多模態LLM整合不同資料模態,使AI具備更全面的理解力與表達力,多模態大語言模型是AI從語言理解邁向世界理解的重要里程碑,讓人工智慧從純文字邏輯推理,進化為能綜合理解視覺、語音與語意的泛用智能。
多模態大語言模型是新一代人工智慧系統,能同時理解與生成多種型態的資料,如文字、圖片、聲音、影片與感測訊號等。傳統大語言模型(如GPT-3)僅能處理文字輸入,主要透過大量語料訓練以掌握語言規則與知識;而多模態模型則整合不同資料模態,使AI具備更全面的理解力與表達力,能看、聽、說、寫並跨模態推理,例如由圖片生成文字。
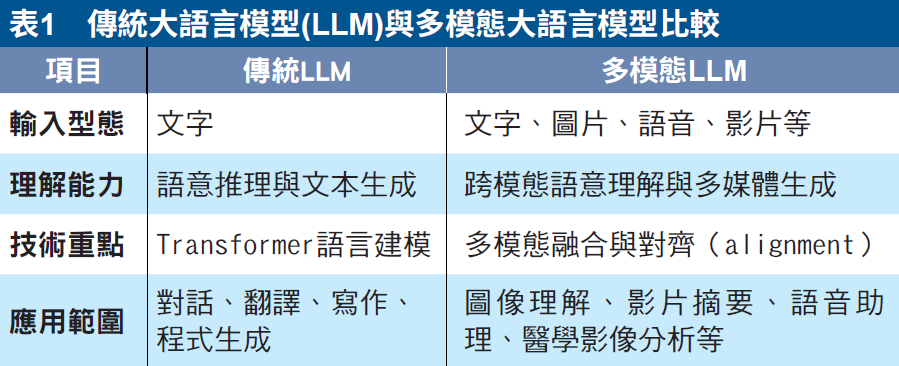
傳統LLM只能從文字推論,多模態LLM則能直接讀取圖片並回答(表1)。
多模態LLM的核心仍以Transformer架構為基礎,但加入了多模態編碼器(Encoder)與對齊機制(Alignment Module)(圖1)。
 圖1 多模態LLM運作流程
圖1 多模態LLM運作流程
其典型流程如下:
模態特徵抽取(Feature Extraction)
a.圖像由CNN或Vision Transformer提取特徵。
b.語音由聲學模型轉換為語音特徵向量。
c.文字經語言嵌入(Embedding)轉換為語義向量。
模態對齊(Alignment)
使用交叉注意力(Cross-Attention)或CLIP式對比學習,讓不同模態的語義空間對齊,使模型能理解圖像中的貓與文字的”貓”表示相同概念。
融合與生成(Fusion & Generation)
經過多層Transformer融合後,模型可生成文字描述、回答問題,甚至反向生成圖片或影片。
多模態LLM的應用極為廣泛,涵蓋:
・智慧助理與教育:能理解圖片、講解數學題、解釋圖表。
・醫療診斷:結合影像與報告分析輔助醫師判斷。
・創意生成:文字生成圖片、影片腳本設計。
・自動駕駛與機器人:透過視覺與語音多模態感知環境並決策。
・文件理解:同時閱讀文件文字與圖表內容,進行問答或摘要。
總而言之,多模態大語言模型是AI從語言理解邁向世界理解的重要里程碑,它讓人工智慧從純文字邏輯推理,進化為能綜合理解視覺、語音與語意的泛用智能。
技術重要性與影響
多模態大語言模型代表人工智慧技術的新里程碑,其整合文字、圖像、語音與影片等多種資料型態,讓AI具備理解世界的能力,而非僅止於語言處理。此發展不僅改變軟體技術架構,也深刻影響產業應用、生產模式與國家競爭力。
由軟體技術發展趨勢看,傳統AI多為單模態系統,例如語音辨識、影像辨識或文字生成各自獨立。多模態LLM則透過統一的Transformer架構與跨模態對齊技術(如CLIP、Vision Transformer、Speech Encoder),實現資料整合與知識共享。這代表軟體正邁向通用智慧平台化的時代,AI模型可同時理解語言與感官訊息,進而支援更多自然互動介面,如語音對話搭配視覺分析、圖像理解搭配文字生成。此趨勢推動軟體開發從任務導向走向模型驅動的生態整合。
對產業應用與經濟影響上,多模態LLM在各種產業中正加速應用落地。
- 在製造業,可自動解析監控影像與文字紀錄以預測設備異常;
- 在醫療領域,整合病歷與影像輔助診斷;
- 在教育與客服,能即時解釋圖表、影片或手寫內容,提供個人化學習輔助;
- 在創意產業,成為影像生成、影片腳本與多媒體內容創作的核心引擎。
這些應用顯著提升生產效率與創新能力,形成新的數位經濟基礎設施。
對社會的影響與挑戰上,多模態AI的普及將重塑人機互動模式,使AI更貼近人類思維與感知。然而,它也帶來倫理與資訊真實性問題,如假影像(Deepfake)與生成內容失真,可能影響社會信任與媒體生態。同時,大量視覺與語音資料的使用,也引發隱私與資料治理議題。未來社會需在創新與監管間取得平衡,確保AI的可控與負責任發展。
總結而言,多模態LLM不僅是AI技術的進化,更是驅動未來數位社會、產業創新與國際競爭的新核心力量,其發展將深刻改變人類理解與創造知識的方式。
虛擬運動復健教練
運動復健常見的挑戰是如何讓使用者持續進行,不要半途而廢;讓反覆單調的復健運動透過AI變得更生動有趣。資策會與醫材業者合作,運用生成式對話技術產生擬真人對話,以多模態LLM產生對話文字與場景圖片兩種模態的輸出。如同虛擬的運動復健教練,適時給予使用者激勵的話,幫助使用者完成訓練進度。
智慧長照訪視助理
資策會與地方政府衛生局合作開發智慧長照應用,運用手機或平板進行訪視錄音紀錄,上傳平台產生逐字稿並做訪視摘要。過程中發現如果只有訪視錄音逐字稿,會缺失很多資訊,透過多模態LLM的圖像能力來解析個案的評量表與藥單等影像資料,可以補充訪視逐字稿,大幅提昇AI生成訪視摘要的正確率與完整性。AI長照助理可提升行政與合規效率,錄音轉逐字稿節省整理時間。依據訪視單位各自不同工作重點,找出個案的需求,加速整理與完成時間
多模態大語言模型結合文字、影像、語音與影片等多元資料,使AI從單一語言理解邁向貼近人類感知的世界理解。透過跨模態對齊與融合架構,模型得以支援更自然的人機互動與複雜推理,並加速在製造、醫療、教育、長照與創意產業的落地應用,顯著提升效率與創新能力。未來,多模態LLM將成為通用智慧平台的核心,但同時需正視隱私、倫理與內容真實性治理,才能確保其永續且負責任的發展。
(本文作者為資策會軟體院副主任)