2016年底,Google TPU團隊中有幾位核心的開發者低調出走並創辦了一家名為Groq的機器學習系統公司。Groq的聯合創始人同時也是現任執行長Jonathan Ross,先前便任職於Google的張量處理器(TPU)開發團隊。
Groq許多高層都曾是Google的資深員工,這家AI加速器新創公司擁有70名員工,迄今已募集了6,700萬美元資金,並已完成了第二輪募資。最近他們帶著一款名為張量流處理器(Tensor Streaming Processor, TSP)的晶片架構出現在公眾視野裡。
Groq的TSP架構是專為電腦視覺、機器學習和其他人工智慧相關工作負載的效能要求設計的,它既可以支援傳統的機器學習模型,也可以支援新的機器學習模型,非常適合用於廣泛應用的深度學習推理處理;加上其簡單性,使其成為處理任何高性能、數據或運算密集型工作負載的理想平台。再者,該架構在單顆晶片上可以實現每秒1,000兆(10的15次方)次運算,是全球首個實現該級別效能的架構,其浮點運算效能可達每秒250兆次(TFLOPS),此架構的優勢是可消除由於同步(Synchronization)而導致的等待時間。本文以下介紹Groq的核心技術、並洞悉其專利技術的優勢所在。
TSP晶片架構
TSP為一種可加速神經網路的架構方法,可將數百個功能單元匯集在單一核心內。TSP架構是一種功能切片的微體系結構,其記憶體單元係以向量和矩陣深度學習功能單元交織在一起,以便利用其深度學習操作的數據流局部性的優勢。如圖1所示,TSP將圖1(a)中之核的同構二維網格(Homogeneous Two-dimensional Mesh)重組為圖1(b)中所示之功能切片的微體系結構。在這種方法中,每個圖磚(Tile)都實現了特定的功能,並在二維片上網格的Y維度上垂直堆疊為切片(Slice)。基於TSP有兩個主要特徵,第一,機器學習工作負載展現出豐富的數據並行性,可以很容易地映射到硬體中的張量;第二,具有生產者-消費者流編程模型(Producer-consumer Stream Programming Model)之簡單且確定性(Deterministic)的處理器,可以對硬體組件進行精確的推理和控制,進而實現良好的性能和電源效率[1]。Groq基於此TSP架構設計了功能強大的單線程流處理器,並配備了專門設計的指令集,以利用張量操縱(Tensor Manipulation)和張量移動(Tensor Movements)的優勢,從而可以更高效地執行機器學習模型。
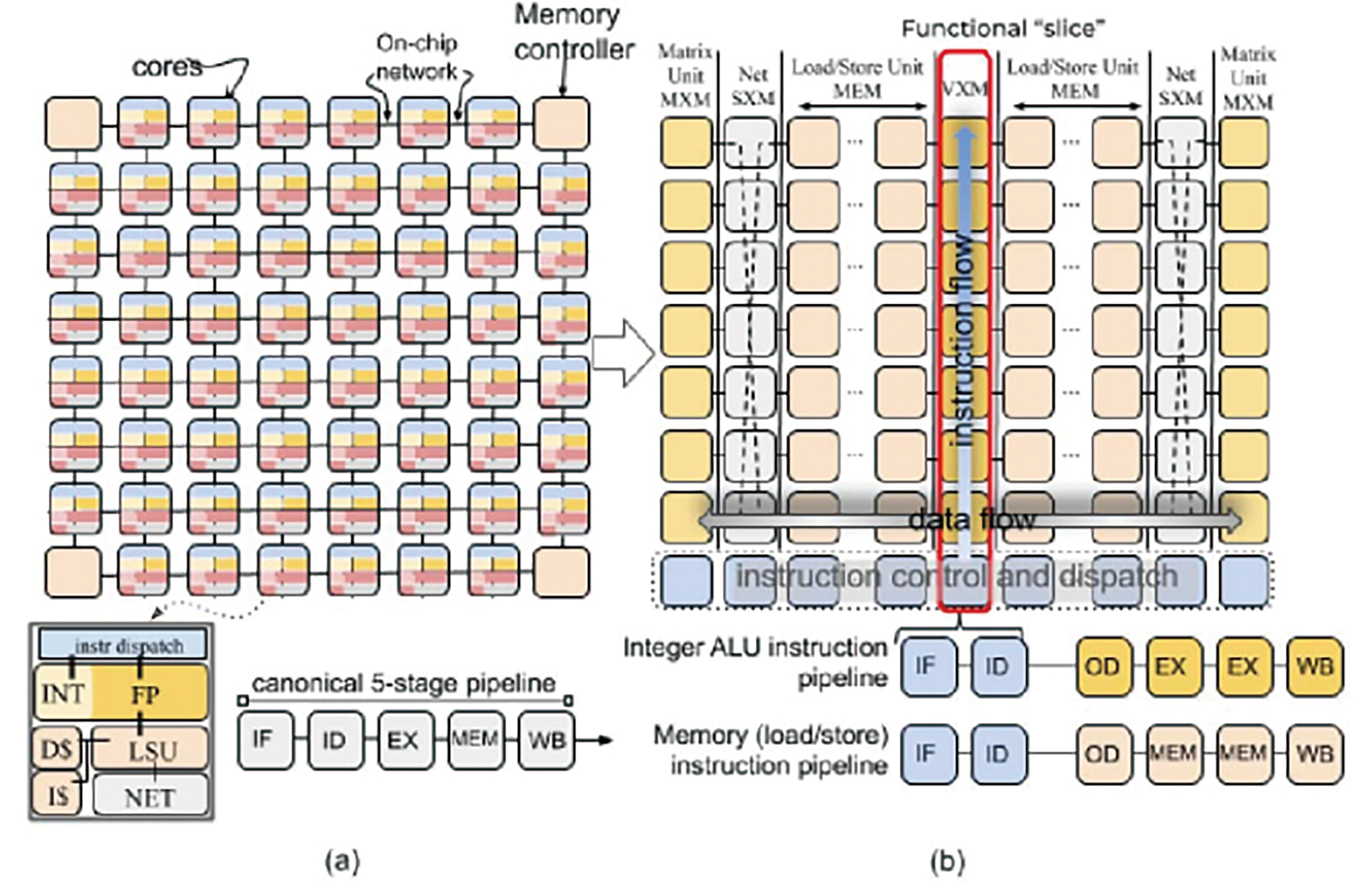 圖1 TSP架構:二維核心網格(a)重組為功能切片的圖磚(b)
圖1 TSP架構:二維核心網格(a)重組為功能切片的圖磚(b)
TSP架構受到「軟體優先(Software-first)」的概念啟發,為運算靈活性和大規模平行運算提供了一種新穎的方法,可在所需的功率範圍內在機器學習工作負載上實現快速但可預測的性能,稱之為「軟體定義的硬體(Software-Defined Hardware)」,如圖2所示,所有執行計畫都在軟體中進行,從而釋放了寶貴的晶片空間,並為記憶體頻寬(Memory Bandwidth)提供了額外的快取(Cache),也就是先構建一個原型編譯器而非硬體原型;硬體架構是圍繞著編譯器打造,由此產生的TSP有一個簡化的硬體設計,但所有的執行計畫都在軟體中進行。軟體實質上協調了所有資料流和時序,從而確保運算不會停頓,而且延遲和性能都是可預測的。Groq的軟體將張量流模型或其他深度學習模型編譯為獨立的指令流,這些指令流可提前得到高度協調(Coordinated)。工作流程來自編譯器。它可以提前確定並計畫整個執行,從而實現非常確定的運算[2]。
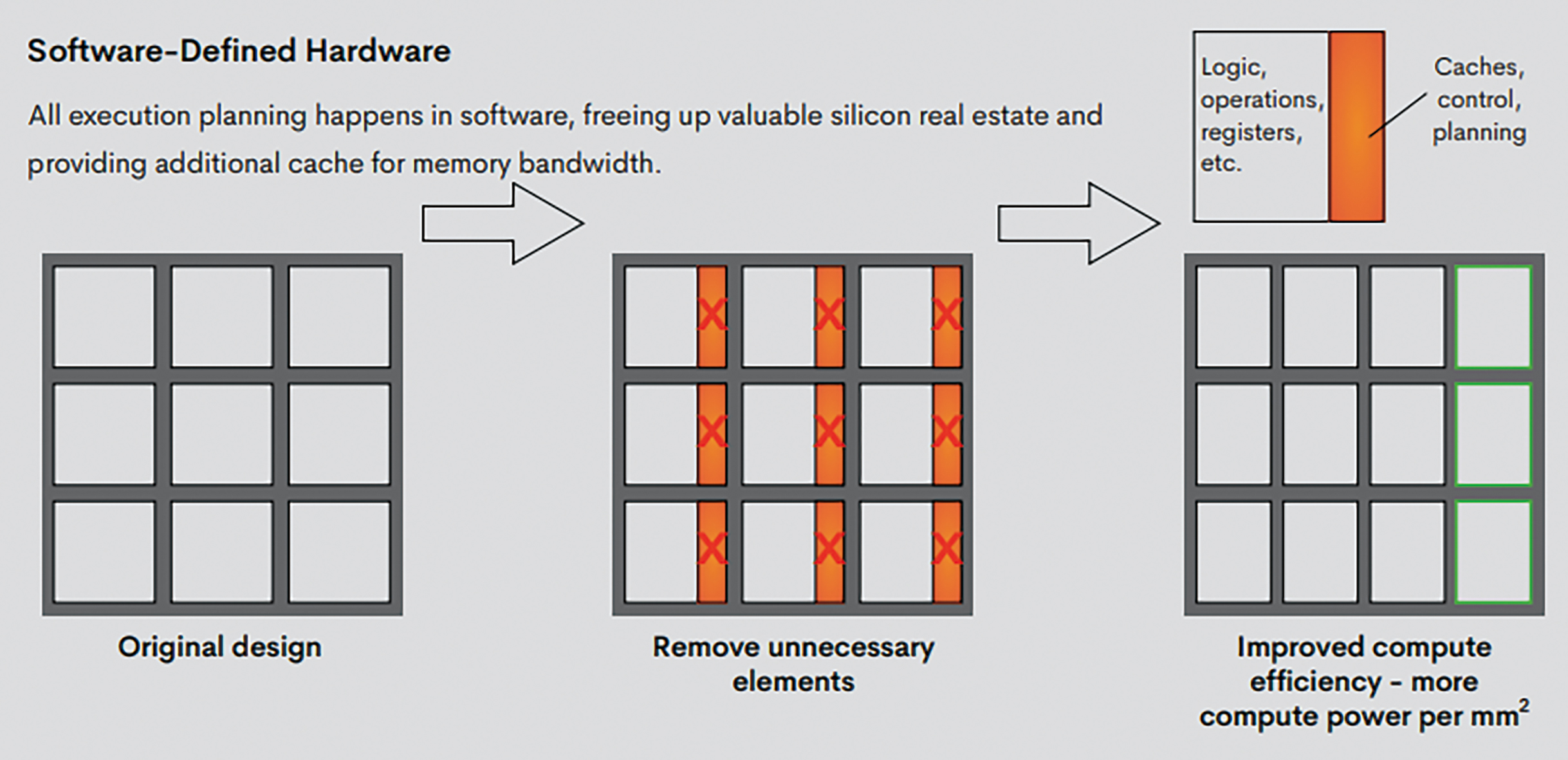 圖2 Groq之軟體定義的硬體概念
圖2 Groq之軟體定義的硬體概念
資料來源:Groq官網
Groq專利布局
圖3顯示Groq自2017年起開始申請專利,2019年達申請量高峰24件,從2018年至2019年呈現倍數增加趨勢(2019年後下降係因專利尚未公開所致)。目前全球專利數量為40件,圖4顯示其專利的申請國以美國為主,其次為申請WIPO(PCT專利)及台灣專利。圖5顯示Groq專利組合中三階國際專利分類碼(International Patent Classification, IPC)係以電子數位資料處理(G06F)為主,其次依序為基於特定運算模式之計算機系統(G06N)、一般編碼(H03M)、靜態儲存裝置(G11C)與脈衝技術(H03K)。
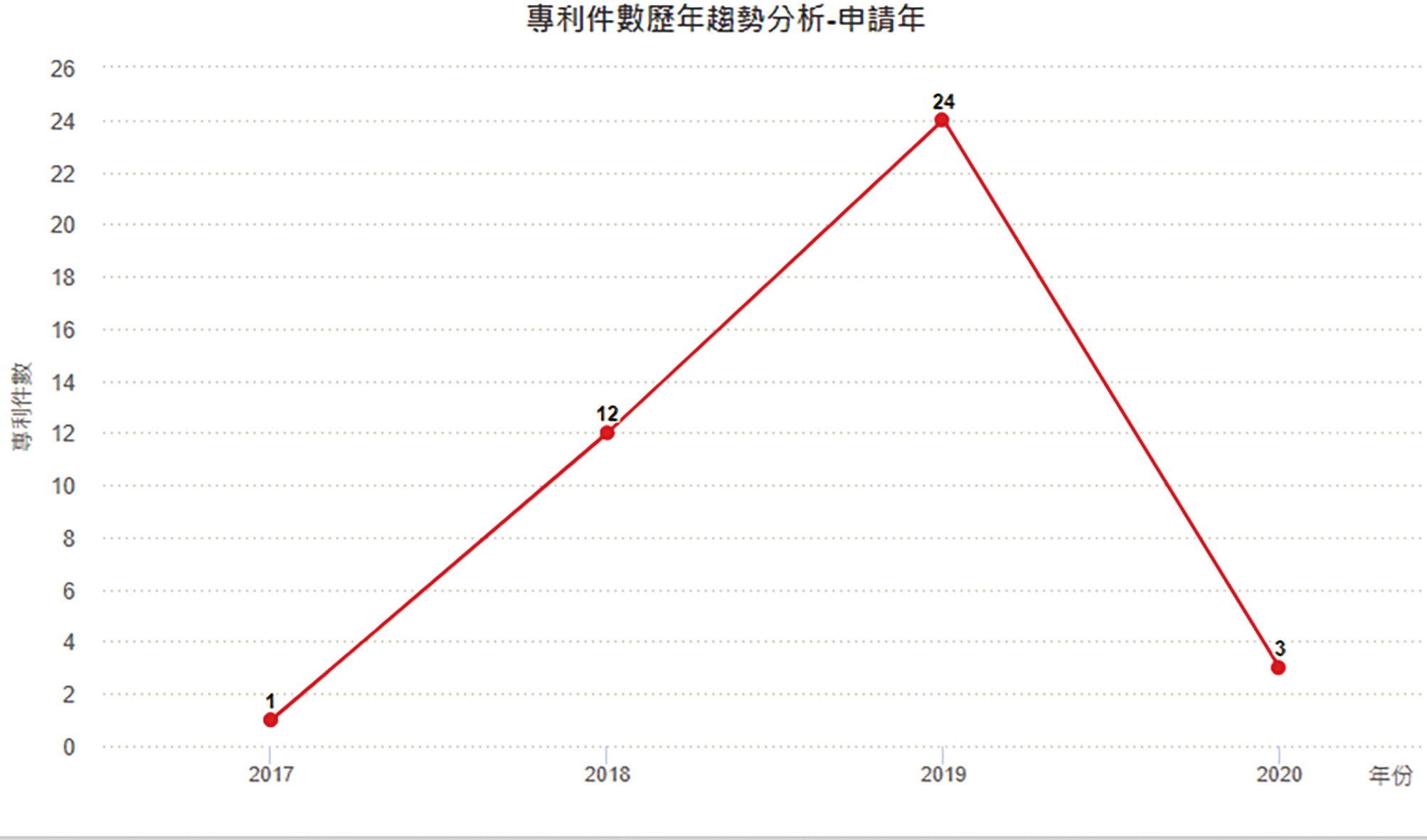 圖3 Groq逐年專利申請趨勢
圖3 Groq逐年專利申請趨勢
圖6顯示Groq專利組合中四階國際專利分類碼(IPC)係以G06N 3/00(基於生物模式之計算機系統)為主,其次依序為G06F 7/00(根據所欲處理的資料之位數或內容進行運算的資料處理之方法或裝置)、G06F 17/00(專門適用於特定功能的數位計算設備或數據加工設備或數據處理方法)與G06F 9/00(具內控程式控制裝置,如指令控制單元)。圖7顯示Groq專利組合中五階國際專利分類碼(IPC)係以G06F 17/16(專門適用於特定功能的數據處理方法,特別是指矩陣或向量運算等複雜的數學運算)為主,其次依序為G06N 3/04(基於生物模式之計算機系統,特別是指利用神經網路模式中之體系建構,例如:互連拓撲)、G06N 3/08(基於生物模式之計算機系統,特別是指利用神經網路模式之學習方法)與G06N 7/00(基於特定數學模式之計算機系統)。
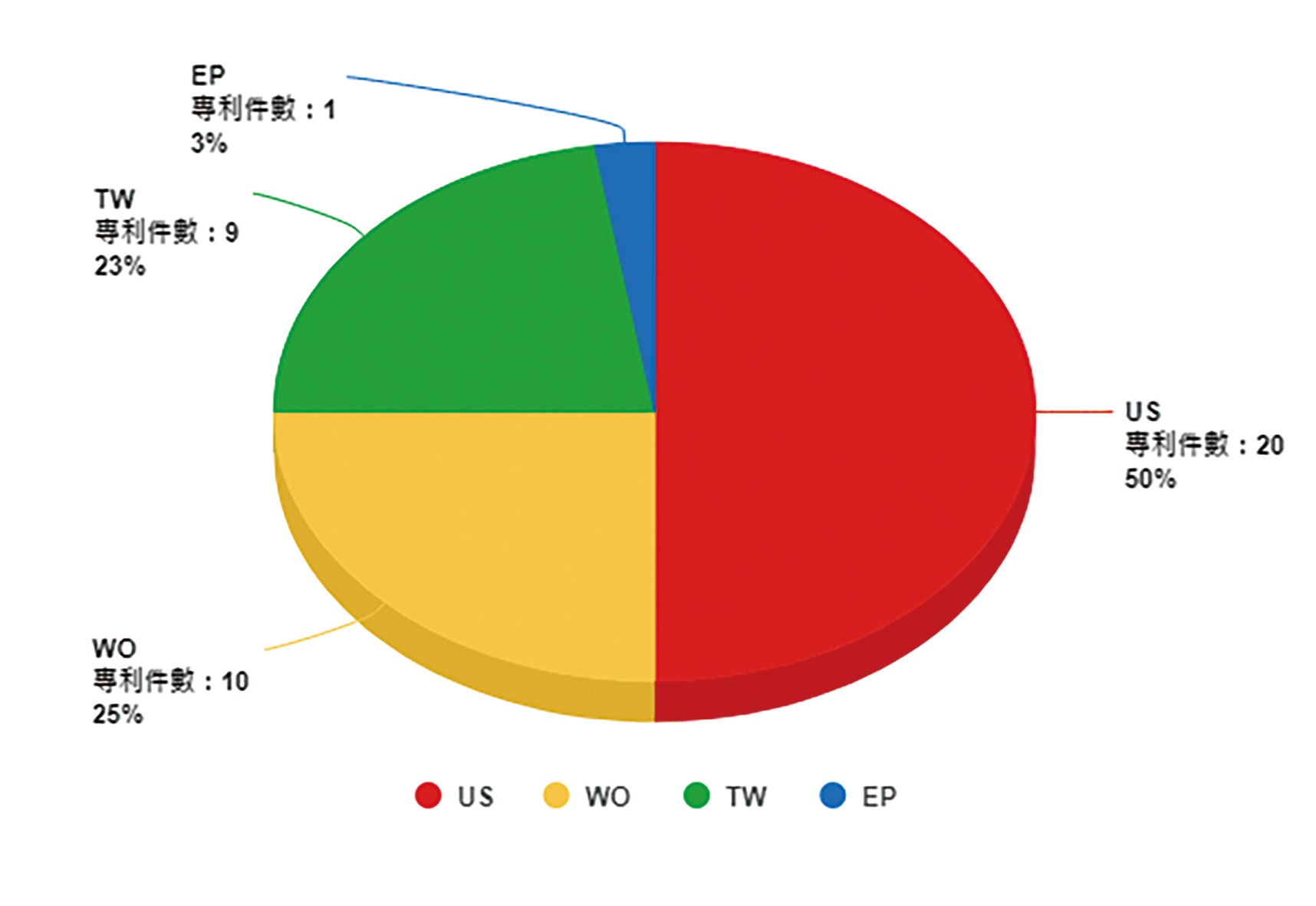 圖4 Groq的專利申請國別比例圖
圖4 Groq的專利申請國別比例圖
 圖5 Groq的TOP 5三階國際專利分類碼
圖5 Groq的TOP 5三階國際專利分類碼
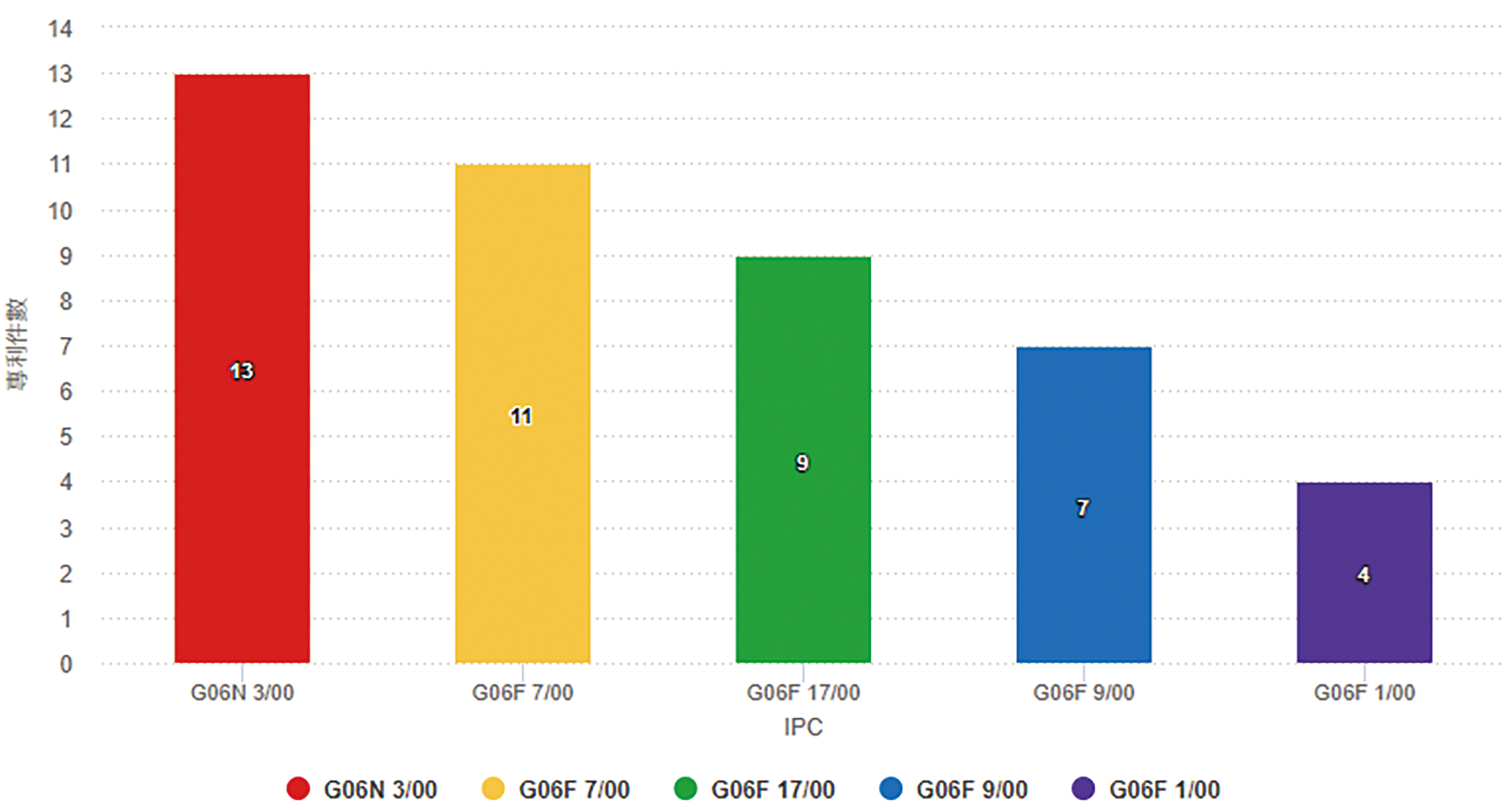 圖6 Groq的TOP 5四階國際專利分類碼
圖6 Groq的TOP 5四階國際專利分類碼
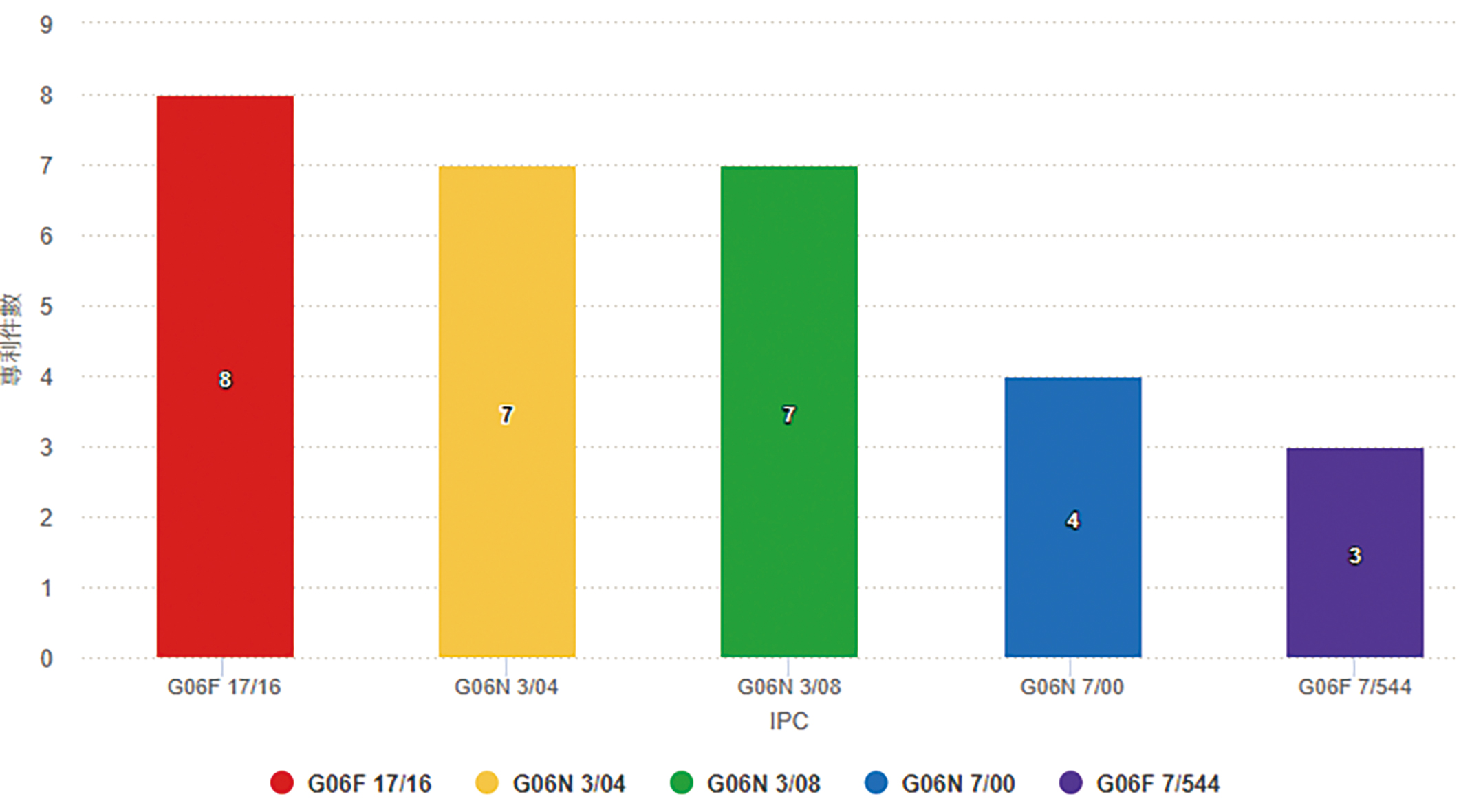 圖7 Groq的TOP 5五階國際專利分類碼
圖7 Groq的TOP 5五階國際專利分類碼
Groq專利技術解析
神經網路及其他類型之模型可用於處理各種類型之資料。例如,一神經網路模型可經訓練以辨識經接收輸入影像內是否存在某些類型之物件。訓練及機器學習可用於判定待藉由模型用於處理輸入資料之一係數集,諸如一神經網路模型之神經元之間的權重。
.神經網路之模型參數的解壓縮方法及處理器
美國專利公告號US10680644B2[3]係關於神經網路之模型參數的解壓縮,即一種使用基於累積計數分布之函數之用於模型參數之解壓縮之方法及處理器。具體而言,該專利係有關一種預測模型(例如神經網路模型)可與該模型之一係數集結合使用。該係數集可儲存於記憶體中且經存取用於對輸入資料(例如待藉由該模型分析之一影像)執行算術運算。
該專利的特徵為一種預測模型,其利用一係數集來處理經接收輸入資料。為減少儲存該等係數之記憶體使用,一壓縮電路藉由產生係數值之一累積計數分布且識別概算表示該累積計數分布之一分布函數而在儲存之前壓縮該係數集。該經判定函數之函數參數儲存於一記憶體中且由一解壓縮電路使用以將該函數應用於該等壓縮係數而判定解壓縮分量值。相較於儲存用於解壓縮之一查找表,儲存該等函數參數可消耗較少記憶體,且可減少解壓縮期間所需之記憶體查找之量。
圖8繪示出該專利用於儲存和解壓縮模型中所使用的模型係數的系統示意圖。一張量流處理器(TSP)100或其他類型之處理器經組態以基於一經儲存模型接收及處理輸入資料值102(例如輸入影像)而產生輸出資料值(例如輸入影像之一分類、輸入資料中之某些類型之物件或特性之識別及/或類似者)。TSP 100包括一記憶體108,記憶體108儲存由算術單元使用以操作輸入資料值102的壓縮模型係數112。可由編譯器120自預測模型118產生壓縮模型係數112。預測模型118可對應於利用一係數集之任何類型之模型。預測模型118係一迴旋神經網路(CNN)或其他類型之神經網路模型。一旦已建構或充分訓練預測模型118,便可由一編譯器120編譯模型118以由TSP 110使用用於處理輸入資料值102。編譯器120分析預測模型118之係數值,且選擇用於壓縮模型之係數值之一或多個壓縮方案。接著,將壓縮係數值作為壓縮模型係數112儲存於記憶體108中。
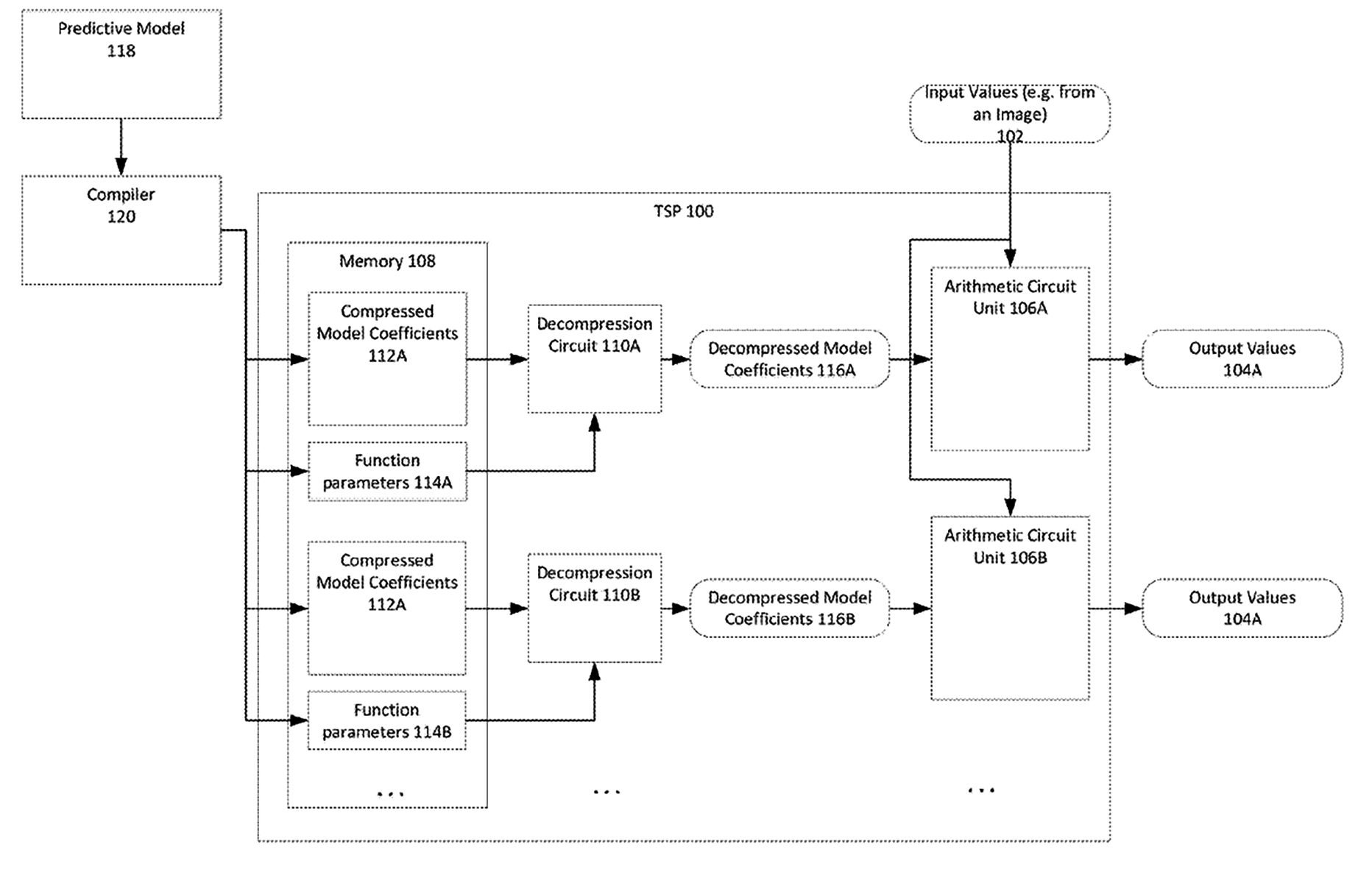 圖8 用於儲存和解壓縮模型中所使用的模型係數的系統示意圖
圖8 用於儲存和解壓縮模型中所使用的模型係數的系統示意圖
為了由算術電路單元使用以操作輸入資料值102,需要解壓縮與模型相關聯之壓縮模型係數112。一解壓縮電路經組態以自記憶體108接收壓縮模型係數112,且輸出可由算術單元操作之解壓縮模型係數。
編譯器120基於自與模型相關聯之係數值之一分布導出的一函數選擇用於預測模型118之係數之一壓縮方案。編譯器120判定最佳擬合模型係數分布之一函數類型,且將經判定函數之參數作為函數參數114儲存於記憶體108中。函數參數114可指示與分布相關聯之一函數類型以及函數之係數及/或與函數相關之其他參數的值。解壓縮電路支援用於解壓縮壓縮模型係數112之數種可能函數。
解壓縮電路藉由將由函數參數114定義之特定函數應用於壓縮模型係數112解壓縮壓縮模型係數112以判定解壓縮模型係數。記憶體108可將預測模型118之壓縮模型係數儲存為複數個不同係數集(例如,一第一壓縮模型係數112A集及一第二壓縮模型係數112B集)。可能已基於一不同函數(例如,與第一函數參數114A相關聯之一第一函數及與第二函數參數114B相關聯之一第二函數)且運用算術或霍夫曼(Huffman)寫碼壓縮各壓縮模型係數112集。
不同解壓縮電路(例如,解壓縮電路110A及110B)可用於解壓縮使用不同函數壓縮之不同壓縮模型係數集,以產生不同解壓縮模型係數(例如,解壓縮模型係數116A及116B)集。可由多個算術單元(例如,算術單元106A及106B)操作經輸出解壓縮模型參數116A及116B以產生輸出資料值之多個集(例如:輸出資料104A及104B)。
該專利之申請專利範圍主張一種用於模型參數之解壓縮之方法,其包括:接收與一模型相關聯之壓縮係數資料,其中使用基於該係數資料之值之一累積分布之一壓縮函數來壓縮該係數資料;擷取與該壓縮函數相關聯之一組函數參數,該組函數參數指定至少一函數類型;基於該等經擷取函數參數組態一解壓縮電路;使用該解壓縮電路基於函數參數解壓縮該壓縮係數資料以產生解壓縮係數值;及藉由使用該等解壓縮係數值對經接收輸入資料執行算術運算而將該模型應用於該經接收輸入資料以產生一輸出值集。該專利係為減少記憶體使用,在儲存之前壓縮該係數集。相較於其他解壓縮方法(例如,一查找表),儲存該等函數參數可消耗較少記憶體,且亦可減少解壓縮期間所需之記憶體查找之量。
.矩陣之空間地域轉換
現代神經網路包含多個層。各層可包含大量輸入值,其隨後經轉換以產生充當後續層之輸入之輸出(即激勵(Activation))。通常,此等輸入及輸出值經表示為矩陣(例如具有一至多個維之值陣列)。對此等輸入值所執行之一共同轉換係一迴旋。一迴旋將一核心(其包含加權值且亦可表示為一矩陣)應用於輸入中之相鄰值以產生一輸出值。此被重複用於輸入中之所有值(如由權重所修改)以產生一組輸出值。然而,由於核心將歸因於必須在相鄰值中多次讀取而多次跨越或滑過相同輸入值以產生多個輸出時,造成執行時運算量非常龐大。因此,希望可由一核心更高效率運算由權重修改之輸入值之迴旋以產生輸出值的系統。
美國專利公開號US20200159813A1[4]大體上係關於矩陣運算,具體而言係關於矩陣之空間地域轉換。圖9繪示根據一實施例之用於經由一核心之空間地域轉換(Spatial Locality Transform, SLT)來迴旋(Convolution)一輸入張量(Input Tensor)以產生輸出激勵(Output Activations)的一系統100。
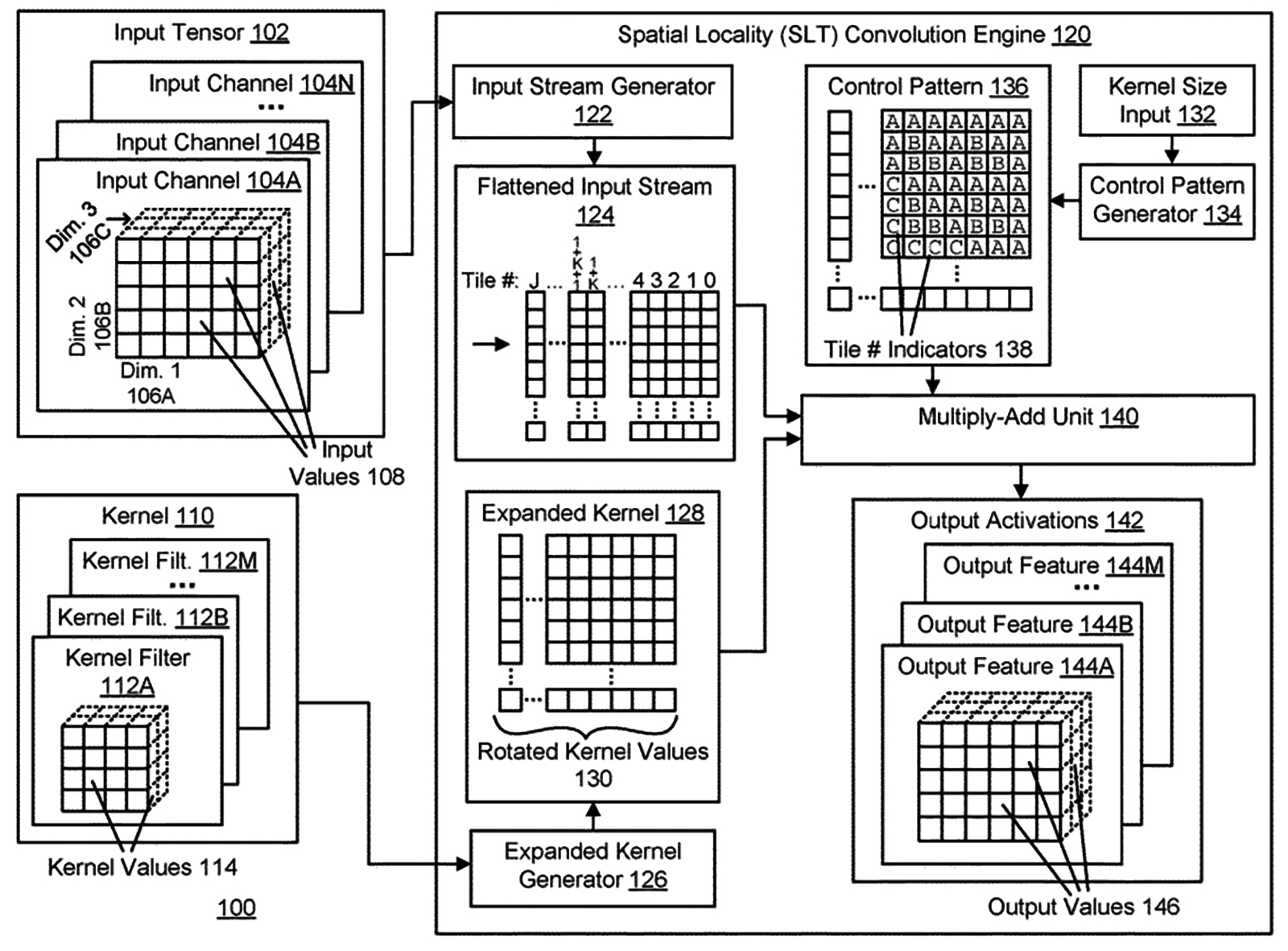 圖9 利用核心之空間地域轉換迴旋輸入張量以產生輸出激勵的系統
圖9 利用核心之空間地域轉換迴旋輸入張量以產生輸出激勵的系統
在一實施例中,系統100包含輸入張量102、核心(Kernel)110、輸入串流產生器(Input Stream Generator)122、展平輸入串流(Flattened Input Stream)124、擴展核心產生器(Expanded Kernel Generator)126、擴展核心(Expanded Kernel)128、控制型樣產生器(Control Pattern Generator)134、控制型樣(Control Pattern)136、乘加單元(Multiply-add Unit)140及輸出激勵142。輸入張量102係在迴旋運算中由核心110修改以產生輸出激勵142之輸入值(Input Values)108之一集合。
輸入張量102由一矩陣表示,矩陣可具有一個、兩個、三個或更多個維,且可儲存為記憶體中之一陣列,而陣列之維數可等於矩陣之維數。在一實施例中,輸入張量102具有多個輸入通道(Input Channels)104A-104N(統稱104)。各輸入通道104包含一或多個維的矩陣,諸如所繪示之輸入通道104A中之矩陣之維1至維3(106A、A06B、106C)。核心110在一迴旋運算(Convolution Operation)中應用於輸入張量102以產生輸出激勵142。核心110可由一或多維矩陣表示。
矩陣包含核心值114,就一神經網路而言,其表示應用於輸入張量102之輸入值108之權重。若核心110大於輸入張量102,則輸入張量102可經填補使得核心110之大小小於或等於經填補輸入張量102以允許發生迴旋運算,所得輸出激勵142係具有相同於(經填補)輸入張量102之大小的矩陣。
核心110包含一或多個核心「濾波器」112A至112M(統稱核心濾波器112)。各核心濾波器112包含一組子濾波器核心(Sub-filter Kernels),其本身係濾波器且等於輸入通道104之數目。使用各子濾波器核心來對各輸入通道104執行一迴旋運算,且加總所得輸出矩陣以產生一單一輸出激勵特徵矩陣或輸出特徵144A至144M(統稱輸出特徵144)。
此被重複用於各核心濾波器112所產生之輸出特徵144之數目等於存在於核心110中之核心濾波器112之數目,例如核心110包含1個核心濾波器112,則產生一單一輸出特徵144;類推核心110若包含5個核心濾波器112,則輸出激勵142將具有5個輸出特徵144。此允許神經網路將不同核心權重應用於輸入之不同部分(即不同的輸入通道104)且將結果組合成新穎輸出(即不同的輸出特徵144),其接著可用以作為神經網路之另一層中之進一步的輸入。
在填補輸入張量102之後,輸入串流產生器122將經填補輸入張量102劃分或分割成若干分塊。各輸入通道104之分塊之大小等於應用於該輸入通道104之各核心濾波器112之子濾波器核心之大小。在劃分輸入張量102之後,輸入串流產生器122識別一展平順序。輸入串流產生器122以經識別之展平順序讀取各分塊之值,且在讀取一單一向量中之各分塊之值時配置值,藉此「展平」分塊。
輸入串流產生器122讀取輸入張量102之所有分塊且產生對應數目個向量。將向量放置成彼此平行以產生展平輸入串流124。輸入串流產生器122可以一特定順序(列優先順序或行優先順序)讀取分塊,只要在產生擴展核心128及控制型樣136時反映分塊之順序,且可由乘加單元140產生一有效輸出,乘加單元140輸出整組輸出分塊作為輸出激勵142之最終輸出。
控制型樣136係一矩陣,其向乘加單元140指示自展平輸入串流124之哪些部分選擇以產生與擴展核心128之向量相乘(使用點積)以產生各輸出值之選定值。所有輸出特徵144之集合表示輸出激勵142且可用作為神經網路之下一層中之輸入通道104,也就是一層之輸出激勵142變成神經網路之下一層之輸入張量102。
該專利申請專利範圍主張二個獨立請求項,分別是方法請求項和系統請求項。例如,提供一種方法,包括:接收用於與一核心迴旋之一輸入張量;將該輸入張量分成一或多個分塊,其中各分塊具有等於該核心之一大小;及將該一或多個分塊中之該等值展平成向量以產生展平輸入串流。再者,該專利在另一實施例中提供一種系統,包括:一處理器,該處理器包括一輸入串流產生器,其經組態以接收用於與一核心迴旋之一輸入張量;將該輸入張量分成一或多個分塊,其中各分塊具有等於該核心之一大小;及將該一或多個分塊中之該等值展平成向量以產生展平輸入串流。該專利的特徵及優點包含一控制型樣產生器電路可整合於乘法器陣列電路之半導體表面上,並且能夠以非常高速率執行迴旋運算的處理器電路。
.具有多讀取埠之資料結構
資料結構(諸如查找表)可用於諸多應用中以對所接收之輸入資料執行一函數。例如,一算術邏輯單元(ALU)可藉由在一查找表中查找一接收輸入值且回傳一對應輸出值來對該接收輸入值執行一運算。在一些情況下,諸如在單指令多資料(SIMD)應用中,可期望能夠對不同輸入資料集並行執行相同運算。因而,多個ALU或其他電路需要能夠並行存取查找表內所含之資料。
美國專利公開號US20190206454A1[5]係關於具有多讀取埠之資料結構之儲存。其具有多個讀取埠之記憶體結構可用於允許由多個算術邏輯單元或其他處理器件並行存取一共同資料結構(諸如查找表),可使用具有較少讀取埠之複數個記憶體結構來建構該記憶體結構。
該專利可使用各具有2m-1個讀取埠之三個記憶體結構(例如子結構)來建構具有允許同時存取n個資料輸入項之2m個讀取埠之一記憶體結構。該三個記憶體結構包含:一第一結構,其提供對該n個資料輸入項之一第一半(n/2個輸入項)之存取;一第二結構,其提供對該n個資料輸入項之一第二半(n/2個輸入項)之存取;及一差異結構,其提供對該n個資料輸入項之該第一半與該第二半(n/2個輸入項)之間的差異資料之存取。該2m個埠之各者可連接至該等2m-1埠資料結構之各者之一各自埠,使得一埠可藉由存取該第一結構或藉由存取該差異結構及該第二結構兩者來自該n個資料輸入項之該第一半存取資料以重建由該第一結構儲存之該資料。
類似地,一埠可藉由存取該第二結構或藉由存取該差異結構及該第一結構兩者來自該n個資料輸入項之該第二半存取資料以重建由該第二結構儲存之該資料。因而,可使用各儲存n/2個資料輸入項之三個1埠記憶體結構來建構用於存取n個資料輸入項之2埠記憶體結構。類似地,可使用總共儲存(3/2)m×n個輸入項之多個1埠記憶體結構來建構用於存取n個資料輸入項之一2m埠記憶體結構。
圖10繪示包含具有多個讀取埠之記憶體結構的處理器方塊圖。處理器係專用於張量處理之處理器,其包含一多埠記憶體結構100及多個算術邏輯單元102。多埠記憶體結構100包含動態隨機存取記憶體(DRAM)或儲存由複數個算術邏輯單元102存取之資料結構(例如查找表)之其他類型之記憶體。資料結構與一函數相關聯,且將函數輸入值映射至函數輸出值。例如,資料結構實施一機器學習模型之一激勵函數,諸如整流線性單元(RELU)函數、二元階躍函數、反正切函數或其他函數。算術邏輯單元102可為一單指令多資料或其他並行處理器之部分,其中各算術邏輯單元102經組態以對不同輸入資料集執行相同算術運算。
 圖10 包含具有多個讀取埠之記憶體結構的處理器方塊圖
圖10 包含具有多個讀取埠之記憶體結構的處理器方塊圖
為使算術邏輯單元102並行運算,複數個算術邏輯單元102需要能夠同時存取記憶體結構100上之資料結構。例如,圖1繪示具有四個讀取埠104之記憶體結構100,讀取埠104各連接至四個不同算術邏輯單元102之一者。各讀取埠具有其自身專用位址匯流排及其自身專用資料匯流排。算術邏輯單元102藉由將一位址提供至位址匯流排來經由一讀取埠讀取資料,且記憶體結構100自定位於該位址處之資料結構回傳資料。該專利所指的「同時(Concurrently)」,係指在一共同時間週期(例如一時脈循環)期間。例如,複數個算術邏輯單元102之各者可在一特定時脈循環期間將一讀取請求傳輸至記憶體結構100,其中所傳輸之讀取請求可被視為彼此同時。
該專利權利請求項包括三個獨立請求項,分別主張一種記憶體結構,一種處理器,以及一種用於透過多個讀取埠自一記憶體讀取資料之方法。
強化數位/能源轉型Groq攜手TDK Ventures
隨著推理用例呈指數成長,TDK Ventures特別尋求具有最高TOPS/Watt性能指標的AI推理晶片組解決方案,而致力於雲端推理晶片的Groq是其在AI晶片組解決方案上的第一筆投資。Groq提供了兩倍的推理性能,同時大大降低了基礎架構成本,使Groq的AI解決方案有助於減少二氧化碳並降低對高運算能力的能源需求,為TDK Ventures在可持續發展方面的投資做出了貢獻。
透過投資和支援,雙方成為理想的合作夥伴。TDK Ventures認識到Groq的實力和潛力,並幫助Groq的TSP架構在電力和能源領域實現了一種全新的創新,同時也幫助Groq將這些能力帶給關注機器學習運算能力需求和能源消耗的客戶,並繼續深化在資料中心、自動駕駛汽車和其他關鍵產業垂直領域的技術整合。
(本文作者為工業技術研究院技術移轉與法律中心博士)