美光(Micron)的LPDDR5X是一種低功耗記憶體技術,專門設計用來應對現代資料中心不斷增加的能源需求。其效能比DDR5記憶體更高,耗電量卻更低。透過採用先進的電源管理功能,包括較低的操作電壓、深度睡眠模式和智慧電源最佳化算法,LPDDR5X實現了令人印象深刻的省電效能。在資料中心環境中,每一瓦電力都至關重要,這項技術有助於降低資料中心的營運成本和環境影響。
眾所皆知,人工智慧(AI)和高效能運算(HPC)工作負載在頻寬和功耗方面,正面臨越來越大的限制。為了評估LPDDR5X相較於DDR5在下一代資料中心架構中的潛在價值,美光全面測試了LPDDR5X在關鍵指標上的表現:記憶體頻寬、功耗、應用運行時間、能效(每瓦效能)和執行運算任務需要的電力。美光使用了多種測試套件,包括一個微基準測試(Multichase測試)以評估基本的記憶體特性、一個計算密集型的HPC模擬(POT3D),以及在不同參數大小(8B和70B)下的AI模型(Llama 3)。透過這些測試資料所帶來的洞見,我們可以清楚看出LPDDR5X在提高資料中心的效率和效能方面,能帶來的效益。
面對日益增加且持續的壓力,IT領導者需要在控制與日俱增的能源成本的同時,實現效率最佳化。這份報告針對先進記憶體技術(如LPDDR5X)在資料中心的高效能運算與AI工作負載中,能實現多少效能和能源效率的提升,進行了密集的分析。對科技投資者和決策者而言,這份測試結果相當具有參考價值,因為這份報告可以協助他們了解,低功耗記憶體技術在面對擴展性、功耗和效能的挑戰時,能發揮什麼潛在影響。
LPDDR在資料中心系統中的應用
為研究低功耗記憶體在資料中心架構中的潛力,美光選擇了LPDDR5X的第一個商業應用--NVIDIA Grace HopperGH200系統,作為主要測試平台。這一創新系統將ARM CPU與H100 GPU整合在一起,代表了高效能運算基礎建設的尖端方法。
本文將基於LPDDR5X的Grace Hopper與2022~2023年同期的DDR5伺服器配置進行比較分析和基準對比,如表1中詳述。透過有系統地比較這些系統,本文量化了先進記憶體技術在各種計算工作負載下的效能和功耗影響,包括微基準測試、人工智慧和高效能計算應用。LPDDR5X與DDR5的根本架構差異體現在記憶體封裝上。LPDDR5X記憶體是直接焊接在Grace Hopper板上(圖1),而DDR5模組則以64位元寬度的匯流排連接到CPU。Grace Hopper利用了32個記憶體控制器,每個控制器管理來自每個LPDDR5X封裝的16位元通道。這種配置在資料處理方面提供了更高的平行處理能力和效率,因為每個通道可以獨立運作。
系統配置
| 系統 |
LPDDR5X System |
DDR5 System |
| 平台 |
NVIDIA GH200 Grace Hopper Superchip |
X86 |
| 時脈頻率 |
3.1GHz |
3.9GHz |
| 核心數 |
72 |
64 |
| L3快取 |
114MB |
320MB |
| 記憶體 |
LPDDR5X 6400MT/s
Rank = 4
Memory controllers (MC): 32
Width per channel: 16bits
Total width: 512bits |
DDR5 5600 MT/s
Rank = 2
Memory controllers (MC): 2
Width per channel: 64bits
Total width: 512bits |
| GPU |
H100 96GB HBM3 |
H100 96GB HBM3 |
| CPU-GPU互連 |
NVLink: C2C 900GB/s bidirectional |
PCIe: 128GB/s bidirectional |
註:LPDDR5X系統的CPU為ARM Neoverse V2; DDR5系統的CPU為Intel Xeon Platinum 8592+處理器
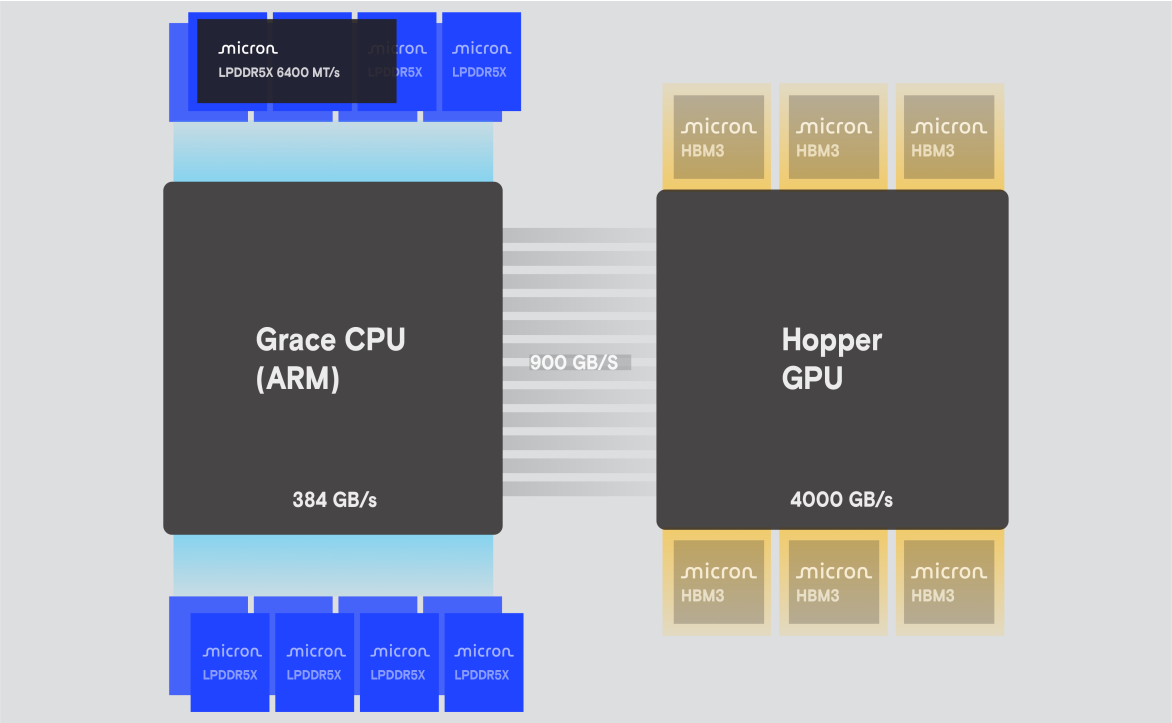 圖1 LPDDR5X系統--LPDDR5X和ARM架構
圖1 LPDDR5X系統--LPDDR5X和ARM架構
相比之下,DDR5系統則採用了更傳統的方法(圖2):4個記憶體控制器,每個控制器有4個32位元通道(使用2個32位元子通道),總共達到16個32位元寬度的通道。LPDDR5X配置提供4個Rank,DDR5則只有2個Rank,因此LPDDR5X具有更高的平行存取能力,因為每個Rank都是獨立運作的。在效能方面,LPDDR5X更具有優勢,其理論峰值頻寬為384 GB/s,稍微高於DDR5的358 GB/s。更高的資料速率、更強的平行處理能力和更大的頻寬,使得LPDDR5X成為高效能計算(HPC)應用和混合記憶體存取模式的優秀技術。
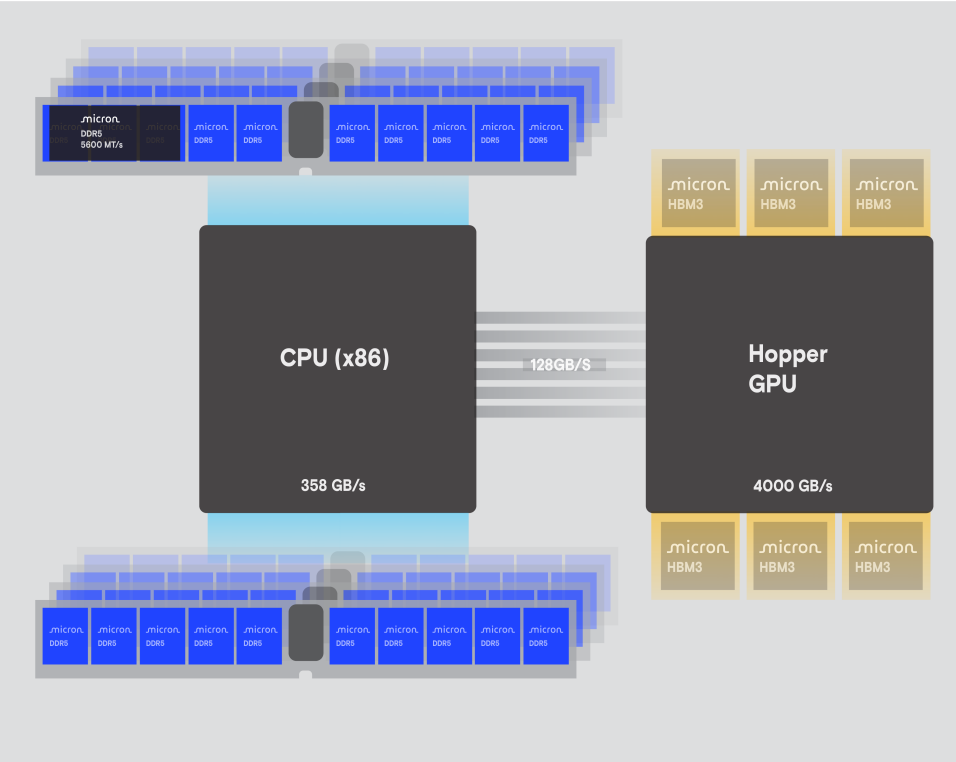 圖2 DDR5系統--DDR5與x86架構
圖2 DDR5系統--DDR5與x86架構
LPDDR5X與DDR5的頻寬和功耗分析
本基礎測試使用Multichase,這是一種評估記憶體頻寬和延遲的效能測試工具。Multichase通過一系列指標追蹤(Pointer Chasing)操作來模擬不同的記憶體存取模式。這項基準測試在評估記憶體系統如何處理非連續資料存取(隨機存取)時特別有效,而這種存取模式在實際應用中相當常見。此基準測試的方法論包含多個執行緒同時執行記憶體讀取和寫入操作以測量頻寬。基準測試會記錄完成這些操作所需的時間,從而計算出以GB/s為單位的記憶體頻寬。
我們從原始碼編譯了Multichase,並為兩個平台採用了預設的最佳化參數設定。Multichase可以評估各種記憶體類型在不同條件下的效能表現,提供有關其效率和適用於不同應用的寶貴見解。由於在LPDDR5X和基於DDR5的系統中,只需要一小部分計算核心就能使Multichase的記憶體頻寬達到飽和,因此這是在兩個擁有不同指令集架構(ISA)的系統上,排除系統差異,單純比較記憶體頻寬和功耗表現的好方法。
測試結果
我們的比較分析顯示( 圖3 ) ,LPDDR5X在不同的記憶體存取模式下效能有所提升。在1R:1W情境中,LPDDR5X提供293 GB/s的頻寬,比DDR5的215 GB/s提升了36%。在1R:0W和Stream 2R:1W情境中,也觀察到類似的結果,其效能分別增加了11%和32%。這些改進來自於LPDDR5X的創新架構:4R Rank以及更細的通道粒度,這最佳化了記憶體存取效率並降低延遲。
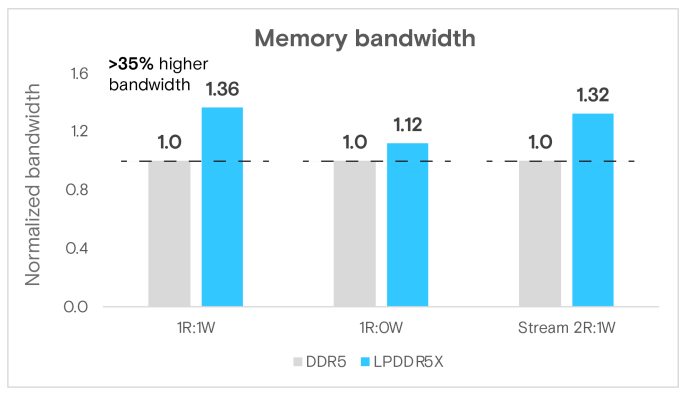 圖3 Multichase基準測試的最大頻寬(每秒十億位元組[GB/s])
圖3 Multichase基準測試的最大頻寬(每秒十億位元組[GB/s])
針對圖4的進一步說明如下。為了在Grace上測量DRAM功耗,我們使用了NVIDIA針對LPDDR5X的DRAM功耗模型進行測量。針對DDR5,則是透過Performance Counter來測量功耗。在1R:1W的情境中,LPDDR5X的功耗僅為19.9瓦,比DDR5的86.5瓦大幅減少了77%。在不同的存取模式下,功耗節省也可見達到75%~77%的相似效果。LPDDR5X通過降低工作電壓、深度睡眠模式和最佳化的功耗管理演算法來實現這些功耗節省。
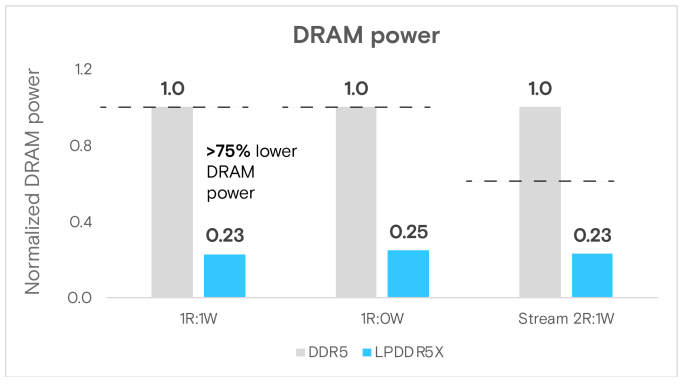 圖4 Multichase基準測試的DRAM功耗(瓦特)
圖4 Multichase基準測試的DRAM功耗(瓦特)
針對圖5的進一步說明如下。透過ipmitool收集的系統級電力測量顯示,LPDDR5X系統的功耗始終較低,比DDR5系統低約29%~34%。儘管Grace的主要設計目標是提高能源效率,但系統級功耗能降低40%,與LPDDR5X的低功耗特性息息相關。
M u l t i c h a s e微基準測試分析顯示LPDDR5X在頻寬和功耗方面的優勢,為評估其在資料中心應用中的潛力提供了有前景的框架,接下來的幾個章節將探討在高效能運算(HPC)和人工智慧(AI)等實際應用中的效能和功耗改善。
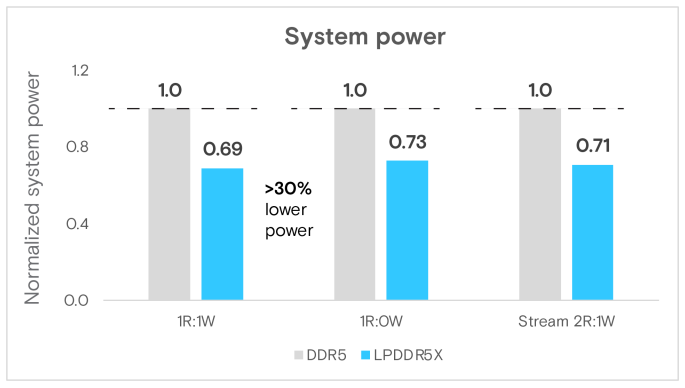 圖5 Multichase基準的系統功率(瓦特)
圖5 Multichase基準的系統功率(瓦特)
LPDDR5X在資料中心的高效能計算
我們評估了LPDDR5X在高效能計算(HPC)應用中的表現,使用的是太陽物理學模擬工具POT3D。這是一個模擬日冕磁場動態的工作負載。我們的分析顯示,基於LPDDR5X的系統在效能和效率上有顯著的優勢。
POT3D實驗顯示,相較於DDR5,LPDDR5X系統的運行時間提升了10%,這是由更大的記憶體頻寬和架構差異所驅動(圖6)。LPDDR5X的記憶體頻寬利用率也達到了20%的提升(圖7a)。值得注意的是,高效能運算(HPC)應用受到記憶體頻寬的限制,通常也遵循記憶體頻寬增益的趨勢。回想一下,在前面提到的multichase微基準測試中,LPDDR5X比DDR5實現了約36%的記憶體頻寬增益(1R:1W),而在此實際應用中,複雜的資料存取模式可以達到其潛力的55%以上。這凸顯了LPDDR5X在緩解記憶體密集型應用的頻寬限制方面,是非常有機會的。
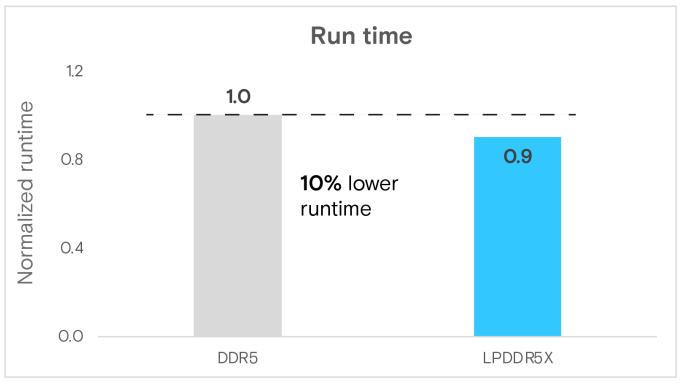 圖6 POT3D(太陽物理學)的運行時間
圖6 POT3D(太陽物理學)的運行時間
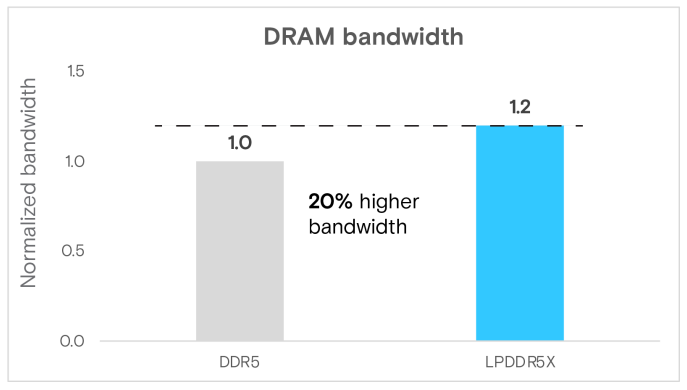 圖7(a) POT3D(太陽物理學)的DRAM頻寬
圖7(a) POT3D(太陽物理學)的DRAM頻寬
功耗結果同樣引人注目:在POT3D執行期間,LPDDR5X記憶體的功耗降低了75%(圖7b),與微基準測試的觀察結果一致。這一顯著的減少不僅降低了功耗,還有助於建立更永續的資料中心基礎設施。
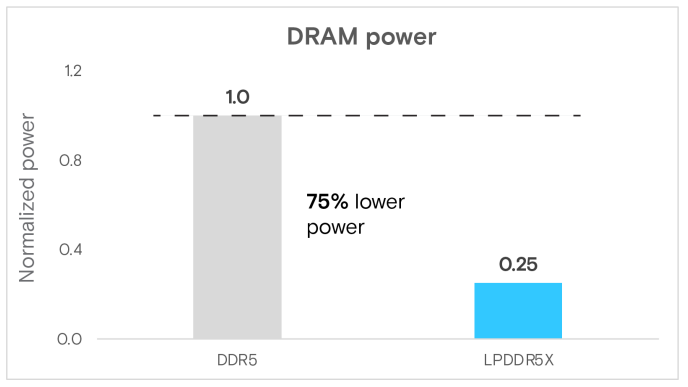 圖7(b) POT3D(太陽物理學)的DRAM功耗
圖7(b) POT3D(太陽物理學)的DRAM功耗
總結來說, POT3D分析突顯了LPDDR5X的變革潛力:75%的DRAM功耗優勢、20%的記憶體頻寬增益以及10%的運行時間縮短,使其成為一項在記憶體密集型HPC應用中,極具發展潛力的技術。
在CPU/GPU系統中使用LPDDR5X進行LLM推論
我們評估了LPDDR5X在LLM推論中的表現,涵蓋了兩個場景:純CPU和CPU+GPU配置。
純CPU進行Llama 3 8B推論
我們在LPDDR5X和DDR5系統上運行了Llama 3 8B模型。參數範圍在8B~20B之間的模型,通常被認為適合僅使用CPU執行。DDR5系統配備了一個效能強勁的x86 CPU,時脈為3.9GHz,並擁有較大的L3末級快取,顯示出更好的原始效能:生成token的速度快了1.7倍,首個token的延遲改善約1.1倍(圖8)。
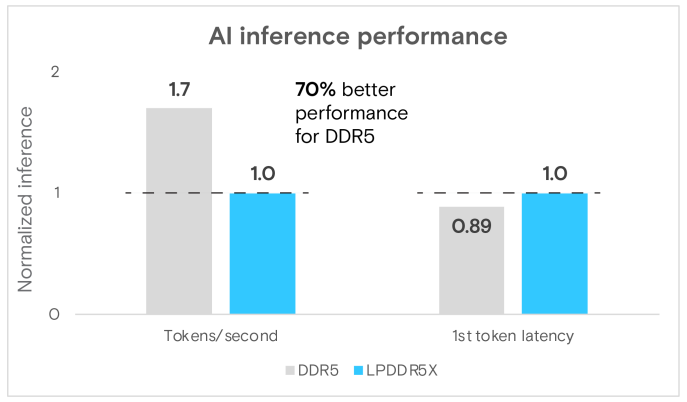 圖8 Llama 3 8B的AI推論效能比較
圖8 Llama 3 8B的AI推論效能比較
然而,在評估每瓦效能時,LPDDR5X系統表現優異。利用LPDDR5X記憶體和低功耗的ARM架構Grace CPU,它實現了1.1倍的電源效率提升(圖9),這有潛力顯著降低推論部署成本。本報告前面提到的multichase基準測試的功耗結果顯示,採用LPDDR5X可使整體功耗降低約40%(圖10)。
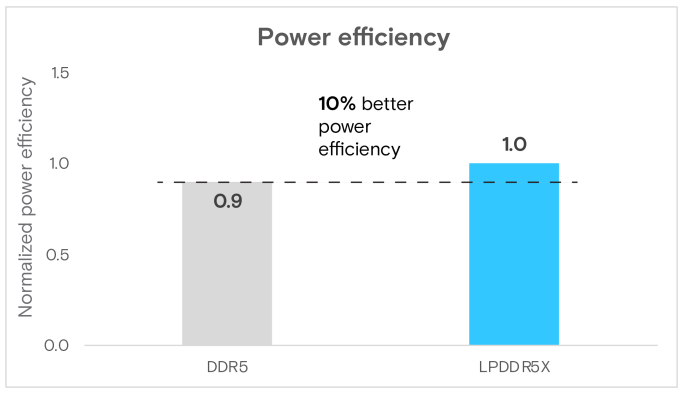 圖9 Llama 3 8B的能源效率比較(效能/瓦特)
圖9 Llama 3 8B的能源效率比較(效能/瓦特)
在CPU+GPU系統上進行Llama 370B推論
為了更深入了解LPDDR5X在CPU+GPU推論場景中的角色,我們研究了一個擁有700億參數的Llama 3模型。這類大型模型由於對頻寬與運算效能的需求極高,因此需仰賴GPU與HBM資源。我們採用了H100/HBM3
GPU進行兩種系統配置測試:
・搭載H100/HBM3 GPU的LPDDR5X系統(NVIDIA Grace Hopper超級晶片)
・標準DDR5系統,我們安裝了相同的H100/HBM3,以保持比較的一致性。
主要的區別在於互連效能:GraceHopper超級晶片具備整合的NVIDIA NVLink,提供900 GB/s的雙向頻寬,而標準DDR5系統的PCIe Gen5連接,則僅提供128 GB/s的雙向頻寬。
LPDDR5X系統的表現遠超過DDR5系統:
・互連速度(CPU-GPU) 提升7倍
・設備(Device)與主機(Host)之間的傳輸速度達346 GB/s,主機與設備間達334 GB/s,DDR5則只有55 GB/s(單向)
・推論吞吐量提升5倍(圖10)
・推論延遲降低80%(圖11)
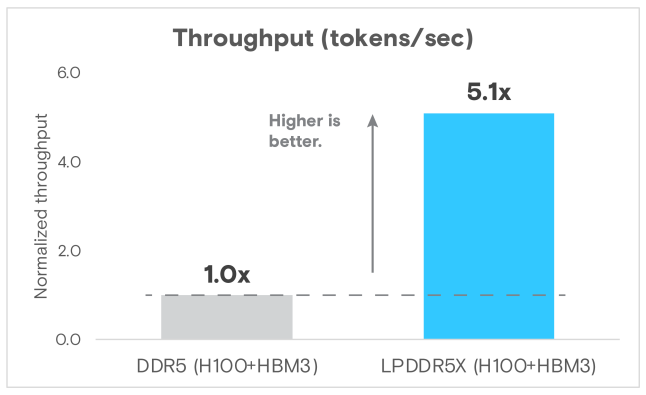 圖10 Llama 3 70B推論的標準化吞吐量(token/sec)
圖10 Llama 3 70B推論的標準化吞吐量(token/sec)
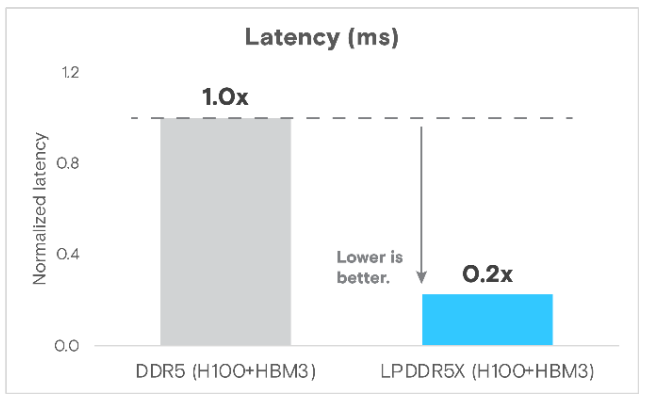 圖11 Llama 3 70B推論的標準化延遲(ms)
圖11 Llama 3 70B推論的標準化延遲(ms)
在電力和能效方面,我們觀察到LPDDR5X系統不僅能更快速地完成推論任務, 且功耗及能耗更低。LPDDR5X DRAM的功耗相比DDR5DRAM低了60%(圖12)。總體而言,LPDDR5X DRAM在multichase微基準測試和高效能計算(HPC)中的功率分別節省約77% 和75%,即LPDDR5X在所有工作負載中均較DDR5模組具顯著功耗優勢。
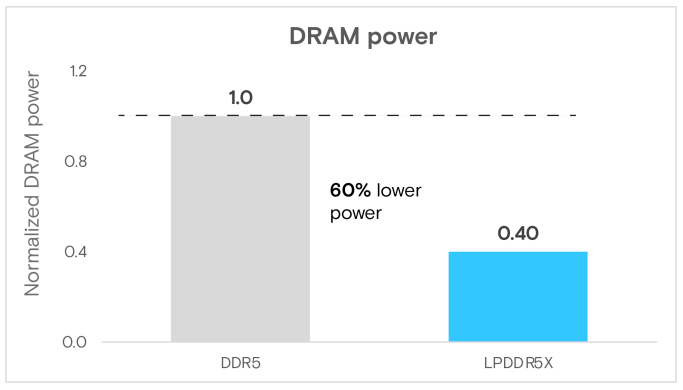 圖12 Llama 3 70B推論的DRAM功耗
圖12 Llama 3 70B推論的DRAM功耗
將效能指標轉換為任務功耗後,LPDDR5X系統在每個任務上的功耗減少73%,充分證明其在大規模AI工作負載中的顯著效率優勢。雖然僅從CPU效能來看,DDR5系統更具優勢,但LPDDR5X系統的功耗效率,和透過NVLink實現的CPU-GPU整合,為下一代AI基礎設施提供了強大優勢(圖13)。任務功耗對於資料中心營運商尤其重要,他們既需要最佳化基礎設施部署的營運開支,同時還要能支援AI工作負載。
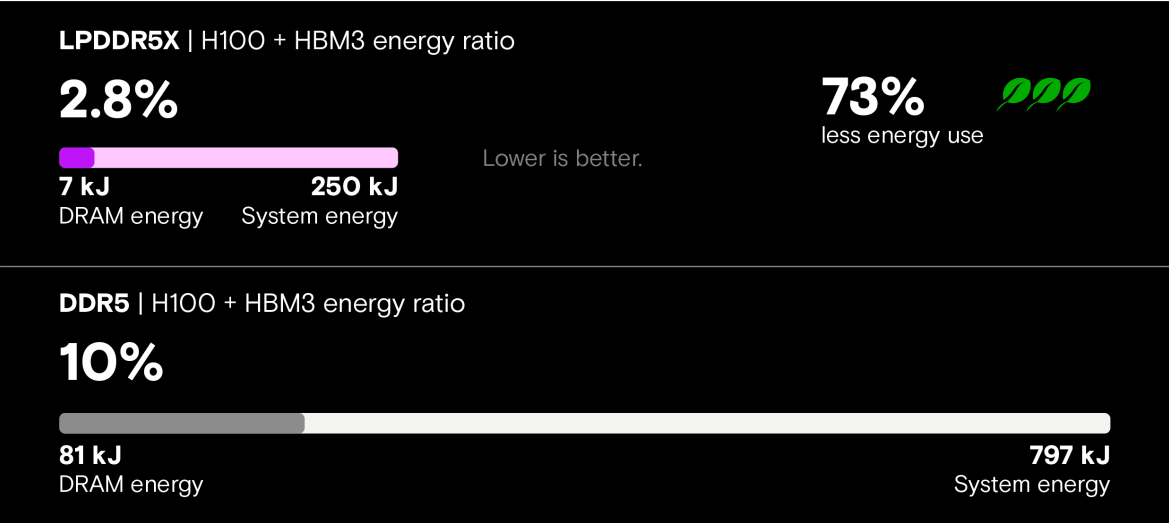 圖13 LLM推論能效
圖13 LLM推論能效
資料中心的未來
低功耗記憶體為重塑資料中心基礎設施帶來了機會,提供了一種能源效率更高的解決方案,以應對AI和高效能運算日益增加的運算及能源挑戰。我們對LPDDR5X的全面分析揭示了其在關鍵效能維度上的變革潛力:
・記憶體頻寬:效能提升高達36%
・應用程式執行時間:透過最佳化記憶體使用效率來增強效能
・能源效率:通過啟用更永續且節能的運算架構,將DRAM功耗減少77%
低功耗記憶體技術能夠幫助資料中心同時應對三個主要挑戰:日益增加的運算需求、能源成本以及環境永續性。
(本文作者均任職於美光科技)