人工智慧/機器學習(AI/ML)應用快速成長,使得資料中心網路面臨顯著增加的資源需求。訓練具有數萬億個參數的大型語言模型(LLM)需要大量的AI加速資源,例如GPU,而GPU之間的資料傳輸效率也是訓練LLM的關鍵因素。
人工智慧/機器學習(AI/ML)應用快速成長,使得資料中心網路面臨顯著增加的資源需求。ChatGPT已迅速成為成長最快的應用之一,其核心技術,即大型語言模型(LLM),已在包括網路在內的多個研究領域引起了極大關注。
訓練具有數萬億個參數的LLM需要大量的AI加速資源,例如GPU。隨著LLM規模持續成長,同時摩爾定律(Moore's Law)逐步放緩,需要將GPU連接在一起,形成一個大容量GPU叢集,如輝達(NVIDIA)DGX SuperPOD[2],以滿足要求。在LLM訓練期間,必須執行隨機梯度下降法(Stochastic gradient descent, SGD)更新,並透過在GPU之間無縫傳輸資料以有效利用資料和模型平行性,進而在合理的時間範圍內實現運算密集的LLM訓練。這為資料中心網路技術帶來了極具挑戰性的任務。
GPU資料傳輸優化考量
我們需要解決的核心問題為:在分散式LLM訓練設置中,如何高效地將LLM工作負載資料從一個GPU傳輸至另一個GPU?
此核心問題可進一步分為下列幾個重要問題:
- 是否有可能開發一種通用的LLM工作負載路由機制,既能利用底層LLM叢集網路拓撲,又能夠相容於特定的專有互連技術(如NVLink和InfiniBand)?由於LLM工作負載是資料中心網路中相對較新的應用,並且具有獨特的網路互連技術和拓撲結構組合[2],首先需要利用LLM/DNN(深度神經網路)的獨特特性建立一個通用模型。
- 能否定義簡單的指標來捕捉流量狀況,以促進高效的路由決策?理想情況下,這些指標應能捕捉到GPU之間L2/L3資料流量的本質、具有通用性,同時又能隱藏內部專有拓撲結構,使模型具有通用性,而不會與特定供應商或當前LLM訓練設置的版本綁定。此外,資料轉發決策應以簡單為原則,不涉及即時繁重運算。此外,由於超頻寬域(Hyper-bandwidth Domain)(例如透過NVLink所建立的電路交換連接)和支援遠程直接記憶體存取(RDMA)的連接(如透過InfiniBand、RoCEv2或Ultra Ethernet所建立的連接)內的流量規律將不斷變化,此機制應具備動態調整能力。
- 是否可以設計一種機制,僅根據來源GPU和目的地GPU便決定整個系統的最佳端到端路由決策?或者,同時也需要依賴中間其他元件,進而要求在Hop-by-hop的基礎之上做出局部最佳路由決策?
本文提出了一個通用網路模型,該模型具有為資料中心量身打造的通用路由指標,適用於LLM訓練。該模型建立在透過優化軌道(Rail)相互連接的高頻寬GPU Domain之上,利用整體分散式注冊表(Global Distributed Registry)來收集和分配每個Domain的正規化(Normalized)流量健康分數和所有Rail的健康分數排序列表,接著利用這些分數來有效計算網路路徑流量分數。
此外,也為每個GPU引入了健康比率指標,有助於僅根據來源和目的地的健康比率來有效確定LLM流量路由決策。研究發現,從源頭到目的地的最佳路徑只取決於來源的比率指標是否大於目的地,而不考慮其他中間節點,這有助於在GPU之間高效地進行AI流量路由。
此方法可應用於不同類型的LLM流量,包括域內流量(Intra-domain Traffic)、同軌流量(Same-rail Traffic)和跨軌流量(Across-rail Traffic),並進一步擴展了該機制,使其能夠在局部Rail發生壅塞情況時,決定利用遠端Rail進行流量路由的最佳方式。
Rail-only連接拓撲架構助陣
下文討論中,將使用稱為「純軌道連接(Rail-only Connections)」的底層網路連接架構作為參考網路拓撲(該架構細節詳見參考資料[2])。Rail-only連接拓撲由麻省理工學院(MIT)和Meta的研究人員提出,該架構針對資料中心的LLM訓練工作負載進行優化。此研究結果也可擴展至傳統資料中心網路解決方案所支援的胖樹(Fat-tree)Clos資料中心網路架構。
Rail-only連接拓撲結構中(圖1),具有M個高頻寬Domain,每個Domain包含K個具有高速任意互連(如NVLink/NVSwitch)的GPU和K個Rail交換器。每個Rail交換器(簡稱Rail)連接每個Domain內具有相同序號(稱為Ranking)的M個GPU。
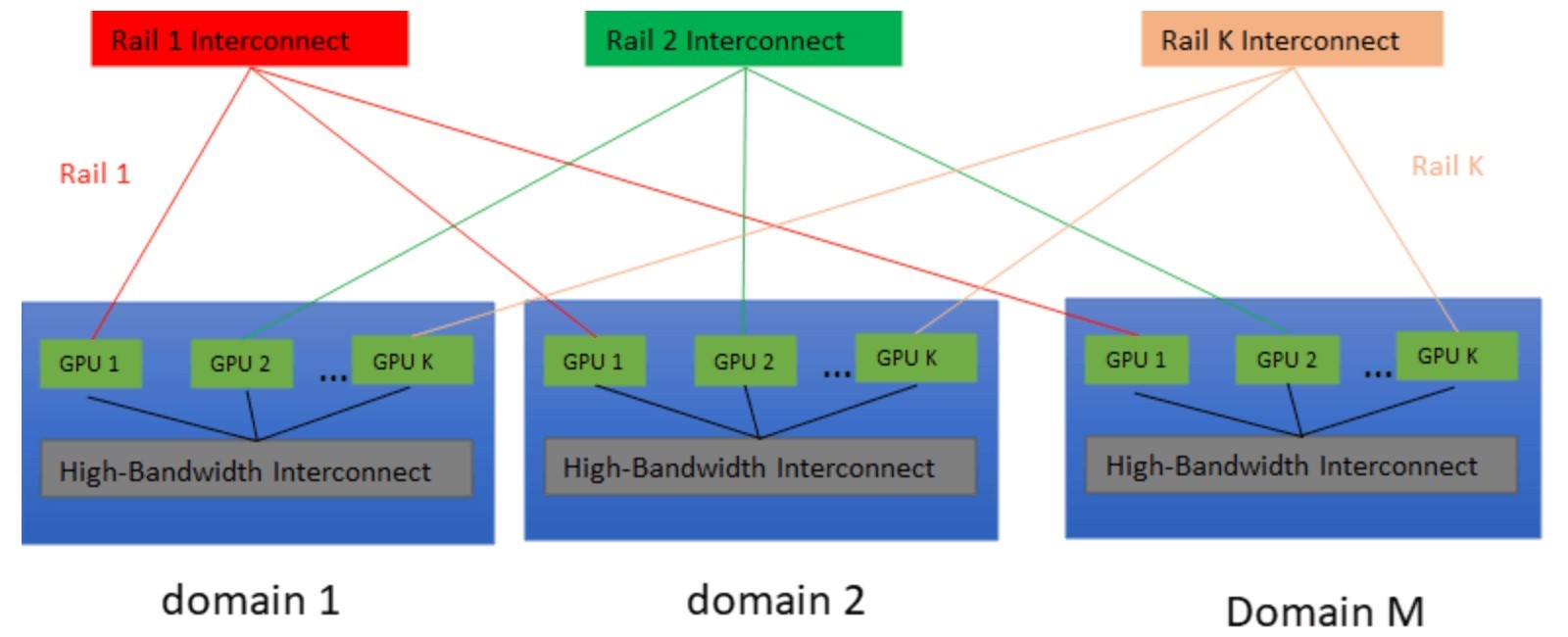 圖1 採用Rail-only連接架構的LLM叢集
圖1 採用Rail-only連接架構的LLM叢集
G(d, g)代表d Domain中的第g個GPU。為了支援採用SGD更新和平行化策略的分散式DNN訓練和推理(Inference),每個GPU都有兩種類型的網路連接:一種稱為「d-介面」,用於促進高頻寬Domain內的任意(Any-to-any)互連;另一種稱為「r-介面」,是支援RDMA並連接至Rail交換器的網路介面卡(NIC)。此研究目標是在GPU之間高效地移動LLM工作負載,旨在解決以下問題:如何高效地將LLM流量從來源GPU G1(G(d1, g1))路由至目標GPU G2(G(d2, g2))?
下文將在從簡單到複雜的多種情況下解決此問題:
- 案例一:G1和G2位於相同的Domain之中,即d1=d2。在這種情況下,只需要使用G1的d介面來實現高頻寬互連(圖2中的黃色流量)。
- 案例二:G1和G2位於不同Domain,但在同一條Rail上,即g1=g2。在這種情況下,通常可以使用G1的r介面將流量路由至G2(圖2中的綠色流量)。
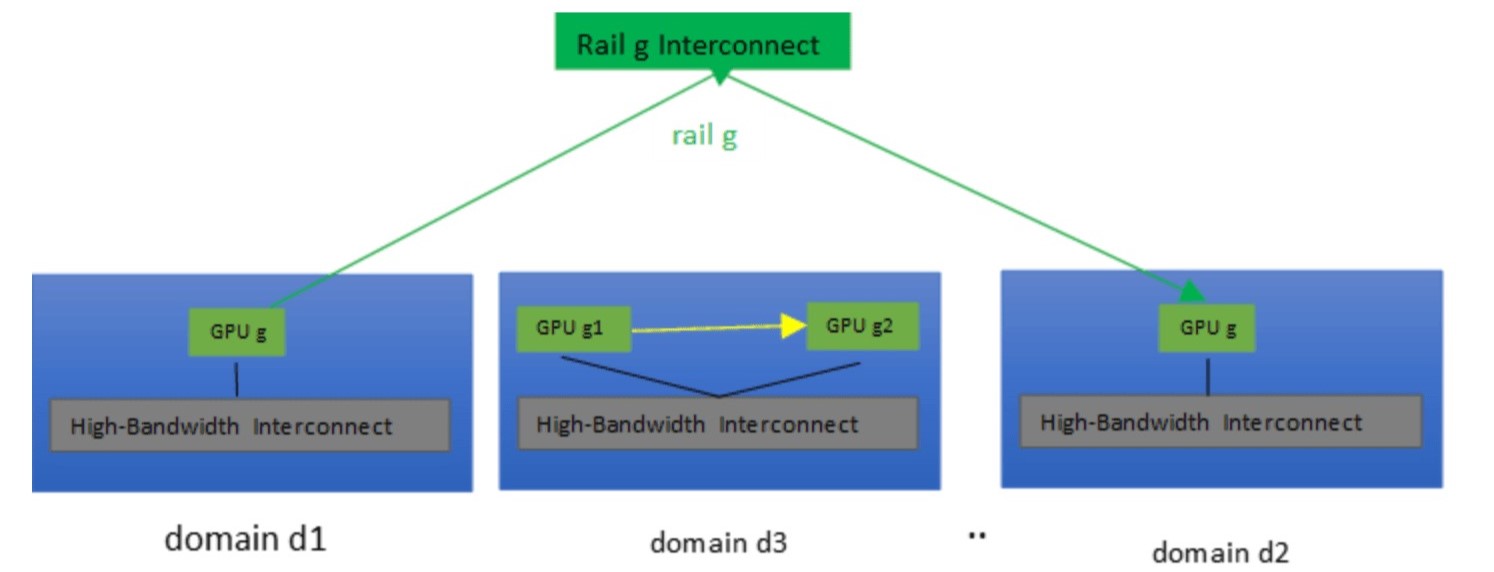 圖2 GPU(d1, g)和GPU(d2, g)之間的同Rail流量(綠色)VS GPU(d3, g1)和GPU(d3, g2)之間的域內流量(黃色)
圖2 GPU(d1, g)和GPU(d2, g)之間的同Rail流量(綠色)VS GPU(d3, g1)和GPU(d3, g2)之間的域內流量(黃色)
- 案例三:G1和G2位於不同Domain、不同Rail上。這種情況會有些麻煩,從G1到G2至少需要兩次跳躍(Hop)。可以先使用d介面,將流量路由至同一Domain d1內的G(d1, g2),接著再使用r介面抵達G2。此路徑稱為dr路徑(圖3);或者,也可以使用r介面將流量路由至Domain d2中的G(d2, g1),接著使用d介面抵達Domain d2中的G2。此路徑稱為rd路徑(圖4)。
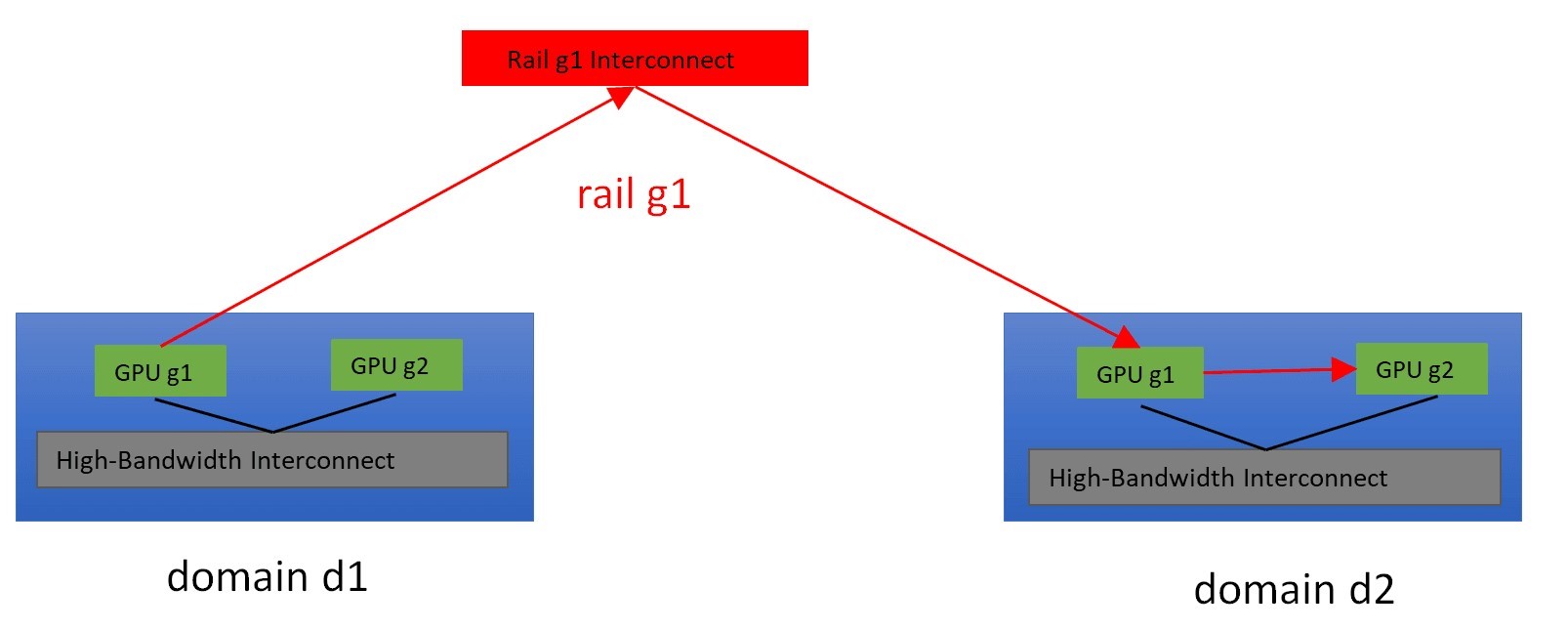 圖3 透過Rail g1,將GPU流量從GPU(d1, g1)路由至GPU(d2, g2)
圖3 透過Rail g1,將GPU流量從GPU(d1, g1)路由至GPU(d2, g2)
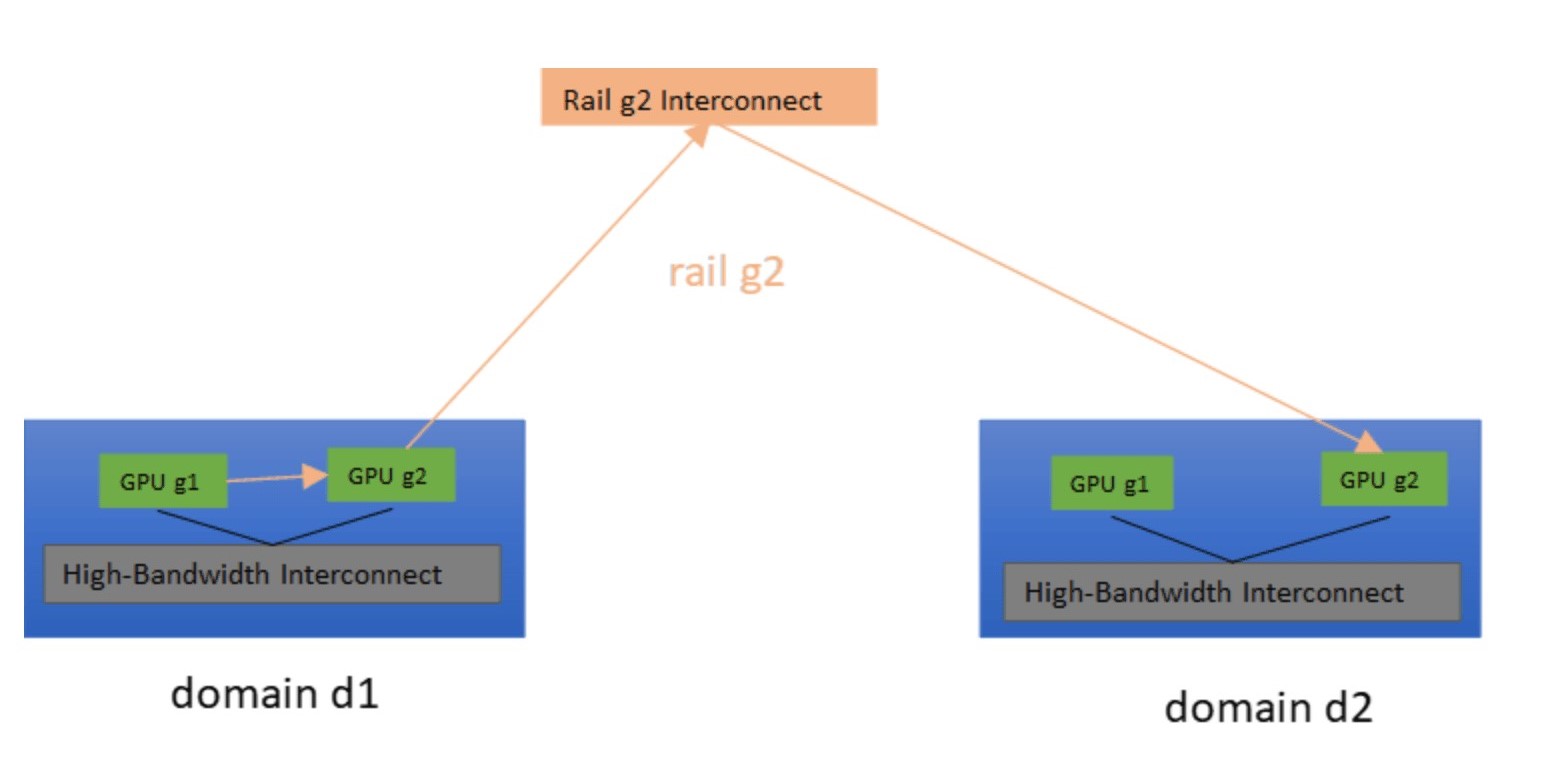 圖4 透過Rail g2,將GPU流量從GPU(d1, g1)路由至GPU(d2, g2)
圖4 透過Rail g2,將GPU流量從GPU(d1, g1)路由至GPU(d2, g2)
採取何種路由方式取決於LLM叢集內的動態流量情況。下文將介紹一個LLM叢集流量情況模型,捕捉和更新流量條件,創建高效的LLM工作負載路由機制。
首先,將介紹幾個用於表示LLM叢集內元件流量狀況的指標。對於LLM Domain或Rail,這些指標被稱為「流量健康分數」或「健康分數」,以H-score表示。H-score是0到100之間的整數值,其中100代表 100%健康,表示Domain或Rail並未發生壅塞情形,而0代表0%健康,表示相關元件完全堵塞。
找出最佳GPU傳輸路徑 路由機制提升AI/ML工作負載效率(1)
找出最佳GPU傳輸路徑 路由機制提升AI/ML工作負載效率(2)