過去幾十年,由於安全氣囊或電子穩定控制等安全系統的高度普及,交通事故死亡人數明顯減少。然而最近幾年,這一趨勢減緩,事故統計資料顯示,死亡人數並未繼續下降。
原因之一是交通運輸量不斷增加且日益複雜;另一個原因是,駕駛在駕駛時使用智慧手機等通訊設備容易導致注意力分散。借助進階駕駛輔助系統,交通事故可逐漸趨向零死亡率,利用攝影鏡頭的360o傳感和雷達感測器,感知汽車周邊的情景,讓駕駛一眼捕捉到所有危險(圖1);此外,根據感測器資料,可以檢測汽車周邊的所有物體,而且在緊急情況下,半自動駕駛系統可在制動和轉向時輔助駕駛。
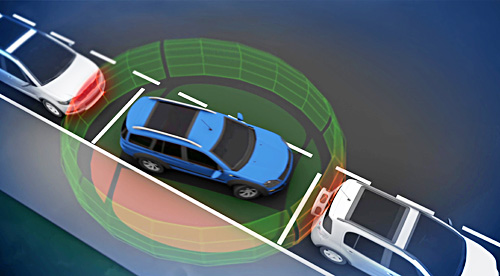 |
| 圖1 環視傳感系統 |
全面普及進階駕駛輔助系統可望進一步減少因交通事故產生的死亡率。全球許多國家目前正在著手制定相關規定。例如,歐洲NCAP評價機構將在評價體系中包含主動安全系統,並進行大量宣傳,以增加汽車購買者對主動安全系統的意識。
實現高普及率的另一個重要因素是支付能力。購買該系統的人越多,駕駛就會變得越安全,有鑑於攝影鏡頭的系統充分利用消費電子領域的發展和半導體技術尺寸大大縮小等諸多優勢,對大眾市場有不可抗拒的吸引力。由於感測器解析度更高、演算法更先進,每一代的效能要求也隨之增加。此外,安裝在擋風玻璃後面的攝影鏡頭模組意味著要承受105℃以上的高環境溫度。
這些相互矛盾的要求使功率消耗成為基於攝影鏡頭的駕駛輔助系統的最大技術挑戰之一。
多功能前置攝影鏡頭解決方案適用於前燈控制、車道保持、交通標誌識別和防踫撞功能。現在大多使用解析度高達1.2M畫素、每秒30幀的互補式金屬氧化物半導體(CMOS)影像感測器;隨著新一代感測器的推出,解析度將進一步提高,以在惡劣的天氣和照明條件下也能可靠地檢測物體,但需要複雜的演算法。
車道保持、自主緊急制動或交通擁堵輔助等半自動駕駛輔助系統,需要帶有演算法冗餘的汽車安全整合層級(ASIL)ID安全級別,但所有這些都需要強大的計算能力。
六大解決方案打造多功能/低功耗攝影鏡頭
目前的攝影鏡頭解決方案使用多個處理元件,如專用硬體加速器、現場可編程閘陣列(FPGA)、數位訊號處理器(DSP)和通用處理器,此類攝影鏡頭模組包括印刷電路板(PCB)上的多個元件。
客戶需要更小型化、成本更低的解決方案,這對整合度又提出更高的要求。但至今擋風玻璃後面的攝影鏡頭能夠接受的最大功率仍有限,無法實現更通用、完全可程式設計的高效能攝影鏡頭解決方案。
然而,隨著半導體行業的技術進步以及採用高度並行視覺計算方法的高度優化可程式設計架構的發展,此類單晶片解決方案變得可行。
影像處理的不同階段有不同的特點(圖2)。第一階段是感測器資料的預處理,如過濾和圖像增強。所需作業在一個尺寸有限的滑動視窗中進行,通常很適合高並行處理,每個畫素都得到處理,每秒的運算數量相當大,但資料流程可以採用相對較小的本機存放區器進行管理。
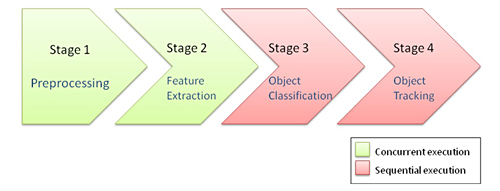 |
| 圖2 電腦視覺處理流 |
第二個處理階段是提取特徵,如從圖像的邊緣或邊角。這種處理通常也以一個畫素為基礎,透過滑動視窗進行,從這個角度來看,類似於預處理步驟的並行特性。所提取的特徵是基於畫素或描述符的。基於描述符的特徵將使用帶有高壓縮資料圖的複雜資料結構。
第三階段是根據特徵圖對物體進行分類。被檢測物體導致資料數量急劇減少。與前一階段基於畫素的處理相反,物體檢測演算法有複雜的控制流,會產生一個隨機的資料訪問模式。特徵處理級別上所需的處理效能仍然很高,因為要實現高強韌性和可接受的低錯誤檢測率,須要結合豐富的分類資料庫來評估許多不同特徵。
第四階段在幾個幀上跟蹤被檢測物體,實施一個汽車周邊環境的綜合模型,評估所處情況,觸發下一步行動。所需處理又是高度非線性的,但資料量比較小。
為了快速適應不斷演進的演算法和日新月異的市場需求,各階段都需要靈活性和可程式設計性。
由於處理和資料訪問的不同特點,每個階段都需要不同的處理架構,才能以最低功耗實現最佳效能。圖3顯示典型架構選項及其靈活性、效能和功耗等特性。
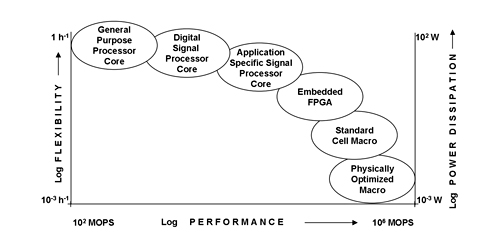 |
| 圖3 處理架構選項 |
專用硬體加速器解決方案
專用加速器以最低功耗提供最高效能(圖4)。該架構通常由一組硬體模組組成,與簡單的MAC運算相比,能夠通過一個專用資料路徑執行一個特定的影像處理任務。每個處理模組都是高度優化和參數化的,但靈活性有限。
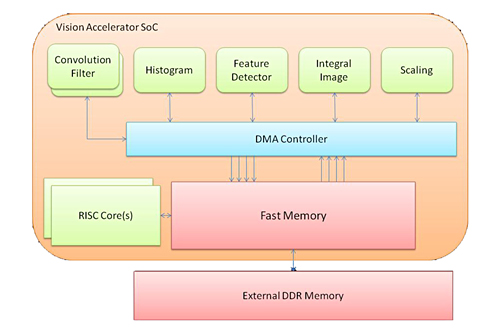 |
| 圖4 專用硬體加速器子系統 |
一組固定功能硬體加速器作為一個子系統實施,並整合在一個能夠處理高資料頻寬的架構中。通常,會根據特定的處理類別定制要實現的功能,因此不同應用(如視訊壓縮)重複使用視覺處理加速器是非常有限的。
視覺處理專用硬體加速器的典型功能模組包括:
 |
| 圖5 Sobel濾波器效果示意 |
從功率/成本的角度來看,專用硬體加速器是實施特定處理任務的最有效方法。其特性要求與所需的功能正好匹配,資料流程是高度優化的,但最大的缺點是靈活性有限。
因此,專用加速器非常適合不須要隨著每一代新元件的推出而有重大變化的成熟演算法,因為固定功能專用加速器應該用於處理鏈的通用和無區分部分。憑籍電源效率、演算法成熟及其高並行結構,專用硬體加速器成為視覺處理第一階段的最佳選擇,例如攝影鏡頭中的圖像增強可優化畫面品質。
這些專用功能單元往往作為處理管道實施,管道中的資料通過處理單元傳輸,因此它們增加了低處理延遲,可以在本地記憶體中運行。
現場可程式設計的元件
FPGA能提供高度的靈活性。該元件非常適合具有高度自帶並行的演算法,如基於畫素的處理,因此很適合視覺處理管道的第一、第二階段。
FPGA程式設計模型支援無限的並行性,而且由於演算法的並行性,因此FPGA能很好地擴展,然而實現高度的靈活性須要付出一些代價。挑戰之一是實現功能安全,因為重新配置機制可能成為單點故障。除此之外,FPGA普遍受困於因內部物理結構包含大量互連開銷而導致的更高功耗問題。
這種互連結構還會導致晶片本身的生產成本增加(掩模層)。駕駛輔助市場的擴大強有力地推動人們採用高度整合的單晶片解決方案(包含幾百萬位元組的記憶體),這對FPGA意味著挑戰,因為其互連結構需要更多的金屬層。整合時,由於具有額外的生產層,重要記憶體和標準單元邏輯製造成本將增加。
數位訊號處理器
DSP能很好地在並行畫素處理以及自訂資料結構處理或複雜的控制流之間進行演算法平衡,這使得視覺處理管道第二、第三階段的DSP很高效,其中,超長指令字(VLIW)DSP是目前具有高度的複雜性和很長的管道。
因此,與非常簡單的內核架構相比,DSP系統中的內核數量有更多限制。當頻率隨著每一代新元件的推出而增加時,該元件能很好地擴展,但由於新一代頻率增加減緩,未來的許多應用中只有一個DSP就顯不夠。
由於對於多核DSP應用並不存在一個現成的透明程式設計模型,基於DSP的解決方案又在可擴展性方面受到限制;同時還會發現來自精簡指令集(RISC)架構的強大競爭,因為採用整合的輔助處理器和單指令多重資料(SIMD)向量架構,RISC架構並行作業的訊號處理能力接近每一代自帶的DSP。
與RISC相比,DSP由於採用帶多個資料匯流排的哈佛架構,仍然具有優勢,可提供更高的資料輸送量、記憶體作業數或向未對齊資料提供專門的訪問模式。VLIW允許資料定址與資料處理並行。
RISC和DSP一般提供幾千MIPS,比採用專用架構或FPGA架構通常所實現的至少低一個數量級。
基於圖形處理單元的解決方案
圖形處理單元(GPU)屬於圖3所示的特定處理器(ASIP)應用。將GPU用於電腦視覺任務等並行處理在桌面PC領域非常普遍,在該領域GPU強大的顯卡能夠使用最初為OpenGL著色器整合的處理元件,做為通用的大規模並行程式設計環境。
此外,在高效能計算領域,GPU已經在許多方面取代了DSP。一個推動因素是在消費電子行業的推動下,能以相對較低成本提供有數百個著色器的強大GPU架構;另一個原因是支持無限並行作業的OpenCL或專有CUDA程式設計模型已上市,因此GPU具有良好的可擴展性和強大的路線圖。
目前廠商推出的嵌入式多核處理單元(MPU)同時還整合了強大的GPU,用於加速視覺處理任務。一個嵌入式GPU通常比專用加速器或FPGA提供的並行處理單元數量少很多,指令集的靈活性比DSP低,因此,GPU適用於視覺處理管道的第二階段和第三階段。
迄今為止,嵌入式系統的功率包絡不支援通過GPU進行全畫素處理,這是因為GPU擁有巨大的圖形和通用高效能計算功能開銷,而計算視覺任務並不需要它。視覺處理不需要的其他硬體不僅耗電,而且還大大增加嵌入式平台的成本。浮點運算支援是其中一個示例,在視覺處理管道的第一階段並不需要該功能。
另一個因素是外部記憶體的頻寬限制。儘管一流的桌面PC顯卡通常在1GHz時擁有至少256位元的寬記憶體匯流排,但是由於可用的功率包絡有限,該解決方案對嵌入式平台來說不可行,GPU雖然能很好地在使用強大顯卡的PC上加快演算法開發,但對嵌入式視覺處理來說效率不高。
大規模並行系統
另一類ASIP是大規模並行系統(圖6),非常適合執行計算視覺的第一、二階段的計算密集型畫素處理部分。此類解決方案的可程式設計性帶來了很大的靈活性,允許由軟體定義功能;採用的演算法通常有一個可被分配到並行處理單元的重要部分。這些演算法通常採用一個相當線性的程式流,可以分配到許多小而簡單的內核系統網格。
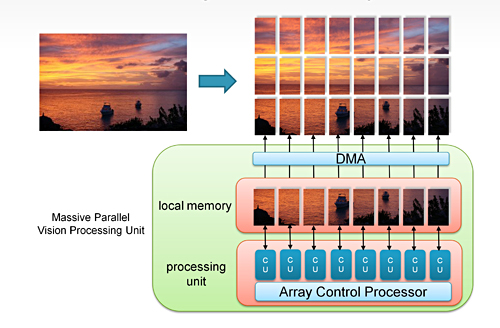 |
| 圖6 大規模並行視覺加速器 |
與GPU相反,大規模並行視覺加速器可針對應用的特定要求進行優化,如計算單元(CU)(相當於GPU中的著色器)的優化。對於視覺使用情況,浮點功能沒有嚴格的要求,可以很容易地被定點運算取代,這允許從所有CU中去除浮點單元,從而大幅縮小晶片尺寸。
優化的另一方面是資料流和記憶體訪問。因為畫素處理的記憶體訪問通常採用可預見的線性方式,該路徑可以針對特定應用而優化,甚至獲得動態記憶體存取(DMA)等特殊硬體的說明。優化作業可以為計算視覺產生一個ASIP,不僅大大縮小了尺寸,還會大幅降低功耗。
混合解決方案
由於視覺處理管道的各個階段擁有不同特點,因此完整的系統解決方案需要混合不同的處理架構,以最大程度地降低成本和功耗。一個或多個RISC內核總是用來運行視覺處理管道的第四階段:作業系統和應用軟體。
駕駛輔助系統市場的現階段還不成熟,每次推出新一代產品都表現出功能的快速發展,目前FPGA和DSP在一個印刷電路板上結合,與RISC內核一起廣泛使用,這歸功於其靈活性(圖7)。
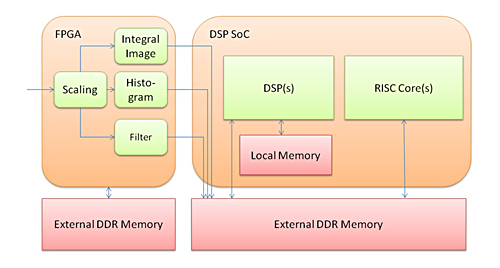 |
| 圖7 FPGA和DSP混合解決方案 |
功耗對於該混合解決方案來說仍然是個挑戰,另一方面成本也是效能的主要限制因素。高接腳數DDR記憶體介面需要多個元件,這不僅增加印刷電路板的成本,也限制了攝影鏡頭模組的小型化,而低成本和小型化正是汽車製造商的設計團隊非常渴望實現的目標。
對於未來的高容量攝影鏡頭解決方案(要獲得如歐洲NCAP的高評級等),市場開始強有力地向完全整合的單晶片解決方案(包括所有處理單元和大量記憶體)發展。對於視覺處理管道第一、第二階段基於畫素的處理步驟,存在一些競爭性處理架構,但它們有各自的優缺點。
圖7的解決方案中,第一階段在FPGA上實現,第二階段在DSP和FPGA之間分開實現。由於FPGA給系統單晶片(SOC)增加製造的複雜性,因此就功耗來說並不是最理想,第一階段的成熟部分(如縮放、長條圖)和用於攝影鏡頭輸入處理的FIR應作為專用加速器實現,提供最低的功耗和成本(圖8)。
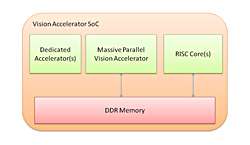 |
| 圖8 同類並行視覺系統 |
第一、第二階段中其餘基於畫素的處理部分,需要軟體程式設計的靈活性,應該託管在APEX等大規模並行視覺處理器中。與在通用DSP上執行這些任務相比,優點是功耗更低,而且支援無限並行的程式設計模型已上市。
由於視覺處理有不需要的巨大開銷,且DDR記憶體頻寬受到限制,因此在這裡GPU並不是視覺處理的一個高效選擇。圖7中,託管在DSP上的第四階段處理已經包含了進階別的處理,有複雜的控制流實現物體分類。
這些演算法不須要損失RISC內核的效率就可以通過DSP擴展執行,這樣的SoC解決方案很好地平衡了低功耗、系統成本和靈活性,還為當今的系統和未來的系統提供了非常好的可擴展性。兩種程式設計模型對於一個完全整合的視覺處理平台已經足夠,能高效地滿足所有不同的處理階段,允許軟體高水準地複用。
加快ADAS軟體開發 標準程式設計模型縮短上市時程
軟體是一個重要的成本因素。因為ADAS系統的軟體非常複雜,需要大量的測試和符合功能安全和可靠性要求的資格。因此,提高軟體複用的關鍵是降低整體開發成本、加快上市時間。
目前執行多個移植步驟須要進行大量的開發工作。第一步是從基本演算法開發環境(通常是PC)移植到嵌入式目標,大多數系統供應商並行使用不同的嵌入式平台,這往往需要移植到另一個嵌入式架構,由於軟體是非常依賴硬體的(尤其是在前兩個處理階段),因此要滿足效能和功率要求,移植工作通常非常重要,否則根本無法重複使用軟體。
解決方案要想明顯簡化轉型、提高可攜性,須使用針對並行處理的標準程式設計模型,為提取特定的架構特徵提供工具。目前圖形領域已經成功創建模型,使用者可以將軟體從PC移植到各種嵌入式平台,甚至毋須修改,增加毋須任何修改的可移植性將大大降低開發成本並加快上市速度,增加毋須任何修改的可移植性將大大降低開發成本並加快上市速度,而每個移植步驟都須要執行完整的測試和認證流程,這是構成開發成本一個的重要部分。
因此,晶片商開始計畫讓其新一代計算視覺平台支援大規模平行計算行業的標準OpenCL。儘管OpenCL能夠提取大規模平行計算平台,但挑戰非常明顯,那就是既要保持ASIP良好的效能/功耗比,同時還要符合標準的應用程式介面(API)。
到目前為止,OpenCL等大規模平行計算標準尚未考慮嵌入式先進駕駛輔助系統(ADAS)應用,因此首選的執行模型是對中間結果採用外部記憶體緩衝,如圖9所示。
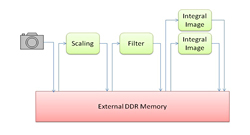 |
| 圖9 通過中間DRAM緩衝處理圖形 |
此類執行模型增加的DRAM流量對於嵌入式設備來說是一個嚴重的問題,因為頻寬限制是效能瓶頸,也會增加功耗。為了緩解這一情況,甚至可能須要擴展現有的標準,以更好地支援晶片資料流處理,如圖10所示。
在不將中間結果推到外部記憶體的情況下執行多個處理步驟不僅能節省電力,還能使解決方案更經濟高效,因為它降低了所需的DRAM頻寬。所考慮的擴展將實現以圖形為中心的處理,具有高度優化的資料流,適合計算視覺中的常見處理步驟。
使用PC領域常見的標準API的另一個積極影響是,允許同時使用標準PC和OpenCL顯卡進行開發,這意味著可以在目標平台尚未供貨的情況下開始軟體發展。此設置支援在類似的大規模並行系統上實施和測試演算法,並為新的程式設計範式重構演算法,但對於目標平台的效能評估,PC顯卡提供的洞察力卻非常有限。
 |
| 圖10 優化處理圖形 |
更高的整合度再加上靈活的標準化程式設計模型,這些都是優勢,同時吸引一流的廠商將其視覺軟體移植到新架構。這類新架構可保留在ADAS上的大量軟體投資的價值,因為它支持在未來的ADAS解決方案中重複使用軟體,毋須重新程式設計,這樣不僅降低成本,還加快上市時間。
配備半自動進階駕駛輔助系統等主動安全系統的汽車越多,對減少交通事故傷亡人數的積極影響就越大。除了修訂後的歐洲NCAP評級方案等規定外,支付能力也是實現該目標的一個重要市場推動因素。
要優化大量基於攝影鏡頭的駕駛輔助系統的成本,須得降低模組製造成本,並精簡物料清單。在這兩種情況下,功耗都是一個重要的限制因素。
嵌入式低功耗視覺平台的解決方案能進一步降低功耗,同時支援靈活的軟體程式設計,針對具有較高的內在並行性的視覺處理演算法調整同構大規模並行APEX視覺加速器,會大大降低功耗。
使用基於OpenCL的標準程式設計模型,可最大限度地減少從基於PC的演算法開發環境移植到嵌入式平台的工作,進而加快上市速度、降低軟體發展成本。
對象分類和跟蹤等不太規則的視覺處理部分,將在多個節能的RISC內核上進行處理,這些內核通過其整合的向量處理引擎提供良好的訊號處理效能,並透過充分考慮資料訪問模式的特點、在本機存放區資料,以及避免使用在印刷電路板上的外部動態記憶體。
如此一來,就能可大大降低嵌入式低功耗視覺處理平台的大資料量訪問消耗的功率,同時大幅提升處理效能,並支援進階功能(如高速物體檢測)。
(本文作者皆任職於飛思卡爾)