將數位訊號處理器(DSP)、繪圖處理器(GPU)和現場可編程閘陣列(FPGA)拿來當作中央處理器(CPU)的加速器,具有性能和功率效益上的優勢。但考慮到運算架構的多樣性,設計人員需要一種統一的方法來衡量性能和功率效益。
業界認可的方法是測量每秒浮點運算次數(FLOP),按照IEEE 754標準,FLOP被定義為單精確度(32位元)或者雙精度(64位元)數字加法或乘法。所有更高階函數,例如除法、平方根和三角函數運算,都可以使用加法器和乘法器來建構。這些運算功能,以及其他常用的函數,如快速傅立葉變換(FFT)和矩陣運算等,都需要加法器和乘法器,所有這些架構中加法器和乘法器一般都是1:1。
DSP、GPU和FPGA性能比較
基於其峰值FLOPS比來對比DSP、GPU和FPGA架構的性能,是在最大運作頻率下,透過加法器和乘法器求和積來確定峰值FLOPS比。這代表運算的理論極限,實際中很難獲得。一般不可能實現在所有時間的全部運算單元上都保持運行的演算法,但確實有實用的對比指標。
DSP峰值GFLOPS
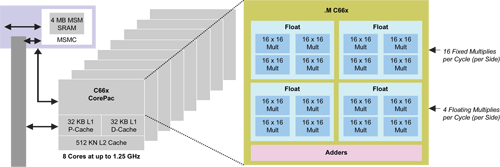 |
| 圖1 TMS320C667x DSP架構 |
以德州儀器(TI)的TMS320C667x DSP為例(圖1),這一顆DSP包括八個DSP核心,每一個核心含有兩個處理子系統。每一個子系統包括四個單精確度浮點加法器和四個單精確度浮點乘法器。總共有六十四個加法器和六十四個乘法器。最快的能夠運行在1.25GHz,峰值性能達到160 GigaFLOPS(GFLOPS)。
GPU峰值GFLOPS
功能最強大的一種GPU是NVIDIA Tesla K20(圖2),這顆GPU採用CUDA核心,每一個核心都有一個浮點乘法加法單元,在單精確度浮點配置時,每個時鐘週期能夠執行一次。每個串流多重處理器(SMX)處理引擎中有一百九十二個CUDA核心。K20實際上含有十五個SMX,能夠使用其中的十三個(例如由於製程良率問題)。這樣一來,總共有二千四百九十六個CUDA核心,每一個時鐘週期2 FLOP,最大運行頻率是706MHz。這樣一來,峰值單精確度浮點性能達到3,520 GFLOP。
 |
| 圖2 GP-GPU架構 |
FPGA峰值GFLOPS
Altera在其FPGA中提供硬式核心浮點引擎。在整個可程式設計邏輯結構中,嵌入的硬式核心DSP模組含有一個單精確度浮點乘法器和加法器(圖3)。該公司中階Arria 10 FPGA系列的中等規模FPGA有一款10AX066。這一顆元件有一千六百七十八個DSP模組,每個都能夠在每一個時鐘週期中執行2 FLOP,結果每一個時鐘週期達到3,376 FLOP。額定速率450MHz(相對於浮點,定點模式會更高)時,這實現了1,520 GFLOP。
 |
| 圖3 FPGA中的浮點DSP模組架構 |
以相似的方式進行運算,該公司在高階Stratix 10 FPGA中提高了時脈速率,而且元件規模更大,提供更多的DSP運算資源,單精確度性能高達10,000 GFLOP,即10 TeraFLOP。
使用可程式設計邏輯實現浮點運算
使用FPGA的可程式設計邏輯,總是能夠在FPGA中實現浮點功能。而且,採用可程式設計邏輯架構的浮點功能,可以實現任意精度,不會受到業界標準單精確度和雙精度的限制。
Altera提供幾種不同級別的浮點精度。但是,並不太容易確定已使用了可程式設計邏輯的某一個FPGA的峰值浮點性能。因此,FPGA的峰值浮點速率只是基於硬式核心浮點引擎的性能,假設浮點功能並沒有使用可程式設計邏輯,而是設計的其他部分使用了可程式設計邏輯,例如資料控制和調度電路、輸入/輸出(I/O)介面、內部和外部記憶體介面,以及其他必須的功能。
確認浮點性能遇到的挑戰
有幾種因素導致很難計算可程式設計邏輯的浮點性能。透過查詢FPGA供應商浮點矽智財(IP)使用者指南,能夠確定建構一個單精確度浮點乘法器和加法器所需的邏輯量。但是,使用者指南中並沒有提供關鍵資訊,而這是布線所需要的資源。
實現浮點時,需要大規模筒形移位暫存器(Barrel Shifter),它會占用非常多的可程式設計布線(可程式設計邏輯單元間的互聯)。所有FPGA支援邏輯的互聯數量是一定的,與典型定點FPGA設計應用有關。
然而,與大部分定點設計相比,浮點並不需要這麼多的互聯。當建立一個浮點函數的例化時,會占用邏輯單元中公共區域的布線資源。但是,當大量的浮點運算功能被封裝到一起時,結果就是布線壅塞。與可比的定點FPGA設計相比,這導致設計時脈速率和邏輯利用率大幅度下降。對此,「融合資料通路」專用合成技術在一定程度上減輕了這種影響,支援在邏輯架構中實現規模很大的浮點設計,單精確度採用定點27×27乘法器,雙精度採用54×54乘法器。
另外,並不能完全使用FPGA邏輯。設計占用大部分邏輯資源,因此時脈速率(即fMAX)能夠實現的時序收斂範圍減小,最終有可能根本實現不了時序收斂。典型的是,最終會使用70~90%的邏輯,對於密集浮點設計,應占用最小比例。
除此之外,FPGA的邏輯資源並不能被完全使用。當一個設計占大規模的資源比例的情況下,fMAX即可達到的時鐘頻率會下降,導致優勢時序無法被滿足。通常,70~90%的邏輯資源會被使用,但如果是密集的浮點設計時,使用情況會趨向於低的比率。
建構基準測試設計 掌握浮點運算效能
出於這些原因,在可程式設計邏輯中實現時,幾乎不可能計算FPGA的浮點性能。而最佳方法是建構基準測試浮點設計,它包括時序收斂過程。或者,FPGA供應商能夠提供這類設計,這對於估算FPGA能夠實現什麼有很大的幫助。
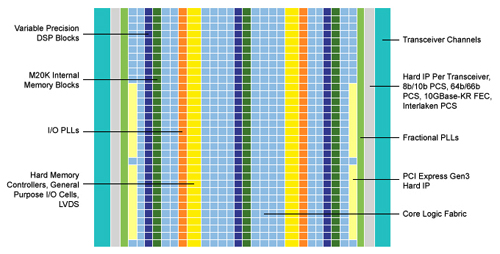 |
| 圖4 Arria 10 FPGA架構示意圖 |
28奈米(nm)FPGA基準測試設計,覆蓋了基本及複雜浮點設計。公開的結果顯示,採用28奈米FPGA,快速傅立葉變換等簡單演算法能夠實現數百GFLOP,而QR和Cholesky分解等複雜演算法能達到100 GFLOP以上。此外,協力的技術分析廠商Berkeley設計技術有限公司(BDTI),也在Altera 28奈米FPGA上進行複雜高性能浮點DSP設計獨立分析。
使用OpenCL,在28奈米Stratix V FPGA上也實現了很多其他浮點基準測試設計,很多其他的浮點基準設計也採用OpenCL在Altera 28奈米Stratix V上實現,申請可以獲得這些設計。這些設計目前正在移植到Arria 10 FPGA(圖4)上,由於採用硬式核心浮點DSP模組架構,因此能夠極大地提高性能。
硬式核心浮點電路提升效能
目前市面上已可看到具有硬式核心浮點DSP模組的FPGA,如中階Arria 10元件的單精確度浮點性能在160至1,500 GFLOP之間,高階Stratix 10元件則高達10,000 GFLOP。這些峰值GFLOP指標係採用與CPU、GPU和DSP同樣透明的方法來計算。這種方法為設計人員提供了可靠的技巧,針對具有不同架構的元件的峰值浮點運算能力進行基準對比。下一個層面的對比,應基於在感興趣的平台上實現的具有代表性的基準測試設計。
(本文作者為Altera首席DSP產品規畫經理)