將指令級並行性和資料級並行性相結合為高級並行性(High-level of Parallelism)。超長指令字(VLIW)架構能夠實現高級並行指令處理,提供擴展的並行性及低功耗。
單指令多資料(SIMD)架構能夠在多資料元素(Data Element)上運行單指令,從而縮短代碼長度並提高性能。使用向量處理器架構時,可藉由加法器或減法器並行數量因數,加速積分和的計算。如果向量暫存器可載入16畫素,而且這些畫素可同時加到下一向量,那麼加速因數則是16,顯而易見,為處理器增加類似的向量處理單元可以讓此一因數倍增。
在下一個人臉偵測階段,圖像可從多重位置及按多種尺度掃描。採用Adaboost的強分類器(以矩形特徵為基礎的分類器),以決定搜索視窗是否包含人臉,以彰顯向量處理器同時將多個位置資料與臨界值進行對比的技術優勢。
事實上,若設計人員可提供的並行比較器越多,加速則越快。例如,多加速器的架構設計能在一個週期中比較八個元素中的兩個向量的能力,且排除十六個位置的子圖像僅需一個週期。為了簡化資料載入,並有效率利用向量處理器載入與儲存,各個位置可以在空間上彼此接近。
解決記憶體頻寬不足 資料分塊技術露鋒芒
記憶體頻寬不足與成本過高是臉部辨識應用未來想普及的最大瓶頸。由於臉部辨識應用的資料量較大,視頻串流無法儲存在緊耦合記憶體(TCM)中,例如一個YUV4:2:0格式的高畫質幀占用了3MB資料記憶體,這種高記憶體頻寬導致功率損耗更高,並需更昂貴的記憶體,從而使成本更高。一個完美的解決方案是採用資料分塊(Data Tiling)儲存畫素,其中二維資料塊在單次突發中由DDR存取,大幅改善記憶體效率。直接記憶體存取(DMA)可在外部記憶體和核心記憶體子系統之間傳輸資料。在最終人臉偵測應用階段,包含偵測人臉的子圖像尺寸重新調整到固定的尺寸輸出視窗。
當圖像在多個比例掃描時,圖像尺寸調整過程也在偵測階段使用。尺寸調整演算法廣泛應用在影像處理,用於視頻放大和縮小,人臉偵測應用中執行的演算法是雙三次演算法(Bi-cubic Algorithm)。三次卷積插值(Cubic Convolution Interpolation)根據離規定輸入座標最近的16畫素的加權平均值確定灰度值,並將該值分配給輸出座標。首先,在一個方向上執行四個一維三次卷積,然後,在垂直方向執行更多的一維三次卷積。這意味著要執行一個二維三次卷積,而所需的是一個一維三次卷積。
向量處理器內核具有強大的載入與儲存能力,能夠快速、有效存取資料,其中演算法在資料區塊(Blocks of Data)上運行。在單週期中從記憶體存取二維記憶體區塊的能力,可滿足尺寸調整演算法的優化。這一特點使處理器能有效實現較高記憶體頻寬,不須載入不必要的資料或執行資料操作的負荷計算單元。除此之外,能夠在資料存取期間轉置資料且沒有任何週期損失,這使得轉置的資料區塊能夠在單一週期中存取,對於執行水平過濾和垂直過濾非常切實可行。
在一個週期中載入4×8位元組區塊,然後每個反覆運算利用4個畫素在垂直方向執行三次卷積。如圖4所示,這4個畫素預先安排在四個獨立的向量暫存器中,因此,我們能夠同時獲得八個結果。然後,同時對這些中間結果進行準確處理,以轉置格式載入這些資料,從而完成水平過濾。為了保持結果的準確度,需要四捨五入值和後移(Post-shift)初始化,且篩檢程式配置應當在不要求專門指令的條件下實現這些特徵。
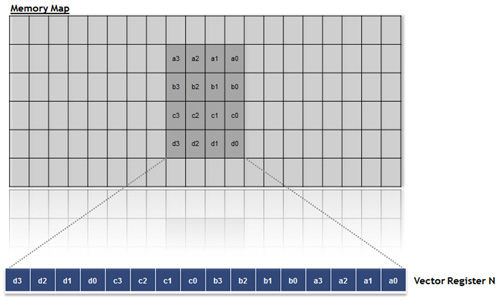 |
| 圖4 載入4×4區塊的畫素 |
總之,並行向量處理解決方案核心可在載入與儲存單元操作和處理單元之間實現平衡。一般而言,資料頻寬限制與晶片處理單元的成本限制了向量處理器執行效率;不過,卻可以實現純量處理器架構的加速。
可編程多媒體平台助陣 臉部辨識系統效能倍增
為實現視覺辨識應用,開發人員可利用可擴展且完全可編程的多媒體平台(Fully Programmable Multimedia Platform)整合到系統單晶片(SoC)中,處理1,080p具60fps視頻解碼和編碼、影像處理(ISP)功能和視覺應用。該平台由串流處理器和向量處理器組成,且整合到一個完整的多核系統中,包括本機記憶體和共用記憶體、周邊設備、DMA和與連接到外部匯流排的標準橋接器,能夠輕易滿足行動產品和低功耗要求。
向量處理器包括兩個獨立的向量處理單元(VPU)。VPU負責所有的向量計算,包括向量間運算和向量內部運算。向量間指令可在16個8位元或8個16位元上運行,可使用向量暫存器對,形成32位元元素,VPU具有在單週期中完成6個分接頭(Tap)中八個並行濾波器能力。
VPU可作為向量處理器的運算主力,而向量載入和儲存單元(VLSU)則可作為從資料記憶體子系統、向量處理器與資料記憶體子系統傳輸資料的工具。VLSU具有適用於載入和儲存操作的256位元頻寬,並支援不對齊(Non-aligned)存取,且備有在單週期中存取二維資料區塊的能力,並支援不同容量的資料區域。
為了簡化VPU任務,在讀寫向量暫存器時,VLSU可靈活操作資料結構。在資料存取期間,資料區域可轉置,且不會有任何週期損失,能夠在單週期中實現轉置資料區域的存取。轉置功能可動態設定或清除。採用此一方式,水平篩檢程式和垂直篩檢程式可重複使用相同的功能,從而節省每個篩檢程式的開發和除錯時間,同時縮小程式在記憶體中所占用的位置。
未來高複雜度的視覺辨識演算法需求將會繼續增長,採用新一代高整合度多媒體平台方案則可以讓裝置有效執行如具備裁剪和尺寸調整功能的人臉偵測等應用,協助系統設計人員開發出更便捷的嵌入式產品。
(本文作者任職於CEVA)