近年來人工智慧和機器學習(Machine Leaning)應用的興起,促使當今積體電路晶片對於處理速度和存儲空間的需求愈來愈高,就處理器內部嵌入式記憶體而言,具有機器學習能力的處理單元可能就需要嵌入包含多層及數百或數千個單元的細胞式類神經網路(Cellular Neural Networks, CNN),使得處理單元必須要具有足夠大且足夠快的嵌入式記憶體方能處理機器學習運算相關資料頻繁的讀取和寫入,以實現低功耗、快速存取(Access)的記憶體解決方案。
每個AI引擎通常由多個記憶體組件組成,因此記憶體是AI晶片中的重要元件,必須具有低功耗和高性能的特性。記憶體一般可分為兩類:一類以讀寫速度快但具有揮發性(斷電資料易丟失)的傳統記憶體DRAM為代表,另一類以具有非揮發性但讀寫速度慢的傳統快閃記憶體Flash為代表。
AI晶片新創公司Gyrfalco Technology(以下簡稱GTI)看準磁阻式隨機存取記憶體(MRAM)同時兼顧非揮發性和高速讀寫的特性,能解決電腦或手機啟動慢、資料丟失、資料裝載緩慢、電池壽命短等問題,在超高速讀寫時能耗也相對較低,是AI時代的記憶體新寵。
AI晶片在實現記憶體內運算時遇到的核心問題,通常是基於晶片的功耗大多用在資料搬移上,為消除大量資料搬移的問題,GTI自主開發的AI運算架構及其核心技術,解決了資料搬運上複雜的環節,從而節省許多電量與能耗,降低成本、提高性能。 本文以下介紹GTI的核心技術、產品與應用,並洞悉其專利技術何以能讓三星和LG電子等國際消費電子巨頭買單。
AI記憶體內運算技術
圖1顯示GTI的核心技術架構係採用獨特的二維矩陣處理引擎(Matrix Processing Engine, MPE)與存算一體的記憶體內AI處理技術(AI Processing in Memory, APiM)技術相結合,可高速大幅加速細胞式類神經網路(CNN)處理且功耗低,同時兼顧了功耗與性能。基於其細胞式類神經網路的積體電路(CNN-based ICs)獨家專利架構,適用於卷積神經網路(Convolutional Neural Networks, CNN)、遞歸神經網路(Recurrent Neural Network, RNN)等常見深度神經網路的模型訓練及推理,以獨家專利技術架構提供客戶解決方案。
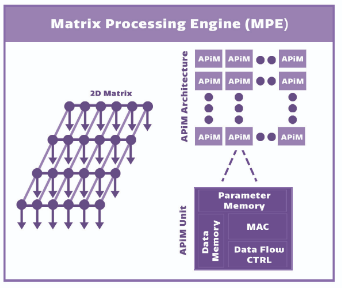 圖1 GTI採用二維矩陣處理引擎與記憶體內AI處理技術架構
圖1 GTI採用二維矩陣處理引擎與記憶體內AI處理技術架構
資料來源:GTI
二維矩陣處理引擎
如圖2所示,GTI採用的二維矩陣處理引擎(Matrix Processing Engine, MPE)是一個二維數字乘積累加運算(Multiply Accumulate, MAC)單元陣列,用於運算卷積神經網路的一系列層運算,特色在其可擴展的矩陣設計使得每個處理引擎直接與相鄰處理引擎互聯,從而優化和加速資料流程。基於GTI的二維矩陣式晶片結構,單品可以輕易整合幾十到幾十萬運算單元,多單品之間還可隨意無縫互聯,非常適合不同場景下的AI運算。第一代的晶片產品已經可以做到168核×168核的矩陣架構,相當於晶片內建的記憶體(或稱片上記憶體On-chip Memory)整合高達28,000個運算單元。
 圖2 GTI採用的二維矩陣處理引擎架構
圖2 GTI採用的二維矩陣處理引擎架構
資料來源:GTI[1]
APiM存算一體
為了提升內存運算的要求,圖3顯示GTI採用的APiM核心技術,概念正如其名是一種記憶體內的AI處理技術,架構上係使用晶片內建的記憶體(或稱片上記憶體On-chip Memory)作為運算單元,將儲存和運算融合一體以實現「存算一體」的本地並行AI運算架構;因為不需要使用晶片外接的記憶體(Off-chip Memory),例如不需要從晶片外連接到DRAM即可執行深度學習推理應用,有效降低了傳統架構中因為運算單元與儲存單元之間大量資料搬移所導致的高功耗,實現真正的在晶片上並行和原位運算,有效克服因記憶體頻寬導致性能瓶頸的問題。
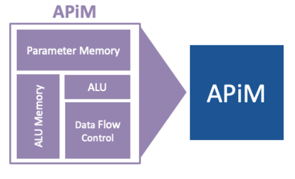 圖3 GTI採用存算一體的記憶體內AI處理技術(APiM)
圖3 GTI採用存算一體的記憶體內AI處理技術(APiM)
資料來源:GTI[2]
智慧神經網路處理器
現已有廠商推出支援卷積神經網路,也支援各種主流開源深度學習框架的智慧神經網路處理器,如GTI的Lightspeeur光矛系列產品,其分布式存儲結構非常適合CNN運算且支持多層結構,每層的尺寸可以不同,內置模型壓縮算法能夠實現快速且低功耗的CNN運算。在運算能力、功耗及延遲等性能上都表現優異,這都歸因於獨家的二維矩陣處理引擎(Matrix Processing Engine, MPE)和存算一體的記憶體內AI處理技術(AI Processing in Memory, APiM)的結合及其延伸設計出來的產品。
GTI利用專利架構和軟體,推出名為Lightspeeur光矛系列智慧神經網路處理器。其中,Lightspeeur2801S晶片採用了28nm製造技術,晶片內建的記憶體整合高達28,000個運算單元,單晶片峰值運算能力為5.6TOPS,效率能耗比達到9.3TOPS/W,180mW功耗下基於VGG模型每秒處理圖片150張,尺寸為7×7mm,小尺寸可容納於各類邊緣設備。該款晶片支援VGG和SSD等常見的網路模型,解決廣泛的Edge AI應用,並快速提供給全球公認的消費電子產品,自2017年9月推出後包括富士通、LG和三星等皆為其公開客戶。
Lightspeeur系列產品無論在訓練或是推理模式下,均可提供超高密度的運算性能與卓越的能耗效率,其多片組合方式不僅適用於邊緣運算,對於資料中心的加速處理、機器學習等領域也非常有優勢。使得GTI的產品可以適用於深度學習的訓練、推理環節,同時可以適用於雲端和終端。其中,推理環節會是未來AI晶片的重要應用場景,但目前主要聚焦在終端的推理環節。
GTI專利技術分析
圖4顯示GTI自2016年起開始申請專利,2018年達申請量高峰35件,並且專利申請逐年持續成長(2019年後下降係因專利尚未公開所致)。目前全球專利數量為76件,圖5顯示其專利的申請國以美國為主。圖6顯示GTI專利組合中主要四階國際專利分類碼(International Patent Classification, IPC)係以G06N3/00(基於生物模式之運算機系統)和G06K9/00(用於閱讀或識別印刷或書寫文字或者用於識別圖形之方法或裝置)為主。
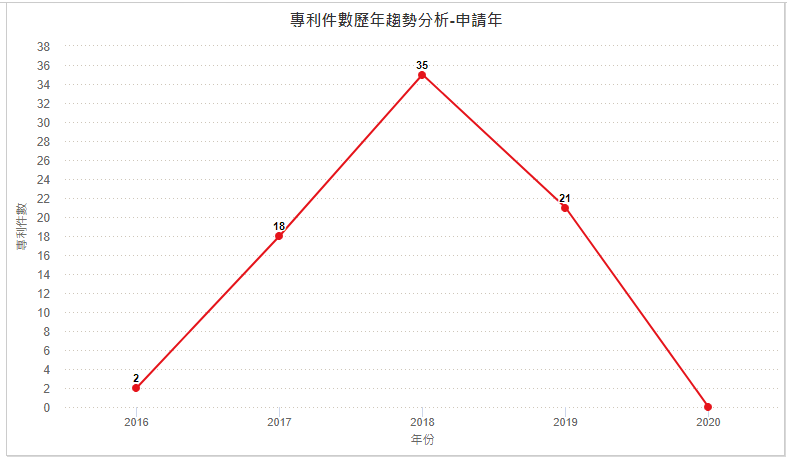 圖4 GTI逐年專利申請趨勢
圖4 GTI逐年專利申請趨勢
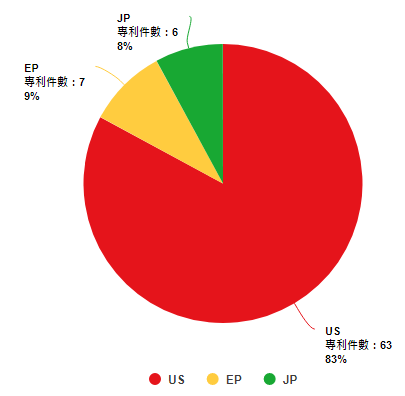 圖5 GTI的專利申請國別比例圖
圖5 GTI的專利申請國別比例圖
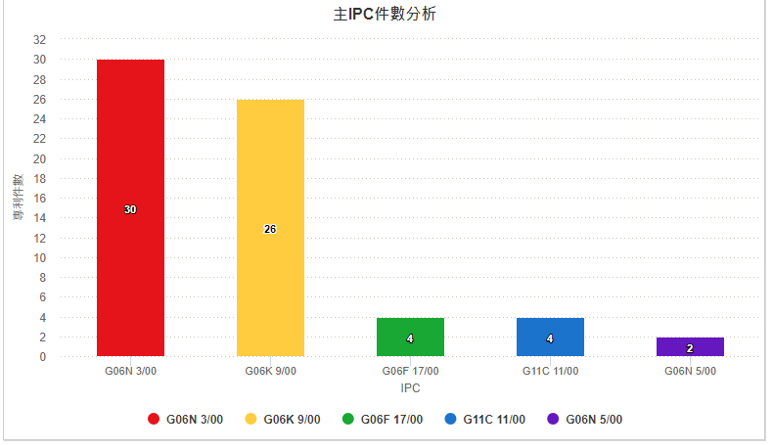 圖6 GTI的主要四階國際專利分類碼
圖6 GTI的主要四階國際專利分類碼
本文以下接著就GTI專利組合中專利被引證次數較多的幾件專利,以及GTI使用嵌入式MRAM技術的AI加速器晶片專利,並配合其圖示摘要說明該等專利的技術特徵。
・細胞式類神經網路處理引擎
美國專利US9940534B1[3]係揭露一種基於細胞式類神經網路從圖像資料(例如靜態圖像、影像串流的影格)中提取特徵的數位積體電路,用以實現快速處理大量圖像資料的運算速度。如圖7所示,該電路具有細胞式類神經網路處理區塊304,透過使用接收到的圖像資料和濾波器係數在像素位置執行卷積來同時獲得卷積運算結果。第一組記憶體緩衝器(即圖像資料緩衝器306)係操作性地耦合至CNN區塊以存儲透過第一多工器305饋送到CNN區塊中的圖像資料;第二組記憶體緩衝器(即濾波器係數緩衝器308)係操作性地耦合至CNN區塊以存儲準備饋入到CNN區塊的濾波器係數。 細胞式類神經網路處理區塊304的配置,係使用接收到的圖像資料和相應的濾波器係數在M×M個像素位置同時執行3×3卷積,圖像資料代表輸入圖像的(M+2)像素乘上(M+2)像素區域,且M是正整數。再者,如圖8所示,當數位積體電路上配置兩個或多個CNN處理引擎時,該等CNN處理引擎可透過時脈偏移電路(Clock-skew Circuit)1,440利用迴圈(Loop)的方式相互連接進行迴圈資料存取(Cyclic Data Access)。
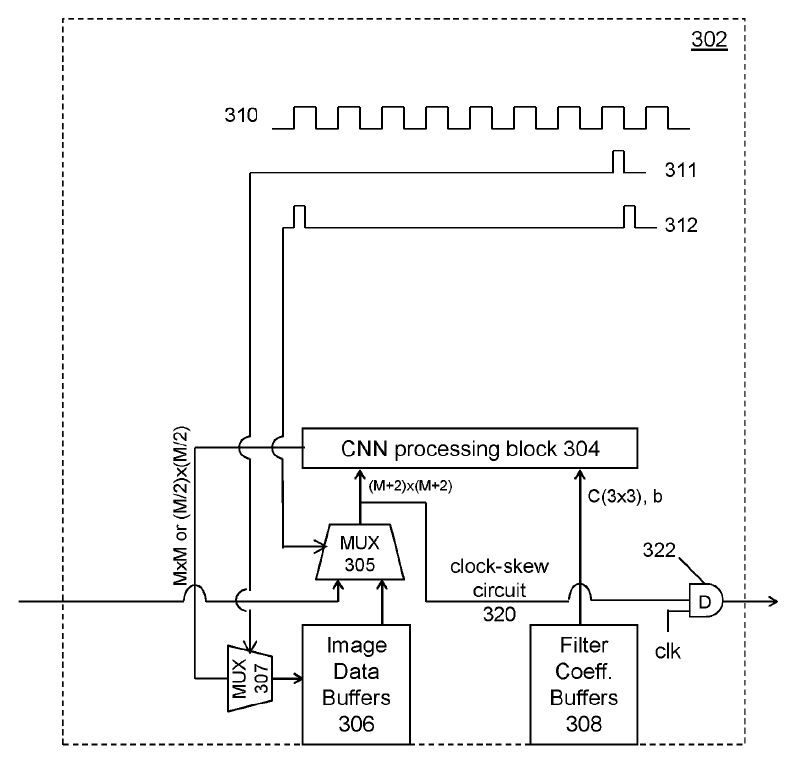 圖7 細胞式類神經網路處理引擎的示意架構圖
圖7 細胞式類神經網路處理引擎的示意架構圖
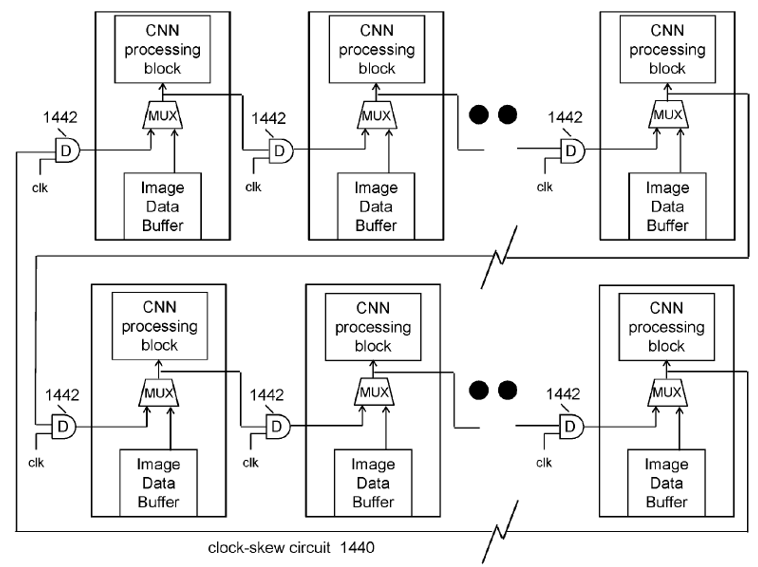 圖8 複數個CNN處理引擎透過時脈偏移電路以迴圈方式相互連接示意圖
圖8 複數個CNN處理引擎透過時脈偏移電路以迴圈方式相互連接示意圖
・STTM積體電路處理器
美國專利US9959500B1[4]係有關於一種具有嵌入式自旋轉移力矩記憶體(Spin Transfer Torque Memory, STTM)的積體電路處理器,該積體電路處理器的結構具有形成在邏輯電路頂部金屬接合墊上的介電層以及設置在具有磁性穿隧接面(Magnetic Tunnel Junction, MTJ)膜層之位元線(Bit Line)上的鈍化層。
圖9為該嵌入式STTM積體電路處理器的剖面結構圖,該嵌入式STTM積體電路處理器200包括形成在邏輯電路201之頂部金屬接合墊202上的介電層204、配置在介電層204上的黏著與形貌平坦化(Adhesion and Topography Planarization, ATP)層208以及設置在ATP層上的MTJ膜層212。ATP層208包括黏著與形貌平坦化墊206,且該黏著與形貌平坦化墊206與邏輯電路201的頂部金屬接合墊202電性連接,其中位元線216在MTJ膜層212上形成且在具有MTJ膜層的位元線216上配置有鈍化層218。ATP層可以具有多層(例如頂層和底層),總厚度為500A至4,000A,且頂層可以作為用於蝕刻MTJ膜層頂部的蝕刻停止層。位元線可以被配置為將資料發送到處理器的邏輯電路以執行一個或多個卷積神經網路運算。
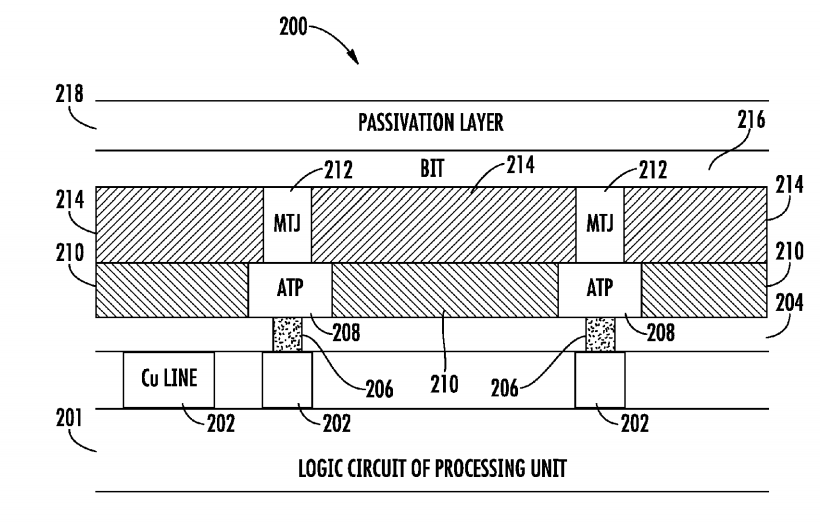 圖9 嵌入式STTM積體電路處理器的剖面結構圖
圖9 嵌入式STTM積體電路處理器的剖面結構圖
該專利新穎的處理器結構,解決傳統製作嵌入式記憶體製程中因高溫造成晶片翹曲或者熱穩定性差的問題,並且結構中的光滑表面與黏著性對於後續薄膜沉積和防止剝離(Peeling)現象的發生至關重要,從而減少了磁性穿隧接面的熱負荷,並避免記憶體良率損失與元件性能下降。
・深度學習物件偵測及識別系統
根據美國專利公開號US20180268234A1[5],係有關於一種深度學習物件偵測及識別系統,用以從二維圖像資料中偵測及識別物件。圖10為該專利設計用來從輸入圖像資料提取特徵的積體電路架構圖。該深度學習物件偵測及識別系統包含複數個基於細胞式類神經網路的積體電路(CNN-based ICs)100並藉由網路匯流排(Network Bus)將其可操作性地耦合在一起。該系統被配置為從二維圖像資料中偵測然後識別一個或多個物件。根據相應的N個分割區配置(Partition Schemes),將二維圖像資料畫分為N個不同的子區域。基於細胞式類神經網路的積體電路(CNN-based ICs)被動態分配以便從每個子區域中提取特徵,從而偵測並識別可能包含在其中的物件。N個子區域中的任何兩個彼此重疊,且N是一個正整數。使用基於近似的全連接層(Approximated Fully-connected Layers)的深度學習模型透過二元分類(Two-category Classification)來進行物件偵測,然後使用用於存儲已知物件特徵向量的本地資料庫(Local Database)來執行物件識別。
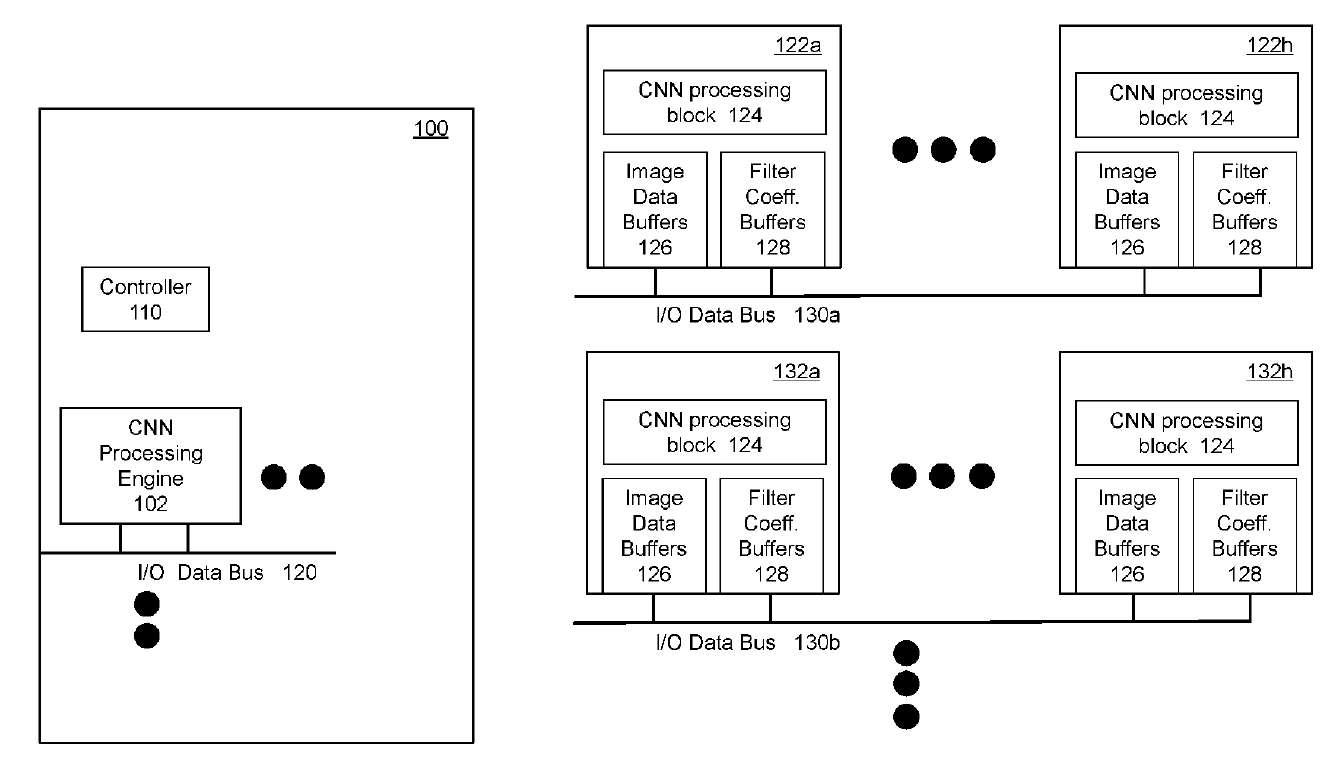 圖10 US20180268234A1基於CNN的積體電路架構圖
圖10 US20180268234A1基於CNN的積體電路架構圖
・具嵌入式OTP MRAM記憶體
根據美國專利公開號US20190180173A1[6]係涉及用於在人工智慧處理的積體電路,更特別是有關在人工智慧積體電路的一次性可編程(One-time Programmable, OTP)記憶體中使用參考電阻的方法和裝置。如圖11所示,該積體電路包括AI邏輯電路以及電耦合到AI邏輯電路以存儲AI模型參數的嵌入式一次性可編程磁阻式隨機存取記憶體(OTP MRAM)。其中,該嵌入式OTP MRAM記憶體具有存儲單元、參考電阻器以及用於確定每個存儲單元之狀態的記憶體讀取電路。此專利架構可最大限度地減少參考電阻器的數量,具有晶片尺寸減小和功耗降低等優勢。
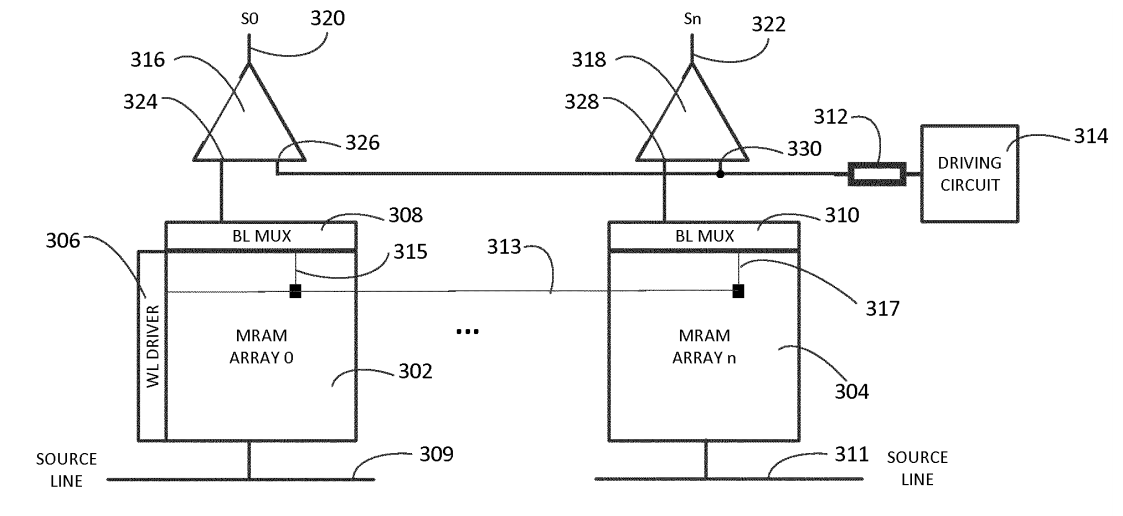 圖11 具有嵌入式一次性OTP MRAM的積體電路
圖11 具有嵌入式一次性OTP MRAM的積體電路
前述用於確定每個存儲單元之狀態的記憶體讀取電路又包括:多工器(308, 310)、源極線(309, 311)、驅動電路(314)以及比較器(316, 318)。其中多工器(308, 310)被配置為用以將每個存儲單元電耦合至參考電阻器;源極線(309, 311)係選擇性地向每個存儲單元提供第一電訊號以生成第一輸出訊號;驅動電路(314)係用以將第二電訊號提供給參考電阻器以產生第二輸出訊號;以及比較器(316, 318)被配置為比較第一輸出訊號和第二輸出訊號以產生指示每個存儲單元的狀態的輸出訊號(320, 322)。每個參考電阻器可以在一個或多個記憶體陣列中的多個記憶體之間共享。
該專利申請專利範圍除了主張一種用於人工智慧處理的積體電路之外,專利權利請求項還包括一種用於讀取嵌入式一次性OTP MRAM的方法,該記憶體用於在AI積體電路中存儲人工智慧模型參數。
積極拓展AI應用版圖GTI攜手消費電子巨頭
基於AI加速器晶片可與嵌入在電子設備中的各種主機處理器整合,例如智慧手機、消費電子產品、資料中心和工業機器人。以智慧手機為例,隨著邊緣AI智慧手機功能需求的迅速增加,2019年10月GTI與韓國消費性電子大廠LG Electronics合作開發先進的AI應用程序而將人工智慧整合到產品中,成功創造基於AI的消費性電子領域的合作模式。LG Electronics推出的Q70新款智慧型手機,就是採用了GTI生產的Lightspeeur5801晶片及其邊緣AI功能,結合高性能、低功耗、小尺寸和低成本封裝等優勢,用於相機效果的推理可為終端用戶提供實時影像散景效果(Real-time Video Bokeh Effect)和圖像增強等高畫質的AI手機體驗[7]。藉由GTI與LG Electronics的合作推出具有Edge AI的新智慧手機,印證了GTI的Lightspeeur光矛系列產品在智慧手機和智慧家庭等應用程序執行邊緣智慧的實力,已獲得國際大廠的青睞。
此外,2018年9月GTI宣布已將Lightspeeur2801S晶片產品發貨給三星[8],提供具邊緣AI致能的設備並企圖與英特爾在2017年推出的神經運算棒(Neural Compute Stick)競爭。Lightspeeur 2801S是GTI的APiM記憶體處理架構的第一個實例,將儲存和運算融合一體實現存算一體的AI運算架構,不需要外接記憶體即可進行AI推理,為此GTI成為三星硬體平台在AI領域唯一的合作夥伴。
平衡成本、性能和能耗是AI晶片加速器業者GTI將AI智慧設備大舉推向市場的挑戰。從GTI近年積極與國際巨頭策略夥伴的合作,可以預見GTI有望在這波AI邊緣智慧大戰中脫穎而出開創新局。

(本文作者為工業技術研究院技術移轉與法律中心博士)