從按鈕到語音操控,數位電視(DTV)不斷優化其互動方式。語者辨識(Speaker Identification)技術能根據語者的語音特徵來識別語者,為數位電視智慧化升級提供了新的契機。本文將探討於裝置端運行語者辨識功能的一項專案,分析其實作方式及實際效能。
近年來,我們與電視的互動方式發生了改變。過去,我們需要透過按壓多次按鈕來操控螢幕鍵盤,如今則可以直接透過語音進行互動。儘管這已經在相當程度上改善了數位電視(DTV)的使用者體驗,但仍有更多進一步提供沉浸式和引人入勝體驗的可能值得探索。試想,當你對著電視說「推薦一部電影」,或是「我今天有哪些行程」,電視能夠根據你的聲音識別你的身分,並提供個人化的回覆。這正是語者辨識(Speaker Identification)技術所能實現的功能。語者辨識技術是指根據語者的語音特徵,而非具體的話語內容來識別語者的過程。
語者識別技術背景說明
當前的人工智慧(AI)趨勢正在推動新模型不斷擴大其規模並提高效能。雖然這些大模型能夠帶來令人矚目的結果,考慮其高昂的成本、潛在的安全風險和延遲問題,邊緣AI仍有機會成為更具吸引力的解決方案。
語者識別(Speaker Recognition)旨在解決兩個主要任務,即語者辨識(Speaker Identification)和語者確認(Speaker Verification)。語者辨識從已錄入的資料庫中辨識語者的身分;語者確認則用於驗證說話者是否確實是他們所宣稱的人物,主要用於安全應用。語者辨識是一個開放集問題(Open Set Problem),即語者可以是系統中已錄入的已知使用者,也可以是未知的語者或是「來賓帳號(Guest)」語者。
語者辨識技術已問世多年,而近期所採用的深度神經網路(DNN)顯著提升了該技術的識別精度。本文將介紹採用DNN進行語者辨識的研究項目成果。這項技術能夠在不依賴雲端推論(Inference)的情況下,在基於Arm平台的裝置上運行。首先,本文將就語者辨識系統的工作原理進行總體概述,再深入探討此專案中使用的設計和實現方法。本文將討論關鍵的效能結果和量化部分,並在結論部分概述研究發現,並指出具有發展前景的研究方向。
基於DNN的語者辨識系統如何運作?
圖1展示了典型的語者辨識系統。如圖1所示,原始音訊輸入被傳遞到預處理階段,以提取音訊的關鍵特徵。經過預處理的音訊接著將被傳遞到模型中,由模型進行嵌入提取(Embedding Extraction)。模型會輸出輸入音訊的向量表示,稱為嵌入(Embedding)。
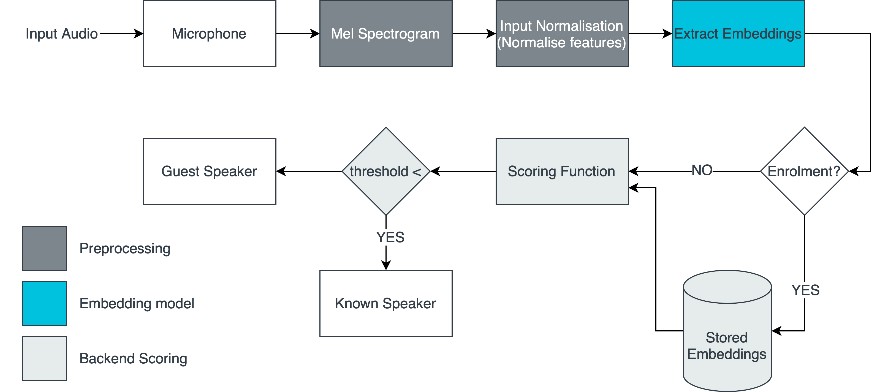 圖1 典型的語者辨識系統
圖1 典型的語者辨識系統
嵌入可以使用評分函數(Scoring Function)進行比較,評分函數通常為餘弦相似度(Cosine Similarity)[1],分數越高,表示兩個嵌入越相似。如果得分高於某個臨界點,就可以判定這兩個嵌入的語者是同一個人。
設計與實作
模型細節
在為此專案研究合適的模型時,考慮了以下幾項因素:模型大小、模型精度、推論時間。最終,實作方案使用了TitaNet Small模型,該模型係基於Koluguri等人在2021年發表的論文《TitaNet:利用一維深度可分離卷積和全域上下文的語者表示神經模型》[2],以及Han等人在2020年提出的ContextNet編碼器-解碼器架構[3]。此外,該模型採用了附加角邊際損失(Additive Angular Margin Loss)進行端到端訓練,有助於優化語者嵌入之間的餘弦距離。
TitaNet Small模型的大小只比TitaNet Large的一半再多一點,論文報告的誤差分別為1.15%和0.68%。這代表TitaNet Small在模型大小和精度之間進行良好取捨,即使在資源有限的環境中,也能提供優異的推論時間。
與大多數基於語音的機器學習(ML)模型一樣,TitaNet Small不接受原始音訊作為輸入,需要經過預處理,才能針對音訊特徵進行運算。此專案中採用了梅爾頻譜(Mel Spectrogram)[4]音訊處理技術。
在語者辨識系統中,支援不同長度的音訊輸入是實用的功能。特別是在錄入過程中,使用者可以隨時停止錄音。這代表著專為處理音訊而設計的ML模型通常將動態軸(Dynamic Axes)作為輸入,使其能夠處理不同長度的音訊輸入。可惜的是,許多可用的TensorFlow Lite(TFLite)推論後端對動態輸入軸的支援有限,有些甚至根本完全不支援。
此應用圍繞具有動態輸入的模型而設計,不過,也同時匯出了一個固定軸(Fixed Axes)模型,以便在僅支援固定軸的GPU委派(GPU Delegate)上測試TFLite的推論。測試結果將於本文的後半部分進行說明。
實作
圖2展示了應用結構的總體方塊圖(High-level Block Diagram)。該應用是為安卓系統所開發,但軟體堆疊可以輕鬆移植到其他熱門的數位電視作業系統上。大部分應用邏輯和效能關鍵型工作都由應用的C++層處理。TitaNet Small模型最初使用PyTorch框架開發。雖然PyTorch適合測試和開發模型,但為了盡可能提高邊緣端的推論效能,該模型被轉換為TFLite。
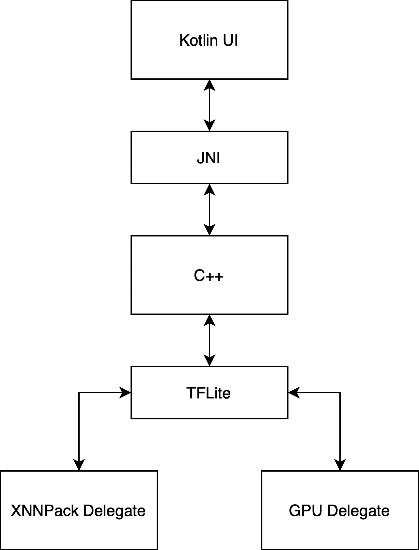 圖2 應用結構的總體方塊圖
圖2 應用結構的總體方塊圖
轉換ML模型通常頗具挑戰。雖然有許多可用的工具,但要找到支援模型運算子的合適工具並非易事。在此專案中,模型首先被匯出為ONNX格式,接著使用「onnx-tensorflow」[5]工具將其轉換為TensorFlow模型。

轉換為TensorFlow格式後,使用TensorFlow函式庫提供的TFLiteConverter來匯出TFLite模型。此外,也利用TFLite的訓練後量化優化功能生成了一個量化模型。
此應用支援預錄音訊和即時音訊。圖3是預錄資料頁面的截圖。如圖3所示,當所選的兩個音訊片段來自同一語者時,系統驗證結果顯示吻合;當所選的兩個音訊片段來自不同語者時,系統報告為不同語者。
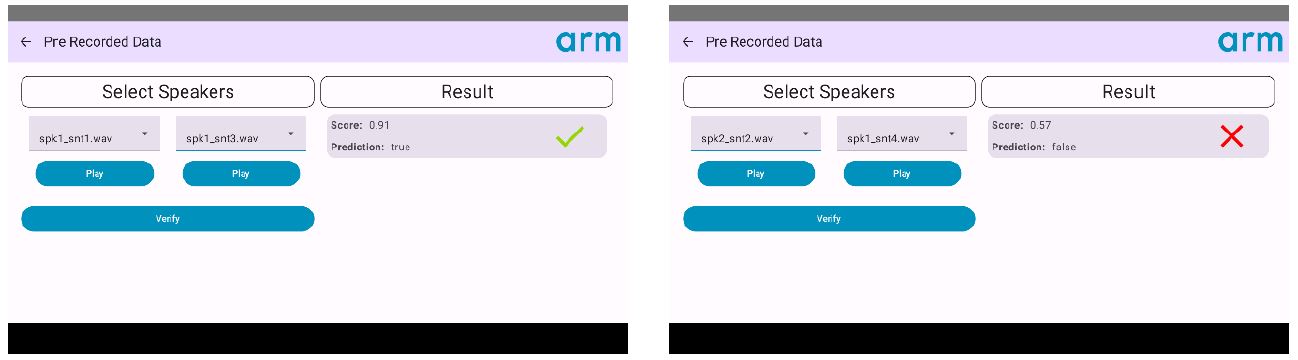 圖3 預錄資料頁面
圖3 預錄資料頁面
在即時資料模式下,該應用可透過分析即時音訊輸入來識別語者。麥克風會持續錄製傳入的音訊,當錄製的音訊足夠多時,就會執行辨識管線(Identification Pipeline)。新使用者可以註冊進入系統(圖4)。如果無法識別語者,系統將顯示檢測到未知語者。
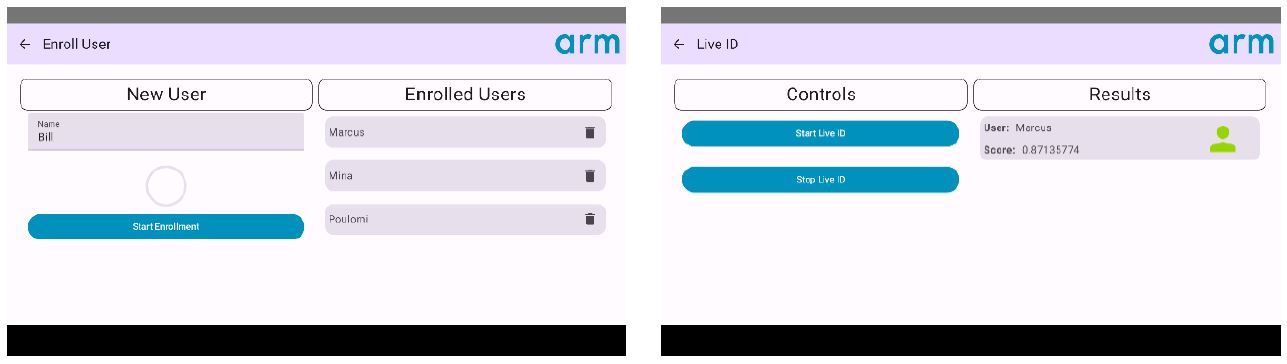 圖4 新使用者註冊和辨識
圖4 新使用者註冊和辨識
模型量化/高效能處理器助攻 裝置端語者辨識革新DTV互動體驗(1)
模型量化/高效能處理器助攻 裝置端語者辨識革新DTV互動體驗(2)
參考資料
[1] https://builtin.com/machine-learning/cosine-similarity
[2] https://arxiv.org/abs/2110.04410
[3] https://arxiv.org/abs/2005.03191
[4] https://medium.com/analytics-vidhya/understanding-the-mel-spectrogram-fca2afa2ce53
[5] https://github.com/onnx/onnx-tensorflow