量化(Quantization)有助降低類神經網路模型的記憶體體積與延遲,面對將生成式及大型語言模型導入行動裝置的趨勢,量化技術的重要性持續提升。
量化(Quantization)的一般定義,是將持續無限大的數值映射到較小的離散有限值集合的過程。本文將在類神經網路(Neural Network, NN)模型的情境中來討論量化,也就是降低權重(Weight)、偏差(Bias)與激活值(Activation)精度的過程。從浮點表示法轉移到低精度的固定整數值,具有顯著降低記憶體體積與延遲的潛力。這對於在運行階段運算資源相對受限的行動裝置與邊緣平台上部署模型來說,極為重要。此外,生成式模型與大型語言模型(LLM)的最新進展,以及將此類模型導入行動領域的趨勢,也讓量化的重要性越來越受到關注。
本文旨在提供整體的說明,讓大家瞭解在行動平台(Android)上進行量化的現行狀況,以及將複雜的NN模型推論導入邊緣端所開啟的契機。第一部分提供現有量化方式與分類的概述;第二部分則討論與比較TensorFlow Lite(TFLite)中兩種主要的量化方式:訓練後量化(Post-Training Quantization, PTQ)與量化感知訓練(Quantization Aware Training, QAT)。由於LLM與生成式模型的重要性與日俱增,最後一部分將專注在Transformers模型的挑戰,而這種模型偏好的方式是混合精度量化。
模型不一定越大越好
過去十年,NN針對各種使用場景的精度顯著提升。同時,模型也變得越來越大,LLM即為這種趨勢下的鮮明實例。舉例來說,每個新版本GPT的參數數量會增加100倍到1,000倍,這個數字來到GPT-4,來到約1.7兆。
過度參數化會讓記憶體與運算力受限的裝置,難以在可接受的效能與功耗條件下執行NN模型。對於嵌入式與行動裝置內,需要以低功耗與高精度達成即時推論的所有深度學習(DL)應用,都將因此遭遇阻礙。此類應用涵蓋各種使用場景,像是語言辨識、健康照護監控與遠端視訊會議。
這也是現有的量化技術對於行動與嵌入式裝置來說十分重要的原因。透過實作此類技術,能夠降低記憶體體積與耗電量並改善延遲,同時不至於大幅影響精確程度。要做到這點,設計、訓練與部署NN模型的方式,都必須改變。將大型模型(特別是生成式模型與LLM)導入行動平台領域,可以減少使用這些模型可能遭遇的安全及隱私保護等相關問題,同時降低邊緣/伺服器資料頻寬的消耗。
圖1顯示不同類型的量化方式。如同第一欄所示,一般而言,量化方式可根據持續ℝ領域中的實值,如何映射成量化ℚ領域中的離散、較低精度值(均勻或非均勻),分成三種類別。
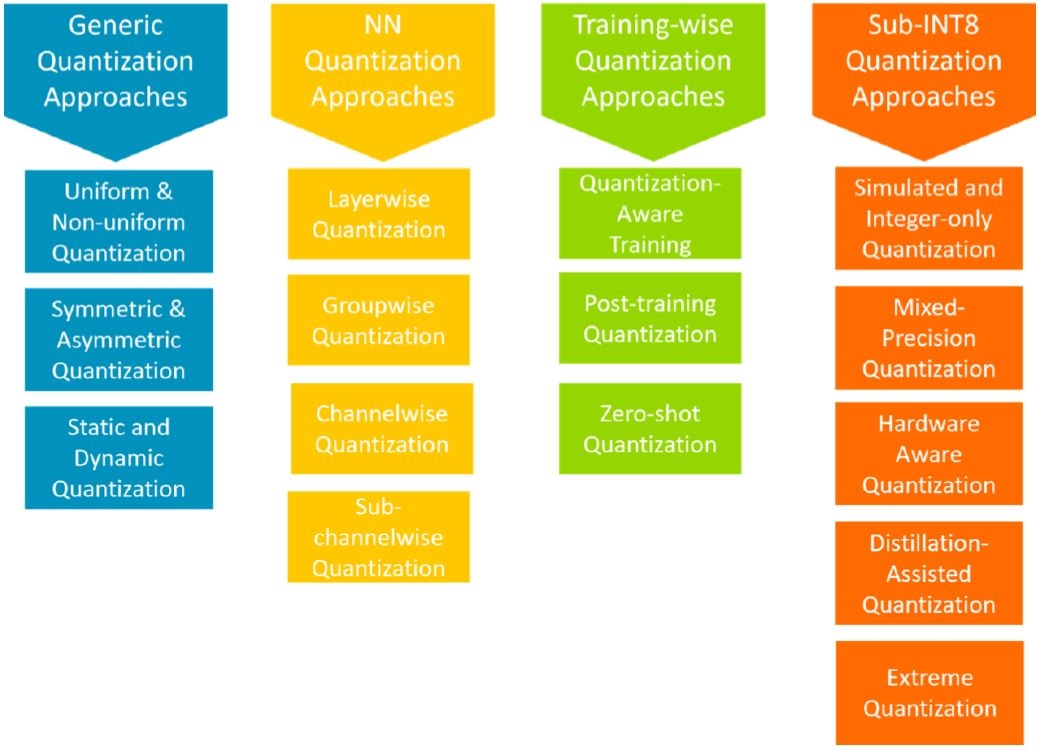 圖1 不同的類神經網路模型量化方式
圖1 不同的類神經網路模型量化方式
根據量化精細程度的不同,如果只專門看NN,第二欄列出各種不同的方式。這裡必需考量的一個重要特徵是如何為權重計算出截斷範圍;不管它的計算方式是考量到層的權重、一層內多個通道群的權重、每個通道使用一個固定值,或是一層內的一群參數都使用一個固定值。
圖1第三欄則從訓練的角度進行分類。本文將聚焦在訓練量化的方式,將於比較量化感知訓練及訓練後量化時,更仔細地檢視這些方式。最後,最後一欄列出幾個次INT8的量化方式,包括僞量化、只有整數的量化,到把數值表示限縮到單一位元的極度二值化量化。
量化感知訓練VS訓練後量化
如前文所述,量化是一種技術,用來降低NN模型、權重、偏差與激活值所使用的數值資料的精度。量化若使用如8位元整數等較低精度的格式、而非32位元浮點,就可以降低模型的大小、記憶體的足跡與運算的時間,而這些都是在行動裝置與邊緣平台部署模型必須考量到的相關因素。量化也可以提升行動裝置的能源效率與電池續航力,同時在支援低精度算術的特定處理器上,促成硬體的加速。
前一部分顯示量化類神經網路模型的各種方式。根據訓練相關的量化實施時間點與方式,可以把量化的方式分成兩大類:量化感知訓練(QAT)以重新訓練模型來執行量化;訓練後量化(PTQ)則在不重新訓練模型的情況下實施量化(圖2)。
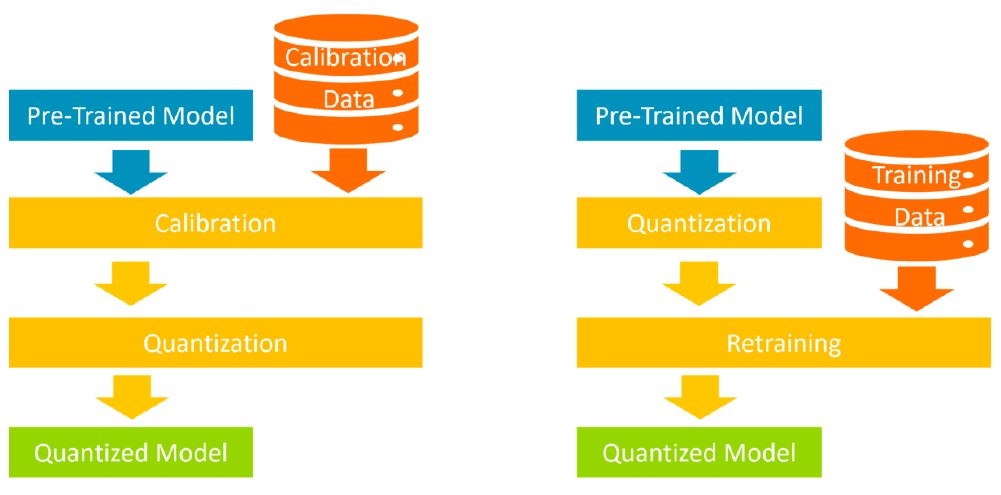 圖2 PTQ(左)與QAT(右)的訓練方式
圖2 PTQ(左)與QAT(右)的訓練方式
訓練後量化(PTQ)
PTQ是一種量化技術,可以在無須進行額外訓練的情況下,降低模型的記憶體體積,同時改善CPU與硬體加速器的推論延遲情況。然而,在某些情況下,模型精度的退化可能相當顯著。當已經完成訓練的浮點TF模型使用TensorFlow Lite轉換工具轉換成TFLite格式時,將進行此類量化。
表1比較進行訓練後整數量化時,TF可用的選項。此處不考慮Float16量化額外的選項。中間欄位的大小縮減與Float32模型的表示有關。
 表1 供PTQ方式使用的不同TensorFlow選項 (資料來源:請見參考資料[1])
表1 供PTQ方式使用的不同TensorFlow選項 (資料來源:請見參考資料[1])
動態範圍量化的優點在於可以降低記憶體體積並提升效能,卻不需要代表資料集來進行校準,因此是訓練起始點的推薦選項。此一選項根據激活值的範圍,動態地將其量化為8位元,並以8位元的權重與激活值執行運算。因此,它的延遲情況接近全整數推論,但由於輸出依然使用FP32進行儲存,加速並沒那麽快。
以下的程式碼片段,顯示該如何以TFLite轉換工具來調用PTQ。
1 import tensorflow as tf
2 converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir)
3 converter.optimizations = [tf.lite.Optimize.DEFAULT]
4 tflite_quant_model = converter.convert()
預設(DEFAULT)是唯一可用的選項,原因是其他的選項已經被廢止,只有權重可被量化。也可能量化如模型的輸入/輸出與各層之間的中間層等可變資料,但針對這一點,必需提供名為RepresentativeDataset的生成函數。它可以提供一套大到足以表述典型值的輸入資料,讓轉換工具可以為所有可變資料估算出動態範圍。
1 import tensorflow as tf
2 converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir)
3 converter.optimizations = [tf.lite.Optimize.DEFAULT]
4 converter.representative_dataset = representative_data_gen
5 tflite_model_quant = converter.convert()
在此之後,所有的權重與可變資料都會進行量化,而模型的大小與原本的TensorFlow Lite模型相比,將顯著縮小。
整數量化方式將FP32浮點數(權重與激活值輸出)轉換成最近的INT8定點數。如表1所示,如此一來可以像動態範圍量化縮小模型的尺寸,但推論時仍可能達成更快的加速。此為適用於Edge TPU等純整數加速器的量化方式。
前文中已展示實作動態範圍量化的程式碼片段,而由於TFLite轉換工具將模型的輸入與輸出張量保留為浮點格式,該模型尚無法相容於只執行整數架構作業的裝置。為了確保端對端的純整數模型,需要一些額外的微調。
為了產出全整數的量化模型,將再次轉換模型,使用一些不同的參數,並在設定好代表資料集後,為之前的程式碼片段新增兩行:
1 …
2 converter.representative_dataset = representative_data_gen
3 # Throws an error if the converter can’t quantize an operation
4 converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
5 # Set input and output tensors to UINT8
6 converter.inference_input_type = tf.uint8
7 converter.inference_output_type = tf.uint8
8 tflite_model_quant = converter.convert()
全整數量化模型的輸入與輸出張量皆使用整數資料,因此模型與純整數硬體相容。
參考資料
[1] https://www.tensorflow.org/lite/performance/post_training_quantization
量化加速LLM/生成式AI進入邊緣(1)
量化加速LLM/生成式AI進入邊緣(2)
量化加速LLM/生成式AI進入邊緣(3)