繪圖處理器(GPU)已普遍應用於各種電子產品,比方說在個人電腦、智慧型手持裝置、數位電視、車用導航設備及遊戲機等產品裡均可見其影子,其中又以智慧型手機與平板電腦最具代表性。
舉例來說,智慧型手機提供豐富華麗的視覺感受,間接改變人們使用手機的習慣。而華麗的顯示畫面與流暢的3D遊戲動畫,更決定了智慧手持裝置產品的競爭力,背後的關鍵即在於繪圖處理器。
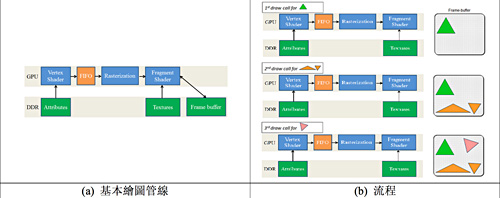 |
| 圖1 立即式渲染架構示意圖(a)與基本繪圖管線流程(b) |
目前繪圖處理器的繪製架構大致可分為兩種。一種統稱為立即式渲染架構繪(Immediate Mode Render, IMR),如圖1(a)所示;另一種則是區塊式渲染架構(Tile Based Render, TBR),如圖2(a)所示。
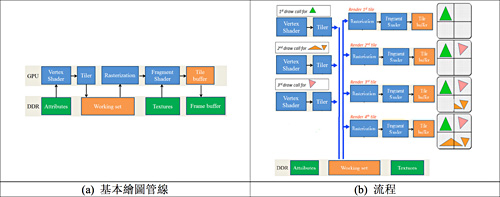 |
| 圖2 區塊式渲染架構示意圖(a)與基本繪圖管線流程(b) |
記憶體耗用量低 行動裝置多採區塊式渲染架構
立即式渲染架構是指當繪圖處理器收到一個繪圖命令(Draw Call)時,會立即將它處理完畢,該繪圖命令與其相關的資料進入嵌入式繪圖處理器的繪圖管線中,經過頂點處理(Vertex Shader)、繪製三角形(Rasterization)及像素處理(Fragment Shader)等運算過程後,直接渲染這個三角形,並輸出結果到畫面緩衝區(Frame Buffer)之上。
如圖1(b)所示,一張畫面被分成三個繪圖命令,繪圖處理器接收到第一個繪圖命令後,就直接渲染並輸出到畫面緩衝區。當繪圖處理器接收到第二個繪圖命令,並直接渲染到畫面緩衝區,此時就可以從畫面緩衝區看到繪圖處理器處理渲染第二個繪圖命令的成果。
同樣地,當繪圖處理器接收到第三個繪圖命令,並直接渲染到畫面緩衝區,此時就可以從畫面緩衝區看到這三個繪圖命令的成果。
如圖2(a)所示,區塊式渲染架構的繪圖命令先經頂點處理器處理後,會再經過區塊分類(Tiler)模組;另外,Tiler模組事先會把畫面分割成大小相等的區塊,在Working Set內建立區塊命令緩衝區。
當繪圖命令經過Tiler模組時會計算此繪圖命令影響到多少的區塊,同時把該繪圖命令與其相關的資料存到有影響到的區塊命令緩衝區。等累積到一個畫面的繪圖命令後,再逐一針對各區塊所涵蓋的繪圖命令進行後續的繪製三角形、像素處理等繪製運算,渲染這些區塊。
如圖2(b)所示,一張畫面被分成三個繪圖命令,畫面被分成四個區塊。繪圖處理器接收到第一個繪圖命令後,經過頂點處理器與Tiler模組之後,就把此繪圖命令與其相關的資料存到左上方區塊的區塊命令緩衝區。
當繪圖處理器接收到第二個繪圖命令,經過頂點處理器與Tiler模組之後,就把此繪圖命令與其相關的資料存到左下方區塊與右下方區塊的區塊命令緩衝區。
同樣地,當繪圖處理器接收到第三個繪圖命令,此繪圖命令與其相關的資料存到右上方區塊的區塊命令緩衝區,之後才開始針對左上方、右上方、左下方及右下方區塊的次序,逐一去區塊命令緩衝區抓取繪圖命令與相關資料,並進行後續的繪製三角形、像素處理等繪製運算,渲染這些區塊。
事實上,立即式渲染架構與區塊式渲染架構各有所長。立即式渲染架構通常有較好的繪製效能,而區塊式渲染架構由於可以在快取記憶體(On-chip Cache)上完成一個區塊的像素處理動作,因此通常有較低的記憶體耗用量。
由於區塊式渲染架構需要的內部記憶體較小,目前手持裝置裡的繪圖處理器幾乎都採用區塊式渲染架構,而個人電腦為了效能通常採用立即式渲染架構。
區塊式像素消除技術可節省頻寬
動畫或遊戲都會有場景的設計,人或物會在這個場景中進行射擊、移動等等的動作,等完成一段任務後就換到下一個場景。通常在一個場景中,人或物在動,但場景不動。
以Android遊戲--憤怒鳥做實驗,在Aiming階段,兩個連續畫面相對位置的區塊,有96%的區塊像素資料是相同的。在Bird in flight階段,相對位置的區塊約有一半的區塊像素資料是相同的。
而在Setting階段,雖然一開始變動很大,相對位置的區塊的區塊像素資料相同的不多,但後來穩定後,相對位置的區塊的區塊像素資料相同的就愈來愈多了。
表1是使用繪圖處理器模擬--ATILLA分析數個遊戲的資料,也能發現兩個連續畫面相對位置的區塊的區塊像素資料有許多是一樣的。另外使用十個流行的Android遊戲做實驗,數據如圖3所示,高達四成的像素在兩個連續畫面上是一樣的。
 |
| 圖3 連續畫面的像素資料相同的比例,平均42.72%。 |
從以上的觀察發現,兩個連續畫面相對位置的區塊像素資料是相同的,甚至有出現兩個連續畫面是一樣的。因此如何從兩個連續畫面找出相同的區塊像素或像素,成為最近業者設計行動裝置繪圖處理器的考量,並紛紛提出區塊式像素消除技術或像素消除技術加入繪圖處理器的設計,以得到節省頻寬與整體能源使用效率。
不過不同公司有不同的考量,例如安謀國際(ARM)提出的交易消除(Transaction Elimination)區塊式像素消除技術目的在節省頻寬;工研院資通所提出的Parameter-Based區塊式消除技術,其目的為減少繪圖管線運算,進一步提升繪圖運算單元的效能。
此外,NVIDIA也利用此特性提出專利申請;英特爾(Intel)也發表了Hardware Memoization像素消除技術,以提高繪圖處理器整體能源使用效率。
交易消除技術
由於採用區塊式繪圖架構後,兩個連續畫面相對位置區塊有可能擁有同樣像素顏色,ARM提出的交易消除技術其想法是,如果能找出兩個連續畫面相對位置區塊是相同的,那麼就可以直接使用前畫面已繪製好在外部記憶體畫面緩衝區的區塊像素,從而節省區塊緩衝區搬移到外部記憶體畫面緩衝區的存入頻寬。
因此,交易消除技術使用一個特徵值緩衝區儲存每個區塊的像素特徵值(Signature),當完成一個區塊像素的渲染後,所有區塊像素資料會儲存在區塊緩衝區,在要把區塊緩衝區資料搬移到外部記憶體畫面緩衝區之前,先做目前這個區塊像素的特徵值,並比較目前區塊像素之特徵值,與前畫面相對應位置的區塊像素之特徵值。
若不同,則把區塊緩衝區搬移到外部記憶體畫面緩衝區;若相同,則直接使用前畫面已繪製好在外部記憶體畫面緩衝區的區塊像素,以節省匯流排流量和記憶體頻寬。
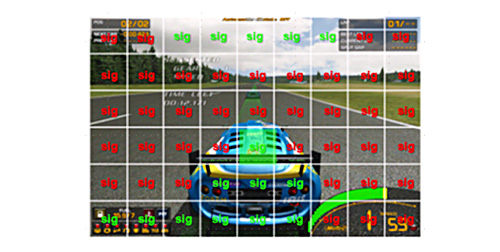 |
| 圖4 交易消除技術特徵值比較 |
範例如圖4所示,當前畫面可分成五十四個區塊。當前畫面每個區塊像素都會計算其特徵值,並與前畫面相對應位置的區塊像素之特徵值比較,若相同則用綠色Sig表示(有十四個區塊),不相同則用紅色Sig表示(有四十個區塊)。原本要做五十四次從區塊緩衝區搬移到外部記憶體畫面緩衝區的動作,現在只要做四十次,節省十四次的頻寬。
交易消除技術是Mali Midgard GPU架構的一項關鍵頻寬節約功能。圖5為交易消除技術應用於不同應用程式的節省頻寬比例,由於在使用者介面和休閒遊戲等許多常用圖形應用程式中,兩個連續畫面之間的像素資料大部分保持不變,因此交易消除技術帶來的頻寬節約最高可達75%以上。
 |
| 圖5 交易消除技術應用於不同應用程式的節省頻寬比例 |
以憤怒鳥遊戲來說,就可節省32%頻寬,繪圖處理器的標竿測試GFXBench Manhattan也可節省10%頻寬。
Parameter-Based區塊式消除技術
交易消除技術雖然在遇到兩個連續畫面相對位置的區塊資料不變時,可以節省區塊緩衝區到外部記憶體畫面緩衝區的存取頻寬,可是仍然須要執行繪圖處理器的所有運算,並沒有減少繪圖運算造成的延遲和能量。
若是能在繪圖管線結束之前,判斷出可替代之區塊,就能夠減少繪圖管線運算,進一步提升繪圖運算單元的效能。
要節省運算的第一步,是要能夠分辨出什麼情況下會繪製出兩個相同的區塊,分辨的依據就是每個區塊的渲染引擎輸入資料,對於輸入資料相同的區塊進而關閉剩餘的繪圖管線。由於輸入資料龐大,因此使用計算特徵值的方式。
在Tiler模組之後,用該區塊的渲染引擎輸入資料,例如頂點、貼圖及像素處理器程式計算出特徵值,並儲存在緩衝區。若能在這個階段就判斷出與前畫面相對位置區塊的特徵值差異,必定能夠減少後續繪圖運算造成的延遲和功耗,例如繪製三角形模組、像素處理模組等。
 |
| 圖6 特徵值判斷流程 |
取而代之的是直接使用前畫面已繪製好在外部記憶體畫面緩衝區的區塊像素,如此不但能減少繪圖管線運算,提升繪圖運算單元的效能,也能減少記憶體頻寬的使用量。
由於資訊量過於龐大,即使是將所有輸入資料計算成特徵值仍然不夠有效率。因此,將判斷的資料細分成數個類別並分別計算其特徵值,類別包括繪圖狀態、像素處理器程式、Uniforms、Varyings,以及貼圖五大類。
圖6為使用特徵值判斷的流程,先為第一類資料計算特徵值,通常第一類會選擇資料量較少的類別。例如繪圖狀態,若計算出的特徵值與前畫面不同,則將來會繪製出的區塊顏色也不同,因此此區塊會在繪圖管線內繼續被處理。如果特徵值相同的話,則繼續計算下一類別資料的特徵值並做比較。
若是第二類的特徵值也相同的話,則繼續計算第三類別資料的特徵值並做比較,這過程一直持續到五個類別的資料特徵值都比完為止。
若是五類特徵值的比較結果都是一樣,就關閉之後的繪圖管線,不再對此區塊進行處理,而直接通知外部記憶體去做複製的動作。表2為Parameter-Based區塊消除技術應用於OpenGL繪圖範例應用程式Triangle與Cube的區塊消除比例,平均約有70%以上的區塊可以重複使用前畫面的區塊像素資料。
NVIDIA區塊式消除技術專利剖析
NVIDIA區塊式消除技術的概念是使用二個緩衝區,第一個緩衝區儲存每個區塊繪圖命令(Command)的特徵值,第二個緩衝區儲存每個區塊像素的特徵值。第一個緩衝區應用於Tiler模組,而第二個緩衝區應用於像素處理器(Pixel Shader)模組。
由於區塊式渲染架構的繪圖命令先經頂點處理器處理後,會再經過Tiler模組,Tiler模組事先會把畫面分割成大小相等的區塊,在Working Set內建立區塊命令緩衝區。
當繪圖命令經過Tiler模組時會計算此繪圖命令影響到多少的區塊,同時把該此繪圖命令與其相關的資料存到有影響到的區塊命令緩衝區,等累積到一個畫面的繪圖命令後,再逐一針對各區塊所涵蓋的繪圖命令進行後續的繪製三角形、像素處理等繪製運算,渲染這些區塊。第一個緩衝區就是儲存區塊命令緩衝區的特徵值。
整個繪圖處理器的示意圖如圖7所示,左半部為基本的繪圖處理器管線,右半部為實施區塊式消除技術所新增的模組或緩衝區。第一和第二個緩衝區都是COMMAND SIGNATURE BUFFER。
 |
| 圖7 繪圖處理器的示意圖 |
當要執行渲染一個區塊之前,先比較當前區塊繪圖命令的特徵值與前畫面相對應位置的區塊繪圖命令的特徵值,若相同則直接跳過渲染階段,直接使用前一張畫面相對應位置的區塊像素資料,若不相同才針對該區塊進行渲染階段。
當決定要渲染一個區塊後,會先經過繪製三角形階段,再進入像素處理器。像素處理器就會進行渲染區塊內的每個像素,每渲染完一個像素,就會計算此像素的特徵值,當整個區塊內的每個像素都渲染完後,就會得到這個區塊的區塊像素特徵值,這個特徵值是儲存在第二個緩衝區。
與交易取消技術類似的概念,當完成一個區塊像素的渲染後,先比較目前區塊像素之特徵值與上一張畫面相對應位置的區塊像素之特徵值,若相同則不寫到外部畫面緩衝區,以節省匯流排流量和記憶體頻寬。
Hardware Memoization技術
不像之前的技術屬於區塊式像素消除技術,Hardware Memoization屬於像素消除技術。由於有可能連續兩張畫面或同張畫面上的像素是一樣的,如果能直接使用已渲染好的像素資料,就可以節省渲染像素資料的運算。
Hardware Memoization技術主要觀念為,若輸入是一樣的,那麼輸出也應該要一樣。像素處理器的架構圖如圖8所示,輸入項目有Input Reg. File、Constant Reg. File、Tex Sample、Shader Program;輸出項目則有Output Reg. File。
其作法是針對每個像素處理器的輸入項目做特徵值,之後建立一個表格Look Up Table(LUT),表格的內容包含(特徵值和Output Reg. File)。
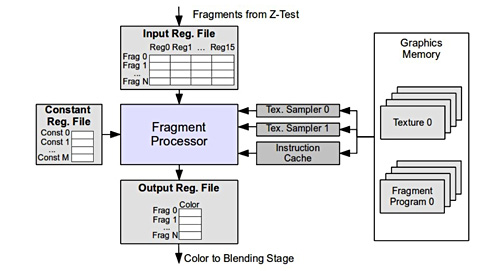 |
| 圖8 像素處理器的架構圖 |
當一個像素進入像素處理器時,像素處理器會同時進行渲染此像素與查詢LUT表格,由於一般渲染該像素需要六十個週期以上,但查詢LUT表格僅需六個週期,當從LUT表格找到相同的特徵值時,就會放棄原來渲染的動作,直接把LUT表格內的Output Reg. File當成此像素的輸出。
如此一來不但消除多餘的記憶體存取,也避免了多餘的運算。依據實驗數據,Hardware Memoization技術可以增進8.8∼30%效能,節能3.93∼15.84%。
繪圖處理器採用區塊式繪圖架構後,許多人陸續發現兩張連續畫面相對位置區塊會有同樣像素的特徵出現,為此紛紛提出區塊式像素消除技術或像素消除技術加入繪圖處理器的設計。
從這些實驗數據看來,這些區塊式像素消除技術或像素消除技術,不但可節省頻寬,也能提高整體能源使用效率。未來在設計嵌入式繪圖處理器時,這一特徵勢必得納入考量。
(本文作者為工研院資通所嵌入式系統與晶片技術組副組長)