系統業者為打造更佳的嵌入式視覺應用產品,並同時滿足市場對功耗與產品上市時間的嚴格要求,正透過SoC FPGA元件與OpenCV函式庫強化視覺系統整體效能,並加速系統開發時程,提升產品市場競爭力。
電腦視覺技術近幾年已發展為一個相當成熟的科學研究領域,目前許多視覺演算法皆源自於數10年前的研究成果,但一直到最近電腦視覺技術才快速滲透到日常生活的各個面向,例如無人駕駛車、體感遊戲機、智慧型自動吸塵器,以及可利用手勢操作的手機和其他各式視覺應用產品。
然而,現今系統業者所面臨的挑戰是如何有效建置更佳的視覺系統,同時滿足功耗與產品上市時間的嚴格要求。有鑑於此,若設備業者利用可編程(Programmable)的系統單晶片(SoC),並結合開放原始碼電腦影像視覺函式庫--OpenCV和高階合成技術(HLS),即可實現硬體加速的關鍵函數,這樣的組合能為設計和採用智慧視覺(Smart Vision)系統提供有力的操作平台。
事實上,嵌入式系統已無所不在,但礙於運算功能的局限性,尤其是在處理大型圖片和高幀率時運算能力的不足,導致會大幅限制嵌入式系統在電腦或機器視覺技術的應用。影像感測器的技術發展,如同為嵌入式裝置打開探索世界的眼界,產品開發人員可利用電腦視覺演算法與環境互動,打造操作體驗更佳的解決方案。
圖像資料日益龐大 視覺系統開發難度高
嵌入式視覺技術的應用包含在運算平台上運行智慧電腦視覺演算法。對許多用戶而言,只要使用標準的桌上型運算處理平台,即可完成這項任務。然而,對高度嵌入式產品而言,一般的運算平台就無法滿足此一需求。因為這類的產品往往須擁有體積小、高效率與低功耗等特色,還要能處理龐大的圖像資料集。
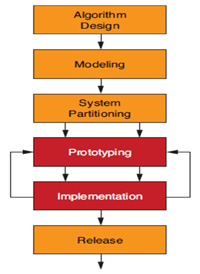 |
| 圖1 嵌入式視覺系統開發流程 |
圖1為一般設計人員開發嵌入式視覺應用的流程。演算法設計是整個流程中最重要的一環,在執行特定的電腦視覺工作時,它將決定設計人員能否達到訊號處理與品質的要求。首先,設計人員在MATLAB等數位運算環境中搜索演算法選項,以執行高階的處理選項。一旦確定了適當的演算法,設計人員會使用C/C++等高階語言來為演算法建模,以便快速執行,並滿足最終高精細度建置的需求。
系統磁碟分割是開發過程中的重要步驟。設計人員透過演算法效能分析,可決定須對演算法的哪些部分進行硬體加速,進而處理代表性輸入資料集(Representative Input Data Sets)的即時要求。此外,對目標平台中的整個系統進行原型設計,並測量對效能的預期值也是相當重要的一環。一旦從原型設計過程中觀察到該設計已達到所有效能和品質的要求,設計人員就能在實際的目標元件中建置系統。最後一步才是在各種環境測試晶片上的設計能否順利運行,一切檢查完成後,設計團隊就能正式發布產品。
導入SoC FPGA元件 嵌入式視覺系統效能躍升
在機器視覺開發應用過程中,設計團隊需要一個功能強大、能滿足一般用途處理的運算平台,以支援多種不同的軟體生態系統,並具備數位訊號處理功能,以執行須龐大運算處理與高效能記憶體的電腦視覺演算法。由此可知,晶片內的高度整合對實現高效能和完整的系統非常重要。
本文以賽靈思(Xilinx)All Programmable SoC--Zynq為例,此為以處理器為中心的元件,在單晶片上提供軟、硬體和I/O可編程設計。Zynq SoC在單一元件中整合了雙核心安謀國際(ARM)Cortex-A9 MPCore處理系統、現場可編程閘陣列(FPGA)邏輯和關鍵周邊元件。如此一來,Zynq SoC即能協助設計人員實現極高效能的嵌入式視覺系統。
相較於採用個別獨立元件設計而成的系統,新一代SoC FPGA高度整合處理子系統、FPGA邏輯和周邊元件,能提高資料傳輸速率、降低功耗和材料清單成本。設計人員能運用SoC FPGA實現即時處理支援1,080p60影像序列的系統,達到每秒數千億次運算的處理功能。
為了全面利用SoC FPGA的諸多功能與特性,賽靈思推出了以IP和系統為中心的設計環境--Vivado設計套件。該套件可加速整合和建置,幫助設計人員提高生產力,進而靈活地開發出更具智慧型的嵌入式產品。套件當中的Vivado HLS元件能支援設計人員採用C/C++語言開發的演算法編譯成為暫存器傳送級(RTL)程式碼,並在FPGA邏輯元件中運作。
Vivado HLS工具非常適用於嵌入式視覺設計。在設計智慧視覺系統流程中,設計人員可先利用C/C++編譯演算法,再以Vivado HLS將全部或部分的演算法編譯為RTL,進而確定哪些函數適合在FPGA邏輯上運作,以及哪些函數更適合在ARM處理器上運作。透過此流程,設計團隊能善用最佳化效能,打造能在SoC FPGA上運行的視覺系統。
為了進一步闡述嵌入式視覺開發人員如何開發Smarter Vision系統,FPGA業者在OpenCV電腦視覺演算法函式庫中新增對Vivado的支援,並推出了最新IP整合器工具和SmartCORE IP以支援此類設計。
提高嵌入式系統效能 OpenCV函式庫角色吃重
OpenCV函式庫提供設計人員一個演算法試驗和快速原型的設計環境。此一設計框架獲得多平台的支援,但在許多情況下,要提高函式庫對嵌入式產品的效率,就要在嵌入式平台上加速滿足即時效能的例行性需求。
雖然OpenCV在設計階段即考慮到運算效能的問題,但礙於其傳統運算環境,OpenCV仍支援多核心處理。這類運算平台對高度要求效率、成本和功耗的嵌入式應用而言,或許不是最佳的選擇。
OpenCV是一款經BSD授權發行的開放原始碼電腦影像視覺函式庫,亦代表其可免費應用於學術和商業範疇。OpenCV最初設計的主旨在提高各式多處理系統的運算效率,並著重於即時性的應用。此外,OpenCV還提供C/C++和Python等多種程式設計介面。
開放原始碼計畫的優勢在於使用者能持續改進演算法,並將演算法的擴展應用延伸至多種不同領域。目前使用OpenCV可執行兩千五百多種函數,其中包括矩陣數學、公用設施和資料結構、通用影像處理功能、圖像轉換、圖像金字塔、幾何描述符號函數、識別、萃取和追蹤特性、圖像分割與調整、攝影鏡頭校準、立體化、3D處理、機器學習偵測與識別。
利用HLS加速OpenCV函數
一旦劃分了嵌入式視覺系統架構的分區,找到需要最多運算處理的部分,HLS工具仍能在使用C++語言編寫的環境中加速函數。Vivado HLS將會運用C、C++或SystemC代碼產生高效能的RTL執行方案。
此外,Vivado設計環境中以IP為核心的設計提供了豐富的IP SmartCORE處理範圍,此系統能簡化圖像感測器、網路及其他必要I/O介面的連接網絡,簡化在OpenCV函式庫中執行函數的程序。在其他方案中,即是最基本的OpenCV I/O功能都有加速的需求,這點相較於其他執行方案具備明顯的優勢。
Vivado HLS是一款軟體編譯器,旨在將使用C、C++或SystemC編寫的演算法轉變為使用者自行定義的時脈頻率以及FPGA元件中最佳化的RTL。以解釋、分析與最佳化C/C++程式方面而言,Vivado HLS與x86處理器的編譯器具備相同的核心技術基礎,而這樣的相似性有助於從桌上型電腦開發環境能夠快速地透過FPGA實現。在設定好目標的時脈頻率和元件後,用戶無須輸入參數,Vivado HLS就會預設產生RTL執行。
此外Vivado HLS與其他編譯器一樣,具有不同的最佳化層級。由於演算法的最終執行目標是客製化的微型架構,因此Vivado HLS可達成的最佳化層級比傳統的編譯器具備更高的精細度。針對處理器軟體設計的傳統O1?O3最佳化理念已被架構研究指令所取代,當以上要求與用戶的技術能相結合時,即可透過Vivado HLS打造出色的執行方案,一舉滿足運算法對於功耗、占用的面積和效能表現的要求。
四階段一氣呵成 視覺系統設計超省時
圖2所示為HLS編譯器的使用者設計流程。以概念面而言,使用者提供C/C++/SystemC的演算法描述,編譯器就能產生RTL執行。程式碼轉化成為RTL的過程分演算法規格、微型架構探索、RTL執行和IP封裝等四個階段。
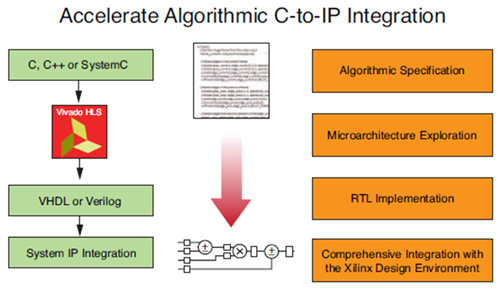 |
| 圖2 高階合成設計流程 |
演算法規格階段意指針對FPGA架構的軟體應用開發,該規範可在標準桌面軟體發展環境中,完整利用FPGA業者提供的軟體庫(如OpenCV)進行開發。除支援以軟體為中心的開發流程外,Vivado HLS還提升了從RTL到C/C++驗證抽象化的速度。使用者能用原軟體進行全面的演算法功能驗證。透過Vivado HLS產生RTL後,產出的設計將會與傳統軟體編譯器產生的處理器彙編代碼類似,使用者亦可以選擇性地在彙編代碼過程中除錯。
雖然Vivado HLS能處理幾乎所有其他的軟體編譯器的C/C++代碼,但代碼也有所限制。在使用Vivado HLS編譯代碼到FPGA的過程中,使用者代碼不能包含任何運行中的動態記憶體配置。與採用單一記憶體架構演算法的處理器相比,不同之處在於FPGA擁有具備特定演算法的記憶體架構。透過分析陣列和變數的使用模式,Vivado HLS能確定哪些實體記憶體布局和記憶體類型將最能符合演算法的儲存和頻寬要求。此分析工作的唯一要求就是在C/C++代碼中須明確描述演算法所使用的所有記憶體陣列。
從C/C++轉化為最佳化的FPGA的第二步就是微型架構探索。在這一階段,設計人員可運用Vivado HLS編譯器的最佳化功能來測試不同的設計,以尋求合適的面積和效能組合。設計人員可在毋須修改原始程式碼的情況下根據不同效能特點實現相同的C/C++代碼。
Vivado HLS編譯器流程的最後階段為RTL執行與IP封裝。這是Vivado HLS編譯器中自動執行的步驟,使用者並不須要具備RTL方面的知識。在此階段,為滿足各式需求,FPGA業者提供了經過全面測試與驗證的按鈕式程式,能產生由時序FPGA架構驅動的RTL。Vivado HLS編譯器能夠利用賽靈思工具(如IP-XACT)以自動封裝的形式產生成果,因此毋須進行其他操作,即可在Vivado中使用HLS生成的IP核。
OpenCV函式庫為Vivado HLS設計流程的最佳化提供了捷徑。函式庫在預先特性化描述後能夠提供1,080p解析度的畫素處理功能,而如何使Vivado HLS編譯器最佳化的細節也已內建在函式庫中。如此一來,設計人員就能夠快速地將桌面環境中的OpenCV概念應用程式與在SoC FPGA上運作的OpenCV應用程式之間反覆運算,兩者皆可在ARM處理器和FPGA架構上操作。
自動化圖像分析建功 視覺演算法品質有保障
如圖3所示,此為OpenCV中開發的動態偵測應用流程。該設計的目的就是透過比較當前幀與先前幀的方式,去偵測視訊串流當中的動態物體。演算法的第一階段為偵測前後兩幀影像的邊緣。資料縮減運算(Data-reduction Operation)便於分析連續影像的相對變化。
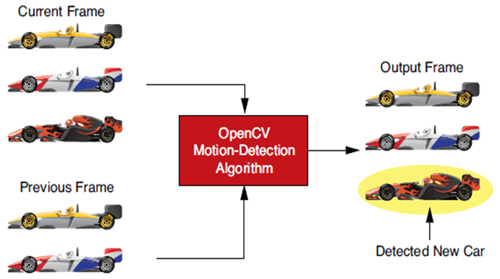 |
| 圖3 在OpenCV演算法函式庫中執行動態偵測 |
影像邊緣的資訊擷取出來後,透過邊緣比對可以偵測在當前影像中出現,偵測出來的新邊緣則構成動態偵測遮罩影像。
在上述應用中,可透過在動態偵測遮罩影像中採用7×7中值濾波器來降噪。中值濾波器的主要概念就是取7×7相鄰觀察窗的中值,然後將中值做為觀察窗的最終值進行輸出。降噪後,動態偵測遮罩影像便與即時輸入的圖像結合,並以紅色強調動態邊緣。
如圖4所示,設計人員可完整執行採用SoC FPGA原始程式碼映對在ARM的子系統中的應用程式。執行過程中必要的硬體元素為Cvget-frame和Showimage函數,這兩個視訊I/O函數是採用FPGA架構中的賽靈思視訊I/O子系統。在Cvgetframe函數呼叫時,視訊I/O子系統的輸入端負責處理所有細節,包括從高解析度多媒體介面(HDMI)介面擷取並解碼視訊串流,再把畫素資料存入DDR記憶體。
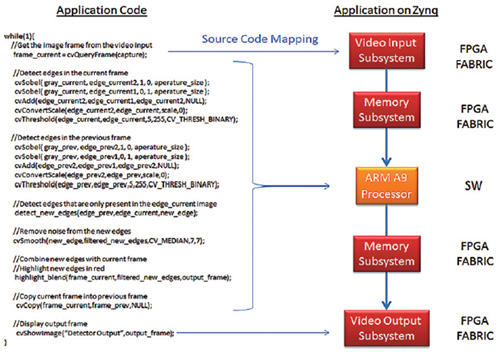 |
| 圖4 在採用ARM處理器的Zynq SoC上進行動態偵測 |
Showimage函數呼叫時,該子系統負責將畫素資料從DDR記憶體傳輸到影像顯示控制器,以啟動電視機或其他符合HDMI標準的影像顯示裝置。
經Vivado HLS最佳化,並加速支援硬體的OpenCV函式庫,能將圖4當中的代碼移植到FPGA架構中的每秒60幀即時畫素處理管線中。OpenCV函式庫能為須硬體加速的OpenCV元素提供基本功能;若硬體沒有加速,也就是如果僅在ARM處理器中運行所有代碼的話,該演算法效能僅能達到每13秒1幀。
圖5顯示Vivado HLS經編譯後的全新應用程式映對。請留意原本系統的影像I/O映對是可以重複使用的。在此之前於ARM處理器上執行的演算法運算內核,現在則可編譯到多個Vivado HLS產生的IP中;而這些組塊連接到Vivado IP Integrator中的影像I/O子系統,並針對每秒60幀、1,080p的影像處理進行最佳化。
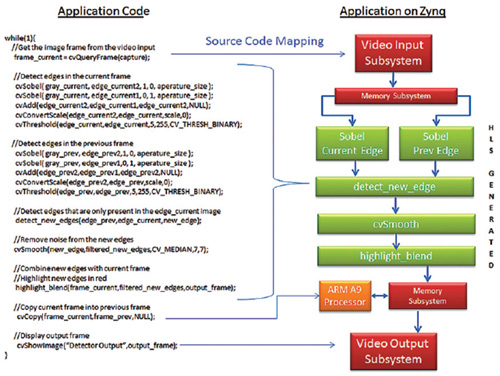 |
| 圖5 透過可編程Fabric技術在SoC FPGA上進行動態偵測 |
綜上所述,SoC FPGA和Vivado設計組合所提供的可編程環境,非常適合用於嵌入式視覺系統的設計、原型設計和測試,並以最新高解析度影像技術所要求的高速資料處理速率運行。採用OpenCV中的開放原始碼函式庫是在開發時間很短的情況下,達成高標準電腦視覺應用的最佳選擇。由於OpenCV函式庫採用C++語言來編寫,因此設計人員使用Vivado HLS所建置的原始程式碼能有效轉換為SoC FPGA架構中的硬體RTL,成為方便易用的處理加速器,且不影響OpenCV最初設定充滿靈活性的設計環境。
(本文作者皆任職於賽靈思)