人工智慧/機器學習(AI/ML)應用快速成長,使得資料中心網路面臨顯著增加的資源需求。訓練具有數萬億個參數的大型語言模型(LLM)需要大量的AI加速資源,例如GPU,而GPU之間的資料傳輸效率也是訓練LLM的關鍵因素。
Rail/Domain流量的H-score
(承前文)LLM叢集中應該有一個分散式可觀察/監控架構。該架構包括一個負責運行整體流量監控服務的叢集控制器或主節點(Master Node),以下將其稱為healthd。每個Rail交換器或互連Domain皆應監控並收集其流量負載,定期向healthd回報。接著,healthd將整合並正規化來自Rail和Domain的資料,給出介於0%和100%之間的值作為流量健康分數,並將此資訊儲存於整體注冊表中,如Kubernetes叢集中的etcd、Apache ZooKeeper或Consul。
由於壅塞檢測可能為平台特定方案,如ECN/PFC或DCQCN,需要注意本文提出的機制獨立於任何特定的健康分數計算機制。另外也須注意,H-score的收集和分配發生在控制平面(Control Plane),不會影響資料平面(Data Plane)的即時流量路由或轉發速度。此外,流量趨勢分析需要時間,因此分散式計算H-score不一定是即時的。
在此機制中,每個GPU皆與整體注冊表同步,並維護局部注冊表快取(Cache),允許每個GPU隨時查詢特定Rail「r」的健康得分,即H(r),或是Domain「d」的健康得分,即H(d)。經過正規化處理後,0<=H(r)<=1,0<=H(d)<=1。健康分數值越低,代表壅塞情況越嚴重。
LLM叢集中的網路路徑p是串接Domain/Rail元件的序列,表示為p=c1°c2°... Cm。路徑中的每個元件c表示為c∈p。現在,可以將網路路徑p的H-score定義為所經過之每個區段的H-score乘積。
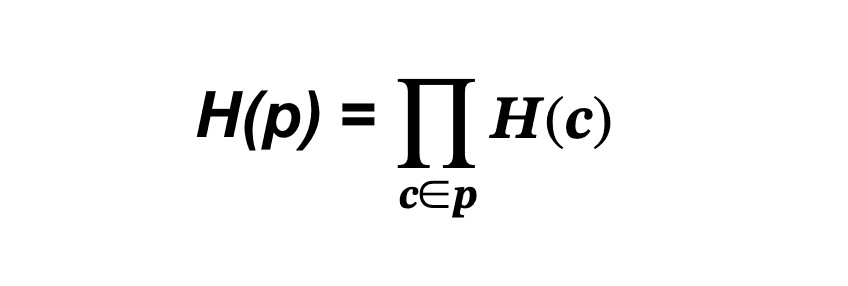
根據上面的公式,當一個元件的健康分數降低時,路徑的健康分數也會按比例降低。由於元件彼此之間具有串接序列關係,當一個元件的健康分數幾乎為零(受阻)時,整個路徑的健康分數也將為零(受阻)。當所有元件的健康分數皆為1(100%健康)時,整個路徑的健康分數也將為1(100%健康)。因此,這個簡單的公式可以合理地模擬路由路徑的流量狀況。
例如,在案例一中,由於G1和G2之間的路徑只經過Domain d,因此其健康分數同樣為H(d);在案例二中,G1和G2之間的路徑只經過Rail r,其健康分數為H(r)。如果一條路徑先經過Domain d1,接著通過Rail r1抵達Domain d2,再通過Domain d2抵達目的地GPU,那麽這條三跳路徑的健康分數即為H(d1)*H(r1)*H(d2)。需要注意的是,如果目的地直接連接至Rail r1,則在計算路徑健康分數時不應涉及Domain流量情況,因此H(p)=H(d1)*H(r1)。
Rail/Domain流量的H-ratio
除了H-score,也將為叢集中的每個GPU G(d, g)導入另一個關鍵指標:健康比率,或稱H-ratio,𝛾。計算方式如以下公式所示。
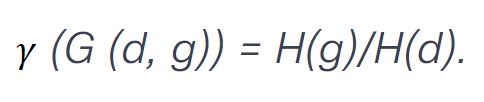
此處假設LLM Domain的值永不為零,否則相應GPU的𝛾值將為無限,代表該Domain被完全阻塞,無法在該Domain執行任何LLM操作。
藉由H-ratio指標,即可輕鬆確定案例三中G1的路由(圖5):

為了驗證此方法的正確性,我們知道,當選擇GPU1的r介面作為Next Hop時,其路徑p1可以表示為p1=g1°d2,而另一個選擇,即p2,可以表示為p2=d1°g2。因此,兩種路徑的健康分數為H(p1)=H(g1)*H(d2);H(p2)=H(d1)*H(g2)。由於𝛾(G1)>𝛾(G2),根據𝛾的定義,可得知H(g1)/H(d1)>H(g2)/H(d2),即H(g1)*H(d2)>H(g2)*H(d1)。因此,H(p1)=H(g1)*H(d2)>H(d1)*H(g2)=H(p2),如此一來便可選擇H-score較高的路徑。
換句話說,當目的地GPU的H-ratio低於來源GPU的H-ratio時,就H-ratio而言,在向下游移動LLM工作負載時會選擇r介面;而就H-ratio而言,在向上游移動LLM工作負載時則會選擇d介面。
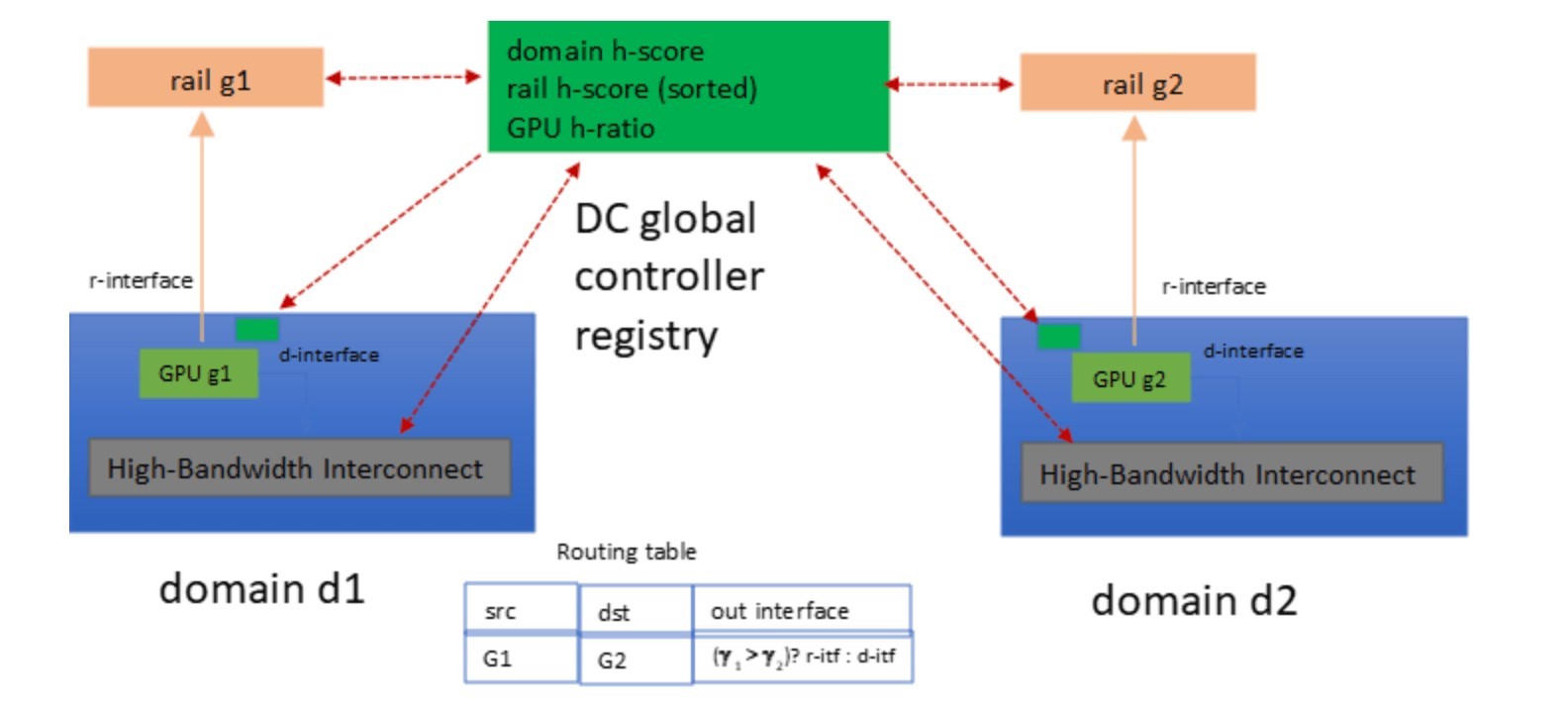 圖5 基於H-ratio的GPU之間的路由
圖5 基於H-ratio的GPU之間的路由
新興架構助攻AI/ML流量傳輸
本文基於先進的資料中心網路拓撲,提出了一種新穎的AI/ML工作負載路由架構,該架構具有通用的流量狀況指標,適用於生成式AI訓練,如LLM。
此架構可根據H-score指標捕捉高頻寬Domain和Rail交換器的流量健康(或壅塞)狀況趨勢,可用於推導Rail-only拓撲中端到端路徑的流量狀況,形成一個自洽、直觀,並且能夠高效實施的模型。此外,也導入𝛾指標,顯示每個GPU上一對介面的健康比率。研究發現,可以根據來源GPU和目的地GPU的指標值是增加還是減少來確定最佳路徑,與所經過的中間節點無關。此發現大幅簡化了路由決策,並能在動態流量條件下實現高效的工作負載移動。
為確保資料平面的路由效率,此方案加入分散式注冊表,用於儲存Domain和Rail的H-score,以及從叢集中GPU推導得出的H-ratio。這些信息不僅在整體系統層面儲存於資料中心控制器,也作為控制平面上的注冊表快取儲存在本地局部端的GPU中。
由於此方法依賴LLM叢集中每個Rail/Domain的H-core值,和Rail及Domain的內部互連拓撲及實作無關。此機制也與H-core和壅塞檢測的演算法無關,可以使用ECN/PFC、DCQCN或任何其他特定平台的方法。
(本文作者為Cisco主任工程師)
參考資料
[1] Nvidia dgx superpod: Next generation scalable infrastructure for ai leadership, reference architecture, 2023.
[2] “How to Build Low-Cost Networks for Large Language Models (Without Sacrificing Performance)?” A paper on an efficient networking architecture for GPU/LLM, 2023.
[3] “On the Impact of Packet Spraying in Data Center Networks.” A paper on packet spraying in Data Center Networks.
找出最佳GPU傳輸路徑 路由機制提升AI/ML工作負載效率(1)
找出最佳GPU傳輸路徑 路由機制提升AI/ML工作負載效率(2)