至今全世界的電腦仍採用「馮紐曼架構」,然而,此架構會導致所謂的馮紐曼瓶頸,且近年對電腦運算速度的要求越來越高,越來越多資料密集型應用,譬如機器學習、人工智慧、神經網路和生物系統等,為了突破這樣的瓶頸,記憶體內運算因此應運而生。近年來人工智慧的興起,恰巧記憶體內運算非常適用於人工智慧的硬體加速,兩者之間相輔相成,加速其發展。
1945年6月,是現代電腦科學的里程碑。著名的美籍猶太裔數學家馮紐曼(John von Neumann)發表了一篇長達101頁的報告《First draft of a report on the EDVAC》,即電腦史上著名的「101頁報告」,其捨棄十進制而改以二進制運算,提出所謂內存程式(Stored Program)的架構,將儲存裝置與中央處理器分開的概念。
馮紐曼傳統電腦架構
1951年,EDVAC(Electronic Discrete Variable Automatic Computer)電腦宣告完成,它是第一台使用記憶體來儲存處理器指令與資料的通用計算機,至今全世界的電腦皆仍採用「馮紐曼架構」。由於他在電腦邏輯結構設計上的偉大貢獻,被譽為「電腦之父」。
在馮紐曼架構的電腦中,電腦被分成了五大單元,如圖1所示,分別稱作「控制器」、「運算邏輯器」、「記憶體」、「輸入設備」與「輸出設備」。「輸入設備」是用來將外部資料輸入到電腦,比如鍵盤、滑鼠。「輸出設備」是將電腦內部的資料輸出到外部,比如螢幕、印表機。「記憶體」儲存中央處理器的指令與資料,當中央處理器要存取資料時,會藉由位址到記憶體裡存取其需要的資料。
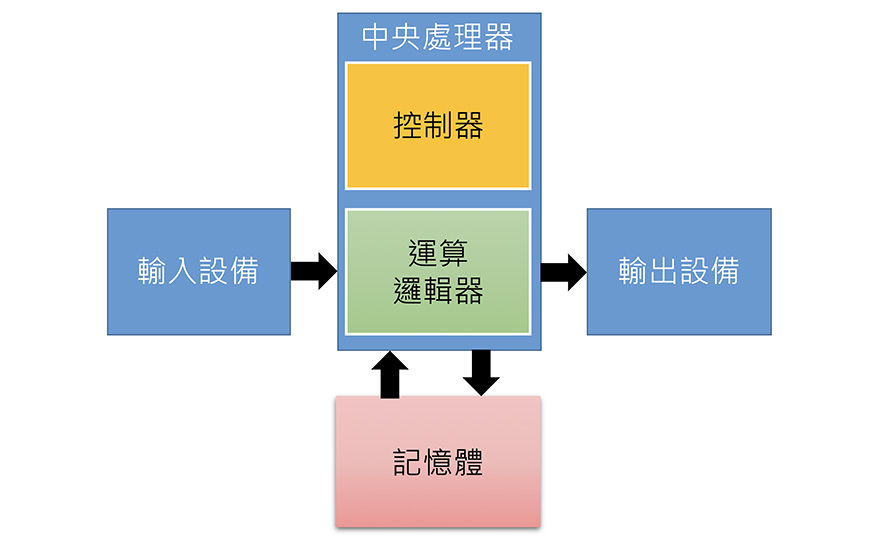 圖1 馮紐曼架構
圖1 馮紐曼架構
然而,將中央處理器與記憶體分開會導致所謂的馮紐曼瓶頸(Von Neumann Bottleneck),如圖2所示。在現代電腦中,記憶體的容量遠大於在中央處理器與記憶體之間的資料傳輸量,中央處理器的效能也遠高於記憶體的資料傳輸量,當中央處理器需要在巨大的資料上執行簡單指令時,中央處理器必須至記憶體拿取資料,若資料傳輸的速度無法趕上中央處理器運算速度,中央處理器會在資料傳輸時閒置,造成整體性能的降低,縱使在中央處理器與記憶體間加入快取記憶體能緩解馮紐曼瓶頸對性能造成的問題,但因中央處理器速度和記憶體傳輸速率差距越劇大,瓶頸問題便越來越嚴重,因此記憶體內運算就此應運而生。
 圖2 馮紐曼瓶頸
圖2 馮紐曼瓶頸
記憶體內運算
近年對電腦運算速度的要求越來越高,擴大了記憶體內運算的市場,越來越多資料密集型應用,譬如機器學習、人工智慧、神經網路和生物系統等,為了克服傳統的馮紐曼架構的限制,記憶體內運算是現今其中一種追求的架構。將簡單的邏輯運算移至記憶體陣列中,記憶體不再只是儲存資料,還能在記憶體內執行簡單的運算,執行完後,再將資料傳到中央處理器,也就是搬移運算後的結果,而非只是搬資料至中央處理器後才做運算,如此能減少資料搬移所造成性能和功率的損失,如圖3所示。
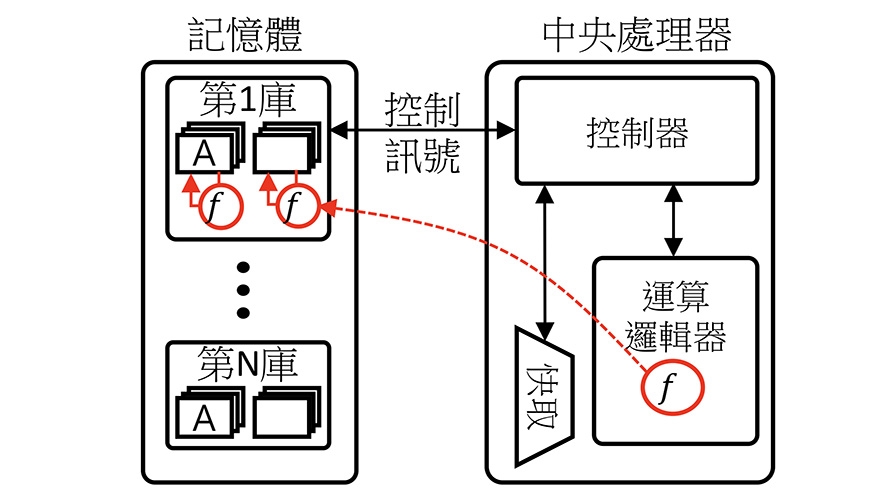 圖3 記憶體內運算
圖3 記憶體內運算
在[1]中,提出了可重組式的靜態隨機存取記憶體,此記憶體單胞由六個電晶體所組成,它除了有原本的靜態隨機存取記憶體功能外,還能組成二元內容可定址記憶體和三元內容可定址記憶體,除此之外,它能執行兩個字組以上的AND或NOR位元運算子。在[2]中,針對記憶體內運算提出了特殊的靜態隨機存取記憶體,此記憶體單胞也是由六個電晶體所組成的,也能組成二元內容可定址記憶體和三元內容可定址記憶體,且它能執行的位元運算子為AND、OR或XOR。在[3]中,使用了十個電晶體的靜態隨機存取記憶體和修改的周邊電路,實現了AND、OR或XOR的位元運算以及左移動運算和左旋轉運算。在[4]中,提出的八電晶體和九電晶體靜態隨機存取記憶體能執行NAND、NOR、IMP、XOR多種位元運算子,此外,更提出「讀取計算後再儲存」的方法,不需先鎖住資料再執行後續的寫入動作,其能在執行完位元運算後,直接存入記憶體,以此提升性能。
美國聖母大學(Notre Dame)電子工程系系主任Suman Datta說「在我們學術界大多數的人認為,新興記憶體將成為實現記憶體處理器(Processor-in-memory)的技術之一。採用新的非揮發性記憶體將意味著創造新的使用模式,而記憶體內運算架構將是關鍵之一。」已有許多研究發表使用新興記憶體電組特性達成記憶體內的算術運算,在[5]和[6]中,提出具有成本效益的記憶體內運算方法,其在自旋轉移扭矩磁阻隨機存取記憶體(STT-MRAM),利用已經存在的周邊電路或修改周邊電路,不需在記憶體晶片上增加任何運算單元,就能執行NOT、AND、NAND、OR和NOR的位元邏輯運算。此外,[6]還能執行XOR和ADD的運算,並且針對此種記憶體內運算時的錯誤做偵測和修正。
看見近年來有許多的研究,都在探討記憶體內運算,可見記憶體內運算是目前發展的趨勢,想必在未來會有顯著的成長,投入開發的廠商也會越來越多。然而,目前當然還有許多必須克服的困難,其相關的標準也尚未建立完成,使得記憶體內運算仍需段時日發展,透過各軟、硬體廠商來整合。不過因其所展現出來的驚人運算效能,將持續吸引各界投入心力,未來記憶體內運算勢必會在電腦的歷史頁寫下一重大革新。
記憶體內運算應用於AI加速器
由於傳統的計算方式是先將資料從遠端使用者傳輸並載入至記憶體暫存,中央處理器再到記憶體讀取資料,做完運算後存回記憶體,再經由記憶體傳輸回遠端使用者。如此的處理程序對於人工智慧的運算並非那麼合適,因為人工智慧需要處理大量資訊,並執行多種運算,例如:卷積、池化、全連接等,如圖4所示,若使用傳統的運算方式,會花費很多時間在中央處理器和記憶體之間資料的傳輸上,因此,記憶體內運算的概念被看重。新創公司、企業巨擘和學術界都認為記憶體內運算是人工智慧的理想選擇,此策略適合用於新型的人工智慧加速器,能使其速度大大提升。利用開發在記憶體內的高速運算功能,並分別放在資訊傳輸端以及中央處理器以外做高速運算。這樣可達到即時運算以及分散中央處理器的工作,更可達到邊緣運算的需求。
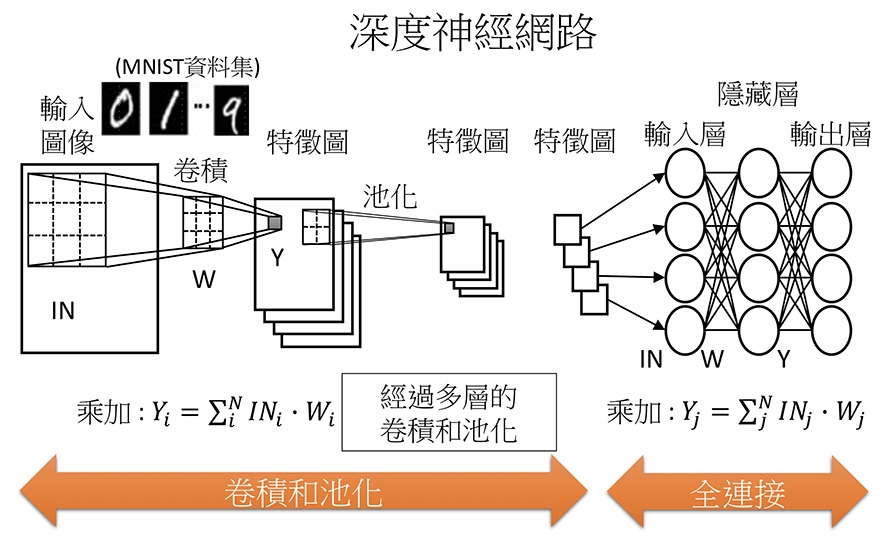 圖4 深度神經網路例子
圖4 深度神經網路例子
由於記憶體內運算也無法執行過於複雜的運算,因此只能將簡單的運算植入記憶體中,而人工智慧剛好非常適合發展記憶體內運算,因為人工智慧需要大量的乘積運算,將這些相對簡易的運算,利用記憶體內運算的大量平行運算並減少其傳輸所消耗的時間,便能很有效的提升整體性能,對於發展邊緣運算有著實的幫助。
圖5是將記憶體內運算應用於神經網路加速器的例子,左邊是傳統深度神經網路加速器,處理元件由暫存器、乘加器和控制器組成,其需要靠共享靜態隨機存取記憶體和動態隨機存取記憶體快取,資料搬移的時間會占用大量的總體時間而造成運算效能變差,特別是運用在即時辨識時,其無法應用於真實的情況中;而右圖將記憶體內運算使用於神經網路加速器,資料直接於記憶體內運算並提升其平行度,此舉可大大減少資料搬移時間,使效能明顯提升。
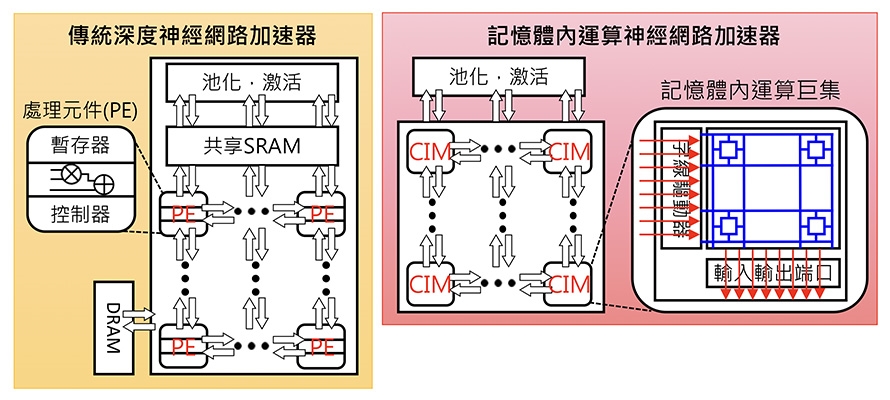 圖5 將記憶體內運算應用於神經網路加速器
圖5 將記憶體內運算應用於神經網路加速器
近年來,也有許多針對人工智慧運算的特性,開發記憶體內運算的記憶體先後被提出。在[7]中,六個電晶體的靜態隨機存取記憶體結合被修改的周邊電路後,使之能執行機器學習的分類功能。在[8]中,六個電晶體的靜態隨機存取記憶體結合修改後的周邊電路能計算二元神經網路。在[9]中,藉由靜態記憶體陣列裡實現二元卷積,能使修改後的馮紐曼機制得以加速深度二元網路。在[10]中,標準的八電晶體靜態隨機存取記憶體可以被組成類類比的記憶體內多位元內積引擎,藉由供應適當的類比電壓給讀取端口並檢測輸出電流,其提出兩種組態使之不須修改標準的八電晶體靜態隨機存取記憶體就能達到類類比的內積加速器需求。在[11]中,提出了神經憶阻性系統,是憶阻性以交錯閂(Cross Bar)為基底的神經網路運算系統,比起傳統的馮紐曼系統,它有更好的能量和面積的效率,其提出的神經憶阻性系統加速器相對於多核心精簡指令集運算處理器,更是減少五個數量級的功耗。
老將新秀爭相卡位兩大記憶體內運算模式登場
各界都早已著手開發適合記憶體內運算的記憶體。主要可以分為兩大類,包括揮發式記憶體以及非揮發式記憶體。揮發式記憶體分為靜態存取記憶體和動態存取記憶體,靜態存取記憶體在製程和速度擁有優勢,而動態存取記憶體也有容量大、成本低且大頻寬的優勢。但缺點都是無法長期記錄資料。而非揮發式記憶體例如快閃式記憶體、電阻式記憶體、相變式記憶體與磁性記憶體等。
由於電阻式記憶體以及相變式記憶體具有低功耗、高速之優點,更加適合應用於邊緣運算。其中利用電阻式記憶體發展類神經網路的計算更是受人矚目。科技部的半導體射月計畫的人工智慧領域發展藍圖中,記憶體內運算是重點發展項目之一。其中包含了記憶體元件開發、電路設計,演算法以及介面技術。結合台灣政府、學術界和業界的力量,台灣必定會在人工智慧的領域中占有一席之地。
(本文作者任職於工研院資訊與通訊研究所;該文也於工研院資通所《電腦與通訊》期刊刊登)
