當前製造領域趨之若鶩的預測性維護,比起傳統的計畫性維護有著諸多優勢,但在邁向規模化的路程上易因複雜性與需求定義不明確而受阻。因此,可從建立不同層級的需求,以及國際業者應對的五大方向著手,進而實現高生產效益的預測性維護。
當前許多製造業者依賴預測性維護(Predictive Maintenance, PdM)偵測機器是否「生病」。預測性維護可偵測機器或設備的狀況,並判斷機器是否即將發生錯誤或故障。
預測性維護固然重要規模化不足瓶頸來臨
透過機器與機器的互相連結(Machine to Machine, M2M),機器會產生大量的參數,如電壓、電流、溫度、振動和轉速,並透過機器學習演算法分析數據意涵,試圖減少停機時間並提高資產價值。
不過當前許多企業也發現,單條產線,或是單一工廠執行預測性維護或許不難,但要擴及到其他廠房,甚至整個集團時,卻面臨難以規模化的挑戰。
高資產敏感度產業對預測性維護需求最大
對於資產敏感度高的產業而言,預測性維護的出現無疑帶來革命性的改變。
以石化產業而言,壓縮機是石化製程中最關鍵的設備,石化廠壓縮機跳機損失動輒以數千萬元起跳,而氣體的可壓縮性造成跳機時危險性相對較高,因此傳統作法為繁複檢查設備狀況;但是,若機具狀態並未出現異常就恰逢定期排程而進行保養,亦會造成保養成本的增加以及機具生產率的下降。
如何維持降低保養成本與增加機具生產率的平衡成為業者重要議題。而預測性維護的導入,一方面可避免危險性跳機,同時可以使停機時間縮短,將誤判跳機降至最低,提高生產效能與工安環境,進一步拉抬公司的資產報酬率(ROA)。
專案規模化面臨多重考驗待克服
傳統企業所使用的為計畫性維護(Schedule-based Maintenance, SCM),其重點在於減少故障並最終替換本來可以使用更長時間的機器,其重心在於計算折舊年限與最大使用率,這種物盡其用的方式雖然符合成本考量,但歷經長久使用的機器卻因容易出現停機風險,而導致更大的成本代價,因此需要更換維護方式。當然,預測性維護對企業而言確實有相當吸引力,不過在導入時遭遇的挑戰也不少,根據市場調研機構麥肯錫的全球調查指出,業者在將預測性維護規模化時常見的問題如下:
1.廠內感測器數量不足導致資料量不足或難以取得,加上資料品質不高,導致分析結果不佳。
2.IT系統過度老舊,傳統架構無法應對新的算力與演算法需求,使用者介面不易操作,降低運作效率。
3.在PdM專案中沒有設定階段性任務,難以定義預測性維護的優先順序,不知道從哪種設備的維護開始,造成資源錯置。
4.缺乏資料科學人才,或是資料科學人才對領域知識不熟,無法建立出符合需求的預測模型。
5.經濟報酬率不高,由於情境確認、資料分析到每一次模型部署上線,企業內部就需花費大量的時間溝通,而等到模型上線後,又因為使用情境需求改變,甚至是日益成長的資料而讓模型執行環境變得不堪使用。
6.規模化時容易遇到「模型數量暴增」、「機器學習團隊溝通協作不易」,和「模型準確率隨時間下降」。一個模型開發時程可能需要一年,維護校正時間需要半年,如果同時超過1,000個模型要維護,對企業負擔非常龐大。
建立不同層級的預測性維護有助於釐清業者需求
上述問題還僅是訪談中整理出最容易出現的狀況,實際上在執行專案過程中可能還有成千上萬的問題要克服,企業在執行PdM規模化專案時,需用系統化、有層次的方式進行。由於PdM的範圍涵蓋全公司所有機器設備,因此將PdM按照技術複雜度、執行成本,以及覆蓋範圍分成不同階段有助於專案推行(圖1)。
 圖1 企業可將PdM專案分成四大階段
圖1 企業可將PdM專案分成四大階段
資料來源:麥肯錫
多數的預測性維護上處於1.0至3.0的階段,大型電子製造業、汽車產業、自動化工業都已經具備3.0的水準;傳統產業如紡織、化工與食品則處於1.0至2.0階段;許多中小型企業還在1.0努力掙扎,甚至布局可被預測性維護的條件。至於4.0的案例則相當稀少,原因在於4.0需要成熟的領域知識、人才、技術模型與完整的資料結構,因此僅發生在單一產線與特定應用情境中,距離實際規模化仍有相當大的差距。不過,在分析過歸納成功案例時,仍然可以統整出可行做法(表1)。

從國際業者案例整理成功專案共通處
此外,若觀看西門子、博世(Bosch)、富士通、戴姆勒等大型業者,可發現這些業者在導入大型預測性維護專案時,通常具有下列共通點。
(一)大量投入資料科技
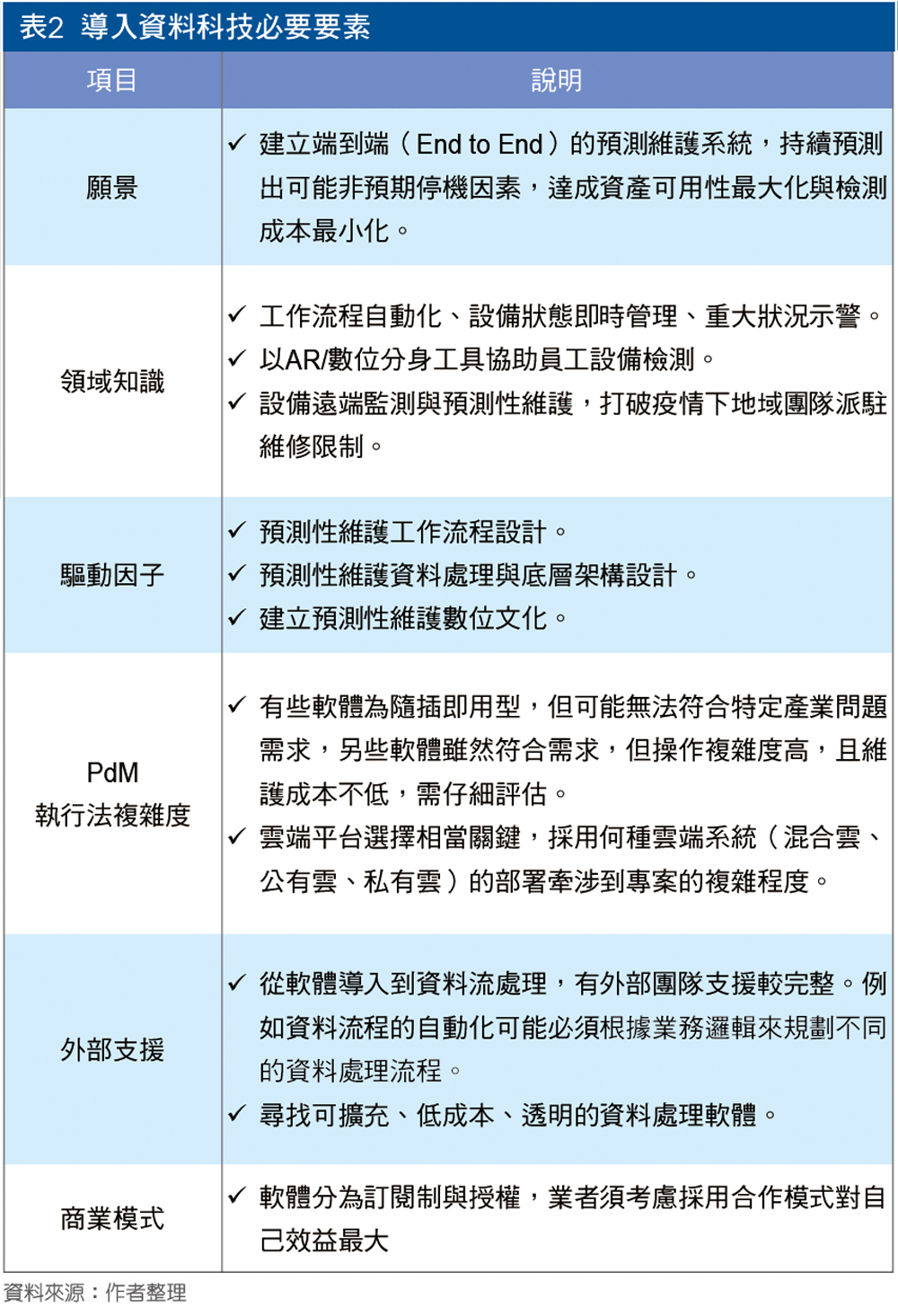
未來的工業市場的規則,將來自於對於資料或資訊的掌握,其中最主要的關鍵來自於由於無所不在的物聯網裝置所產生的資料、與其分析或所產生的價值。各種物聯網的垂直應用都牽涉到端、網、雲、系統整合,雖然其中的關鍵技術方向大致一致,然而其中細部的需求會依據各種垂直應用情境而有所不同,如感測元件,可區分為健康感測與環境感測,其規格需求明顯大不相同。這些業者大量投入在資料科技應用,如演算法必須應用於多個機械設備上,機械設備資產會和多個邊緣裝置相連結,邊緣裝置再連結到基於雲端、機房、或兩者並行的IT/OT系統,串連出完整的資料流(表2)。
(二)使用先進故障排除法
在資產設備維護中,常見的使用方法有事件觸發型維護法(Condition-based Maintenance, CBM)與先進故障排除法(Advance Troubleshooting Method, ATS)。兩者差異在於資料的使用方式。事件觸發型維護法通常從資料中找出原先設定的停機/資產受損狀況,在處理例行性問題時相當有效,但遇到突發狀況時反而無法反應,常用在中低價工具機檢測。而先進故障排除法善用歸因分析找出問題,效率較事件觸發型維護法高,但由於偵測突發狀況時需要工程師立即修復,因此公司必須提早準備好各種零件,考驗公司採購反應與物流配送能力,否則很容易提前預知問題卻缺乏對應零組件維修,通常用於高單價設備,如雷射切割機、飛機引擎等。
(三)建立完整的預測性維護夥伴關係
預測性維護採集的資料點越多、資料的價值越大、模型越精密,則橫向整合的能力越強,因此,許多企業紛紛強化預測性維護模型的開發。但是,越複雜的技術越需要大量資源支援,以建模而言,機器學習「建模」流程可以分成資料取得、資料預處理(資料清理、特徵工程)、模型最佳化(參數最佳化與結構最佳化)、到模型實際部署(進行預測與模型解釋),這些流程耗費大量時間與資金,因此難以由公司內部人力單獨完成,因此,身為資料的使用者,這些製造業者通常仰賴下述幾種角色協助。
.資料應用服務業者
所需擁有的能力包括資料收集(從資料供應端取得連結與存取,並將多個資料源做初步結合)、準備(彙整多個資料供應端到單一資料集並做最佳化處理)、分析(從資料萃取出知識)、視覺化(提供統計圖表來反應分析結果以有效溝通知識)、存取(資料儲存與存取管理)等各種因應資料加值應用服務開發所需的資料加值應用能力。
.資料應用工具供應商
隨著資料加值應用發展的蓬勃與複雜,開始有專業分工之需求,因此資料生態系已逐漸發展出各種因應加值應用需求所衍生的資料應用工具開發商,包括資料平台建置、資料分析服務、資料交易仲介、資料視覺化呈現。
.機器學習模型服務商
近年來低程式碼(Low-code)與無程式碼(No-code)的興起大幅降低建立分析模型的成本,這些所謂的AutoML技術目前已在科技業逐漸往其他產業擴張,由於許多產業人士對AI掌握度不高,提供AutoML服務業者(如AWS、Google、SAS)有效解決該問題,透過建模過程中自行寫程式碼、分析各種方法論的作業時間,即便領域專家不具資料科學相關背景,也能根據使用情境應用機器學習模型。這種把資料科學工程外包的方法開始受許多製造業者歡迎。
在不同合作夥伴的分工與協作下,業者甚至可以進一步發展出預測性平台商業模式,建立有彈性、可擴充,以及可互通性的生態圈,進行跨產業、跨領域、跨系統的預測性維護服務,串連技術與產業的供需兩方,發展維護資料交易服務。資料交易與流通已成創新應用開發成功與否的重要關鍵,若能建構具公信力且交易機制可行之資料市集服務營運模式,可望創造出另一個全新服務模式,讓單一企業功能服務化,替業者帶來第二金流。
(四)持續給予團隊時間與改善空間
建立預測模型雖然耗費公司相當資源,但完成後也僅是專案開始的第一步而已,持續性的改善為必要之舉。後疫情時代下的製造業者在預測性維護專案的投入上通常分成兩大子項目。
.精確率改善
模型建立之初可能蒐集到不精確的資訊導致預警判斷錯誤,造成許多不必要的困擾(False-Alarm),常見解決方法為:減少特徵數量,或使用較少的特徵資料組合,增大劃分的區間;交叉檢驗,透過交叉檢驗得到較優的模型引數;增加新特徵,可以考慮加入特徵組合,增大假設空間等。隨時修正模型參數與模型再調整,直到產出最適合的預測模型。
.召回率改善
召回率的高低對模型影響相當大,舉例而言如果將壞資料當成好資料,這樣後續可能發生的瑕疵機率會遠超過願先預期,造成產線嚴重損失。召回率越高,代表實際壞資料被預測出來的概率越高。
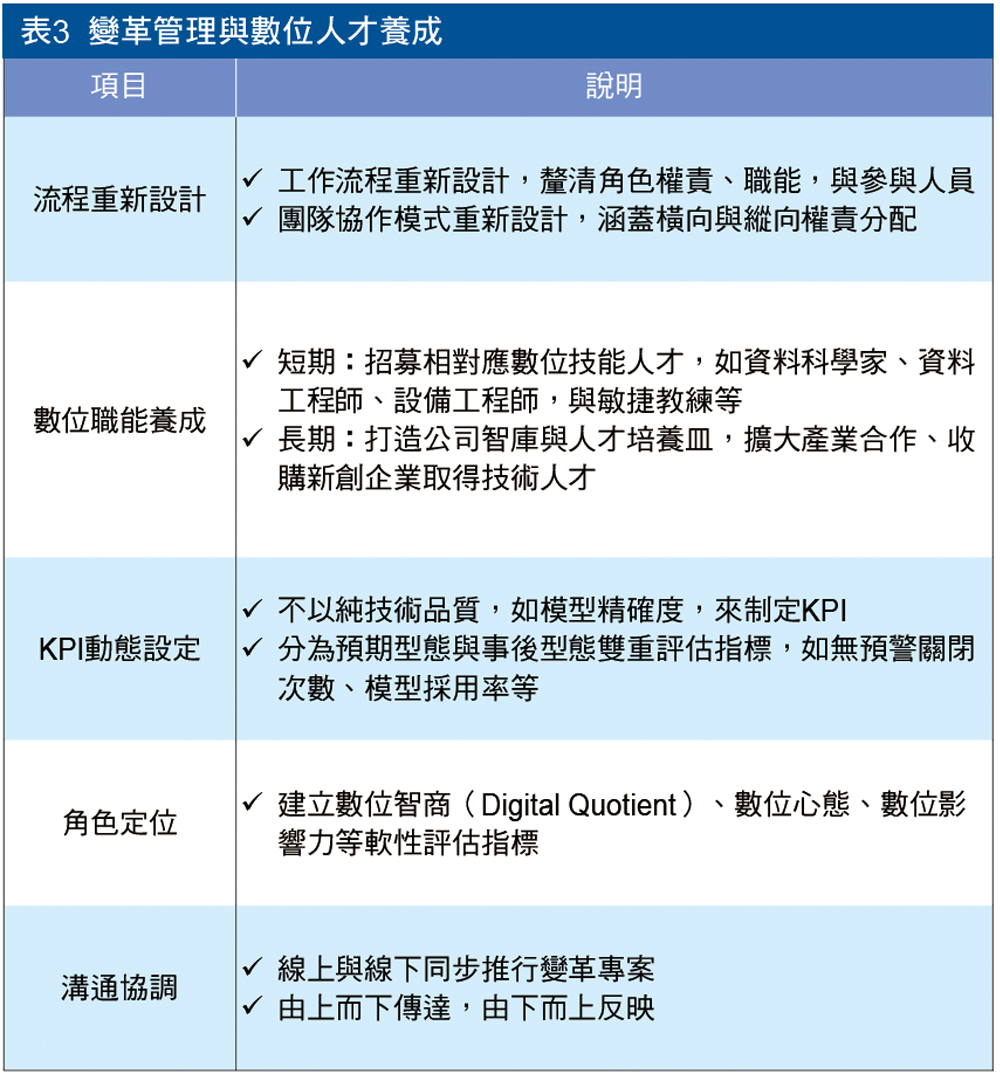
(五)數位人力養成與變革管理
預測性維護要規模化其中一大挑戰之一是人,越大規模的專案參與人數越多,加上由於新專案通常帶來技術與組織協作的變革,參與者面臨的不確定性也就越高。由於預測性維護牽涉到不同團隊協作,責任分工與角色定位是專案中容易產生衝突的地方;同時,人才如何儲備、培養、訓練、留任也牽涉到專案完整度。
新的數位技能也牽涉到KPI的重塑,舉例而言,如何衡量資料科學家的KPI為許多業者的痛點,以模型精確度來衡量難以設定績效評估時程,因為模型何時不精確、何時要校正、校正後誤差值怎樣算最小,都難以設定對應的時間軸。
同時,KPI制定過度環繞在目標上容易造成業務失焦,反而不利於整體專案的進行,多數公司採用遊戲化積分的方式動態衡量專案成效,但仍有很大進步空間(表3)。
雖許多製造業者雖已經擁有大量設備與製程數據,但往往很難從中獲取價值,因為他們缺乏可以提出數據看法並加以解析的資料科學家,以及相對成熟的機器學習模型。
因此如何打造一個數位生態系,納入IoT與AI技術,以及採用自動化AI/軟體解決方案為當前業者積極部署的領域。另一不可或缺的技術為雲端平台,透過雲端的即時分析,將原先基於時間的維護設定轉變為預測性維護。隨著雲端的規模的不斷擴大,業者可以在無接觸(Contactless)的狀態下遠端對感測器組進行遠端更新和維護,這些技術部署都有賴於生態系的建立與夥伴的支援。
將預測性維護融入數位生態系
此外,良好的預測性維護生態系也有助於供應鏈整合,由於製造業的資料可分為兩種裝置資料與營運資料。但營運資料涉及企業內部經營資訊,通常企業並不希望進行資料共享,但裝置資料就不一樣了,若上中下游之間願意共享部分裝置資料,且克服預測性維護中採集哪些資料,如何安裝感測器,如何選擇採集頻率和週期等領域知識與技術問題,也許可以從設備狀況判斷廠商備料、產能,甚至出貨時間等資訊,將可能更有效率服務產品終端使用者,提高供應鏈的運作效率。