Elon Musk在2020年7月表示有信心將於2020年底實現全自動駕駛level 5的基礎功能要求[1],又再一次掀起全球自駕車界的熱潮。
國內在經濟部推動無人載具科技創新實驗條例[2]下,自駕車也逐步在開放道路的離峰時段進行沙盒實驗試運行,引起不少民眾的好奇心與求知慾。由於目前國內對於自駕車偵測行人過馬路的行為預測與預警技術著墨較少,但工研院這幾年投入自駕研發與場域運行經驗,了解到行人行為預測之技術困難度與關鍵性,舉例來說,意圖過馬路的行人在路邊時,可能只露出個頭看有沒有車,亦或是行人過馬路之前的準備動作千百種,預測相當不容易;此外,少數行人會暴衝式過馬路,自駕車要閃避更是挑戰。因此本文將以聯網自駕巴士技術和行人過馬路的情境為主軸,介紹「影像物件偵測」、「行人行為預測」以及「預警煞車控制」等系統模組,並輔以「場域試運行」初步成果進行說明。
相機/光達深度學習物件偵測
現今相機物件偵測技術已相當成熟。相機感測器提供高解析度與色彩豐富的物件資訊,能有效偵測遠方小物件,精準辨識物件類別,在各項領域廣泛應用。但單目相機(Monocular Camera)未提供三維深度資訊,需結合其他深度感測器,限縮了相機感測技術於自駕車領域之可用性。近年自動駕駛技術採用光學雷達感測器(光達),雖相較於相機感測器,物件解析度較低,僅能偵測中短距離物體且類別辨識精準度較低,但能穩定感測環周物件原始資料於三維空間位置,較不受光影等天氣狀況所影響。如何有效利用相機與光學雷達之感測性特性,為近年自動駕駛團隊感知技術研發之一大挑戰。
工研院聯網自駕巴士搭載八顆相機與三顆光學雷達感測器,分別配置於車頭、車側以及車體後方,如圖1所示。為提供自動駕駛控制系統於道路上穩定轉向、障礙物繞行與煞停等功能,採用融合多感測器物件偵測方法,有效偵測道路物件,並大幅擴增車輛環周感測區域。詳細物件偵測之技術說明如下。
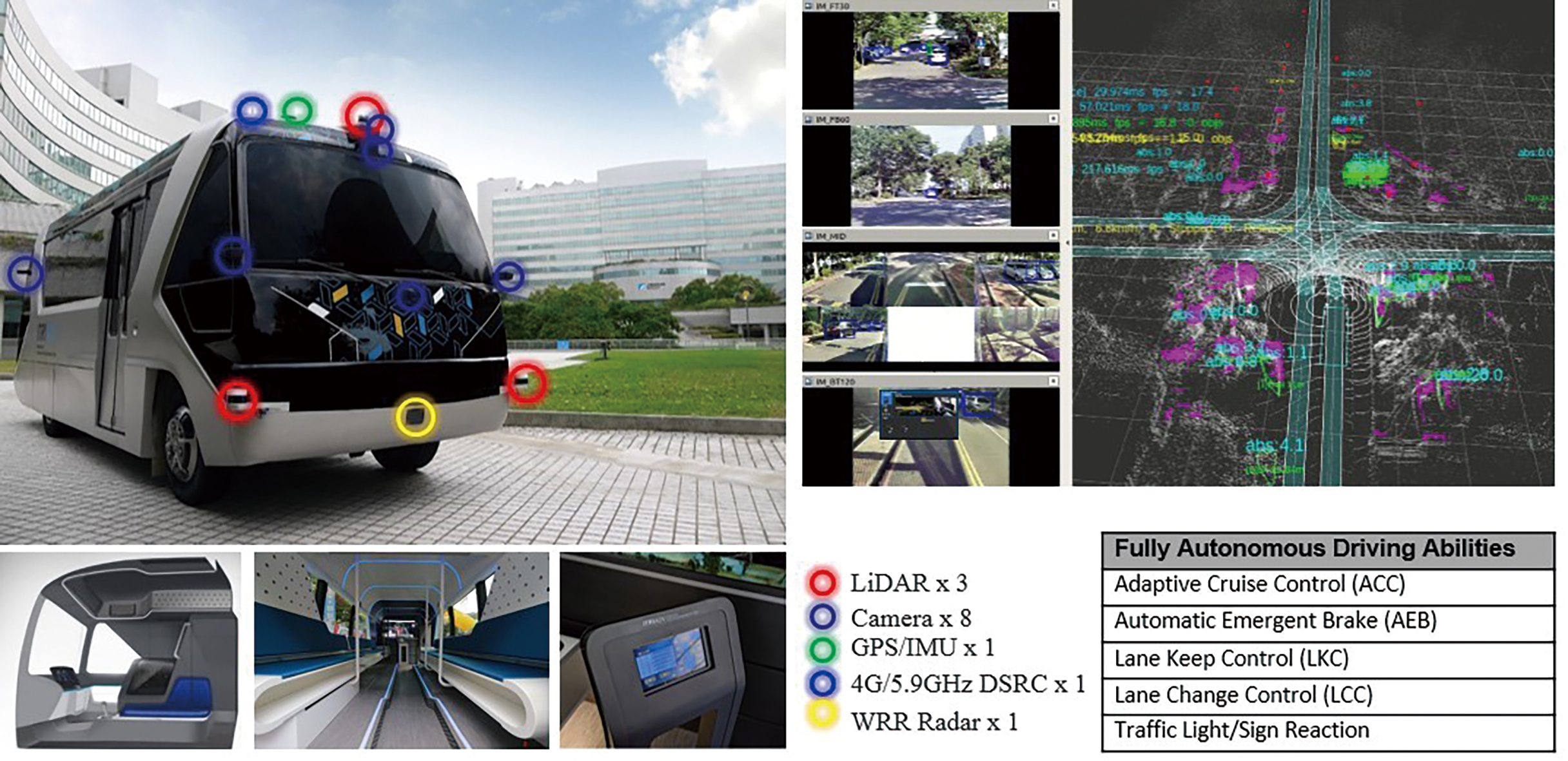 圖1 工研院聯網自駕巴士內外裝與感測器配置
圖1 工研院聯網自駕巴士內外裝與感測器配置
相機二維物件偵測(Camera 2D Object Detection)
為符合自駕車所需之即時性與高精準度,採用YOLOv3(You Only Look Once, version 3)[3]影像深度學習物件偵測技術,此方法能有效定位物件之二維座標,並精準辨別道路上物件,如行人、汽車、卡車、巴士、機車與腳踏車等類別。針對行人的偵測案例,因物件較小,當落於30~50公尺之區間,物件僅剩20~30像素。身體骨架與輪廓不清晰,辨識難度高。尤其轉彎路口常有電線桿或樹叢,行人僅露出二分之一至三分之一部份區塊。如何能維持穩定的辨識,且預測出完整二維物件框,是目前技術需持續努力的方向。
相機校正與三維座標系投影技術(Camera Calibration and 3D Projection)
相機與光學雷達分別有自己的座標系,影像要包含深度資訊即需透過投影轉換矩陣,將這兩個不同座標系的結果進行轉換。首先將車輛移動到空曠空間,透過校正板進行多感測器的資料蒐集,提供參考點計算影像與光達對應產生投影轉換矩陣[4]。經由工研院研發之即時投影轉換工具將光達點雲投影至影像上,確認點雲與二維物件對齊後,即可使用此矩陣轉換物體的座標系。
三維物件偵測(3D Object Detection)
透過投影矩陣擷取二維物件框中對應之點雲資料,初步產生物件於三維空間之候選點。候選點分布呈現錐形體,其中包含目標物件與背景物件。為篩選出目標物件,透過光學雷達三維物件辨識技術,辨識出候選點雲中行人、二輪車、四輪車以及背景物件。最後經由含方向性之最小物件框估測技術(Minimum-volume Oriented Bounding Box, OBB)[5]產生三維物件框,如圖2所示,上方三格小圖為相機二維影像,內有1號框表示偵測到車、2號框表示偵測到人。下方大圖為光達之三維空間影像,3號框表示偵測到車或人。
 圖2 二維與三維物件偵測圖
圖2 二維與三維物件偵測圖
結合相機與光學雷達之物件偵測技術,除了能發揮相機物件偵測的長處,也能透過光學雷達使得三維空間物件框選更貼合、定位更精準。連續且穩定之物件框,供行人行為預測演算法擷取更完整的行人特徵,以利自駕車精準地閃避行人。
行為預測—行人過馬路
行人過馬路的情境主要考慮兩個點:1) 有無號誌指示;2) 行人是否遵守號誌指示。理想狀況下,假設有號誌指示且行人遵守號誌指示,則自駕車參照號誌資訊即可預測行人行為(一般來說,號誌資訊的來源有兩類:號誌透過路側通訊設備主動發送、或是來自車上相機的影像物件辨識)。然而,行人的行為並非如此單純好預測,行人可能會冒險不照號誌指示過馬路、或在無號誌指示路段過馬路。此時,自駕車對行人過馬路的行為預測模組就顯得格外重要。
行人移動模式和解決方案
從移動模式的角度,行人過馬路的行為可大略分為兩類:1) 行人延續過馬路前的移動方向或速度,直接過馬路;2) 行人過馬路的瞬間前後,移動模式驟變。比方原本站在路邊觀望,發現有空檔,隨即邁開腳步過馬路。第一類行為,用運動學模型即可作預測[6],實際路上也不常發生。第二類行為,才是真正的問題所在,由於運動模式驟變,運動學模型失效,需要額外的資訊作輔助才能預測。
深度學習的出現為解決第二類行為帶來了曙光[7],深度學習可以藉由從過去到現在一段時間內的目標行人影像串流,擷取出比單純行人移動軌跡狀態更多的資訊,進而了解行人過馬路前的預備動作(比方舉腳的動作)。結合大量的訓練資料,捕捉行人各種行為模式,理論上可以精準預測出行人下一時間是否過馬路的結果。圖3展示的是本團隊行人過馬路的預測結果。上圖,行人在路邊站著,頭上字母NC表示:模型預測該行人下一時刻不會過馬路。下圖,行人跨步準備要過馬路,頭上字母C表示:模型預測行人下一時刻將過馬路。
 圖3 行人過馬路預測
圖3 行人過馬路預測
然而,除了預測模型正確性之外,工程實務上還有其他難題要解決,比方:1) 遠方的行人影像太小,看不清楚行人動作,影響預測;2) 自駕車一直在動,使得偵測到的行人影像角度隨之一直改變,也影響預測;3) 運算即時性。突破重重困難後,最後,本研究可將精準的預測結果即時地傳遞給自駕車控制模組,作預警煞車的判斷。
自駕車預警煞車控制基於行人穿越意圖
當自駕車行駛於開放環境中,必定會與行駛環境中的動態物件進行互動,常見的動態物件包含:車輛、機慢車或行人等。當有物件即將進入自駕車所在的車道或是預計行駛的路線上時,自駕車就必須產生相對應煞車減速行為,來避免碰撞發生。
利用感知系統提供的物件偵測資訊,配合訊號處理與物件追蹤技術,估算出每個環境中動態物件的移動速度與移動方向,假設運動行為不變的前提下,自駕車可依據前述資訊預測出動態物件在短暫時間內可能的移動軌跡。一旦有了預測軌跡的資訊,便可進一步計算自駕車與各個動態物件間的碰撞時間(Time-to-Collision, TTC),藉此決定需施加多少的煞車力道來避免碰撞。
在物件穩定移動的情況下,利用運動學的方法可以有效率地預測出大多數動態物件的移動軌跡。然而,當移動物件的運動行為發生變化時,例如:從靜止突然移動、由移動中停下,基於運動學的預測便容易產生反應不及的狀況,尤其是面對移動模式相對靈活的行人更為明顯。透過預測行人是否穿越道路的意圖,自駕車得以依據肢體行為,在行人運動行為發生變化前提早反應,產生更為緩和且接近一般人駕駛的減速行為。在本案例中,行人穿越意圖預測模組計算出0~1的穿越機率,並配合3D物件偵測提供的位置與速度資訊,提供自駕車決策控制模組額外的預測資訊,藉此優化煞車控制,且避免單純運動學計算可能導致的預測失效。
聯網自駕巴士場域試運行
奠基於本團隊所開發之聯網自駕巴士技術,搭載實車系統於實際場域驗證,並配合經濟部「無人載具科技創新實驗條例」沙盒實驗申請,規畫逐年於實路場域提升自駕功能,達到市區開放場域自駕接駁能力,以期透過實際試煉場域,加速提升自駕系統成熟度。團隊與車王電子、華德動能,以及艾歐圖科技(iAuto)合作,共同打造國內首部自主研發之自動駕駛電動巴士,在2018年「臺中世界花卉博覽會」期間,於水湳智慧城半封閉場域展示。2019年開始導入混流行駛能力,與台灣iAuto團隊(成員來自台灣大學、明志科技大學、艾歐圖科技、台塑汽車貨運、工業技術研究院)參與杜拜全球自駕運輸挑戰賽,成功自全球27個競爭隊伍中脫穎而出,榮獲新創組第二名佳績。
繼台中花博自駕電動巴士試運行,車王電子再度與工研院合作,將於2021年前共同打造10部聯網自駕電動巴士產品,並整合國內14家廠商設備及軟硬體,加速國內自動駕駛產業鏈整體發展,2020年配合經濟部「無人載具科技創新實驗條例」進行沙盒實驗申請,與新竹縣政府、科技之星、車王電子,以及銓鼎科技共同推動「新竹縣高鐵自駕接駁運行實驗計畫」,由新竹高鐵往返喜來登飯店(竹北市區)開放混流道路自駕巴士接駁PoC/PoS/PoB服務,已於2020/11/10核准通過,運行日期為2020/11/11-2021/11/10,並於2020/12/1取得試車牌(試0002),可望提供民眾有感之特定自動駕駛車服務,不僅可讓國民感受臺灣在自動駕駛之世界級先進技術外,更可提供大眾安心、便捷、貼心服務(圖4)。
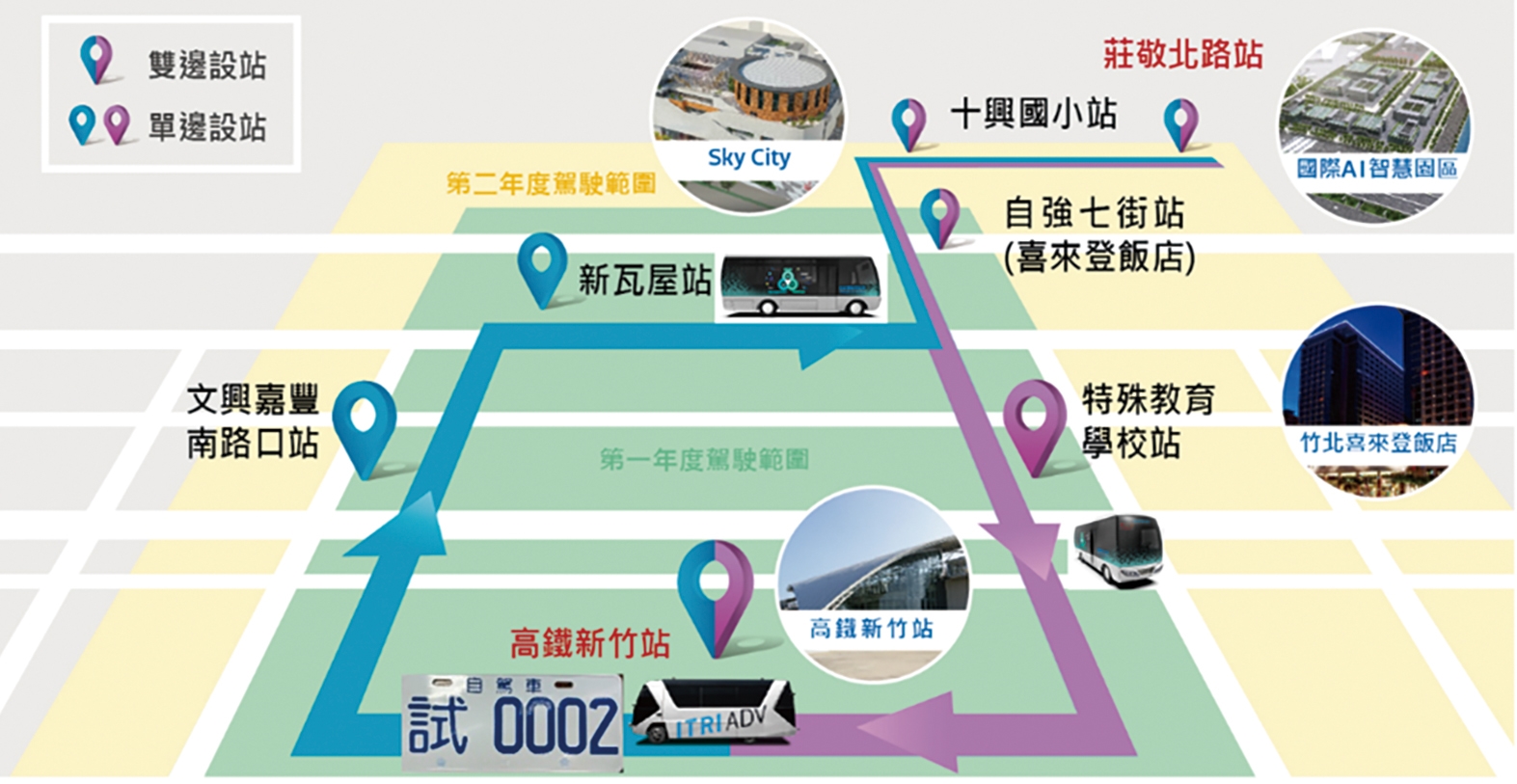 圖4 新竹縣高鐵自駕接駁運行實驗計畫運行路線
圖4 新竹縣高鐵自駕接駁運行實驗計畫運行路線
異質網路無縫整合自動駕駛朝更安全邁進
自動駕駛結合車聯網通訊技術的發展,讓自駕車與人、車、路與環境之終端設備、服務設施、路側設備等透過異質網路無縫整合,並進一步透過「影像物件偵測」、「行人行為預測」以及「預警煞車控制」等系統模組,有效提供自駕車提前掌握前方路況來車與行人,以驅動自駕巴士進行決策控制,未來多重感測與路側資訊如何快速因應實際場域需求,同時兼顧自駕安全及乘客舒適度,將成為下世代自動駕駛技術發展之關鍵挑戰,工研院聯網自駕巴士也將持續朝著提供安全、安心、便利的大眾運輸服務的目標邁進。

(本文作者皆任職於工研院資通所;該文也於工研院資通所《電腦與通訊》期刊刊登。)