從按鈕到語音操控,數位電視(DTV)不斷優化其互動方式。語者辨識(Speaker Identification)技術能根據語者的語音特徵來識別語者,為數位電視智慧化升級提供了新的契機。本文將探討於裝置端運行語者辨識功能的一項專案,分析其實作方式及實際效能。
效能結果
(承前文)該應用的關鍵效能指標是管線執行時間和CPU/GPU利用率。管線執行時間非常重要,管線執行得越快,處理器就有越多時間處理數位電視上運行的其他任務。了解CPU/GPU利用率有助於全面了解應用在運行推論時如何有效地運用可用資源,還能顯示推論運行之間的情況。
透過對管線的測試,發現推論時間在管線執行時間中占大部分。圖5展示了正規化的管線時序。因此,了解不同裝置和後端對推論的影響非常重要。此專案使用Arm Streamline Performance Analyzer進行時序效能基準測試並採集CPU/GPU利用率資訊。
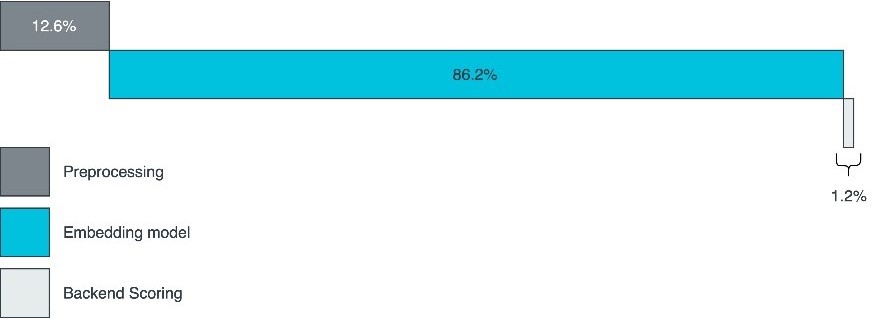 圖5 正規化的管線時序
圖5 正規化的管線時序
為了比較不同裝置的管線執行時間,此專案使用XNNPack作為TFLite的後端(Backend),在四核Arm Cortex-A76 CPU和四核Cortex-A55 CPU處理器上運行應用。接著,再只使用每個處理器的單個核心重複進行測試。測試結果如圖6所示。
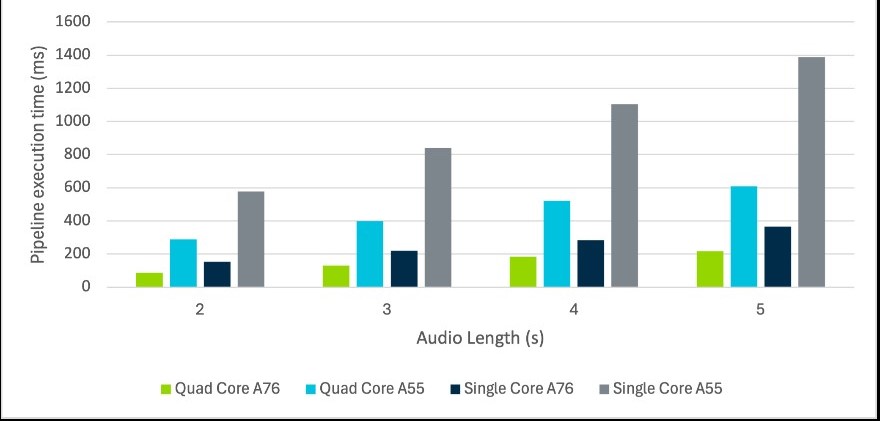 圖6 不同裝置的管線執行時間結果
圖6 不同裝置的管線執行時間結果
如同預期,Cortex-A76的平均管線執行時間比Cortex-A55更短,顯示效能更強的硬體提供了更快的執行速度。圖中也顯示了四核執行相對於單核執行的顯著增益。四核Cortex-A76的平均速度最多提高了三倍,四核Cortex-A55的平均速度則最多提高了3.8倍。儘管並非所有的管線都可以並行化處理,但推論過程中的一大部分確實因此獲得了效能改善。
管線執行時間越短,CPU就能有更多時間運行其他任務,進而提供更出色的整體用戶體驗。這些測試還證明,可以在單個Cortex-A55核心上運行語者辨識技術,並仍能達到可接受的推論時間。儘管如此,這種方法對使用者介面的回應速度仍具有明顯影響。
Arm Mali GPU也可用於ML工作負載,進而降低CPU利用率,為其他任務留出更多空間。如前所述,(在撰寫本文時)固定軸模型必須與TFLite的GPU委派一起使用。圖7顯示了固定軸模型間的比較。在四核Cortex-A76上運行與在GPU委派和四核Cortex-A76之間分割執行進行了比較。
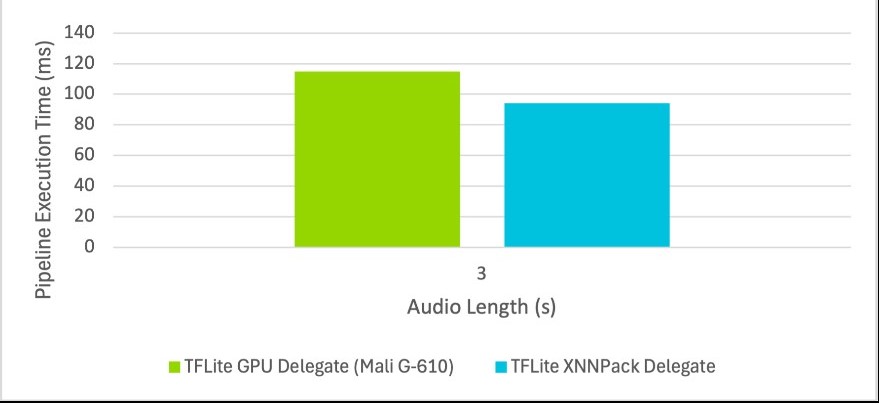 圖7 管線執行時間與音訊長度間的比較
圖7 管線執行時間與音訊長度間的比較
TitaNet Small模型中的某些運算子不支援GPU執行,代表這些運算子會退回至CPU執行。因此,使用GPU委派的平均推論時間比使用CPU慢了21.8%。然而,在使用GPU委派時,CPU利用率減少了51.2%。圖8說明此一情況。這些結果顯示,在GPU活躍度較低的情況下,可以卸載部分工作負載,進而減輕CPU的壓力。在GPU上運行推論可實現負載平衡,並充分利用所有可用硬體。
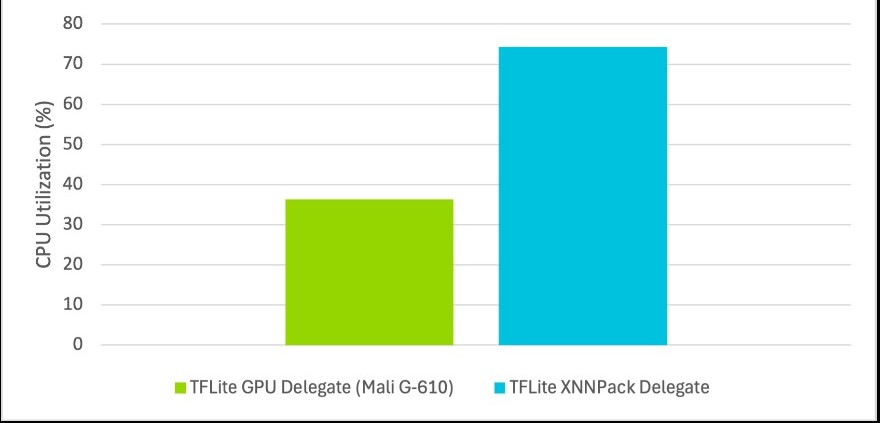 圖8 管線執行期間的平均CPU利用率
圖8 管線執行期間的平均CPU利用率
此處展示的推論時間是在四核Arm Mali-G610 GPU上運行時所收集而來,使用GPU委派2.16版本。由於具體配置和對運算子的支援會直接影響執行速度,不同硬體、模型和應用的執行時間都不盡相同。
量化(Quantization)
模型量化是一種可降低運行推論的運算和記憶體成本的優化技術。具體做法是用較小的資料類型來表示權重(Weight)和啟動(Activation),例如用8位元整數代替32位元浮點數。
訓練後量化是在模型轉換過程中進行的一種優化技術。顧名思義,訓練後量化可以對已經訓練好的模型進行量化,主要分為三種技術:動態範圍量化、全整數量化、Float16量化。
由於動態範圍量化技術在轉換過程中不需要代表性資料集,本文僅針對該技術進行探討。動態範圍量化是指僅將模型權重量化為整數。該模型在執行時盡可能混合使用整數和浮點運算操作。如果無法實現,執行將退回至Float32。
TitaNet Small量化模型實現了約10%的速度提升,記憶體占用減少了約50%。雖然訓練後量化會導致品質略微下降,但利大於弊。在實驗中,即使模型精度降低,其差別仍幾乎可以忽略不計。
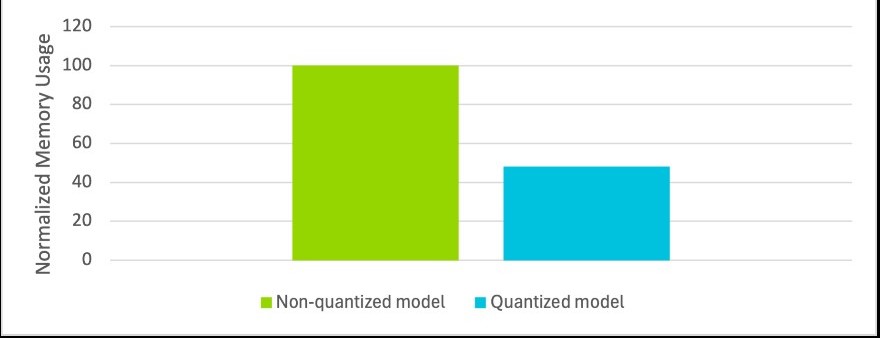 圖9 量化模型與非量化模型的正規化記憶體使用情況對比
圖9 量化模型與非量化模型的正規化記憶體使用情況對比
數位電視智慧升級互動更自然
此專案證明基於Arm技術的數位電視能夠運行邊緣AI工作負載,改善使用者體驗,同時維護資料隱私。說話是人類自然的交流方式,若要簡化使用者與電視的對話模式,數位電視不僅需要理解使用者所說的內容,還要能夠確知語者的身分。本文研究結果顯示,高效能Arm CPU為語者辨識技術與其他AI語音任務的結合提供了可能性,包括語者自動分段標記(Diarization)、語音轉文本,以及未來運行於邊緣端的大型語言模型(LLM)等,未來發展值得期待。
(本文作者為Arm工程部工程師;中文版校閱者為Arm首席應用工程師黃煦雯)
模型量化/高效能處理器助攻 裝置端語者辨識革新DTV互動體驗(1)
模型量化/高效能處理器助攻 裝置端語者辨識革新DTV互動體驗(2)