由於未來科技傾向認知型的世界,認知運算的重點在資料處理與分析,電腦資訊系統要處理非結構化資料(例如文字、影像、聲音、影片)需要有了解、推理和學習等要件,也就是系統要能了解使用者身處環境裡面的資料,然後能發現資料之間的關聯性,進而推理並進行自我學習。
隨著近年來人工智慧(Artificial Intelligence, AI)的興起,許多科技領域正透過人工智慧、機器學習與深度學習來驅動各種創新技術的實現,正是因為人工智慧系統與人工智慧演算法包含使機器(如電腦)具有資料處理能力、推理以及深度學習的模型,這些人工智慧系統與模型經常被高密度地訓練來執行特定的任務,例如神經語言處理、影像辨識、計畫和決策等諸如此類的任務。
基於人工智慧浪潮來襲及電腦速度要求越來越高,目前全世界採用傳統馮紐曼架構的電腦對於運算量動輒幾億次的AI運算有其限制與瓶頸,已無法滿足越來越多資料密集型應用,使得記憶體技術亦面臨改朝換代的轉折點,剛好記憶體內運算非常適用於人工智慧的硬體加速,彼此相得益彰、加速其發展,記憶體內運算技術因此應運而生成為現今追求的架構,擴大對記憶體內運算的市場。
從馮紐曼架構至記憶體內運算
在電腦科學、經濟、物理學中的量子力學及幾乎所有數學領域都有偉大貢獻的數學家馮紐曼(John von Neumann),是一位出生於匈牙利的美國籍猶太人,在他22歲時就取得布達佩斯大學數學博士學位,從此贏得天才的聲譽。1945年6月,馮紐曼以EDVAC(Electronic Discrete Variable Automatic Compute)為題起草了一份101頁的報告,即電腦史上著名的「101頁報告」。報告中,首先提出以二進制取代十進制運算的概念,將儲存裝置與中央處理器分開,建立所謂內存程式(Stored Program)架構的計算機體系,也就是以記憶體來儲存計算機的指令與資料,以利CPU依據中間的結果來修改後續指令,為電腦的邏輯結構設計樹立了一座里程碑,至今全世界的電腦皆仍採用此「馮紐曼架構」,或稱馮紐曼模式(Von Neumann Model)。基於他在電腦邏輯結構設計上的偉大貢獻,而有「電腦之父」或「計算機之父」的美譽。
當今的電腦,都是基於這種內存程式概念的馮紐曼模式的架構(圖1),主要有五大子系統:記憶體(Memory)、算術邏輯單元(Arithmetic Logic Unit, ALU)、控制單元(Control Unit)、輸入(Input)、輸出(Output)。馮紐曼架構主要的精神是,必須要有記憶體以便存放資料與程式,且任一記憶體位址皆能任意地讀和寫;再者,必須要有計算與邏輯的運算能力;以及要有一控制單元負責記憶體與算術邏輯運算單元的資料傳送。因此,馮紐曼架構最大的特徵是,將程式編碼後儲存於記憶體中,視同將程式指令也變成「資料」,透過算術邏輯單元自記憶體中讀取指令來執行,從此奠定了電腦設計的基本原則。
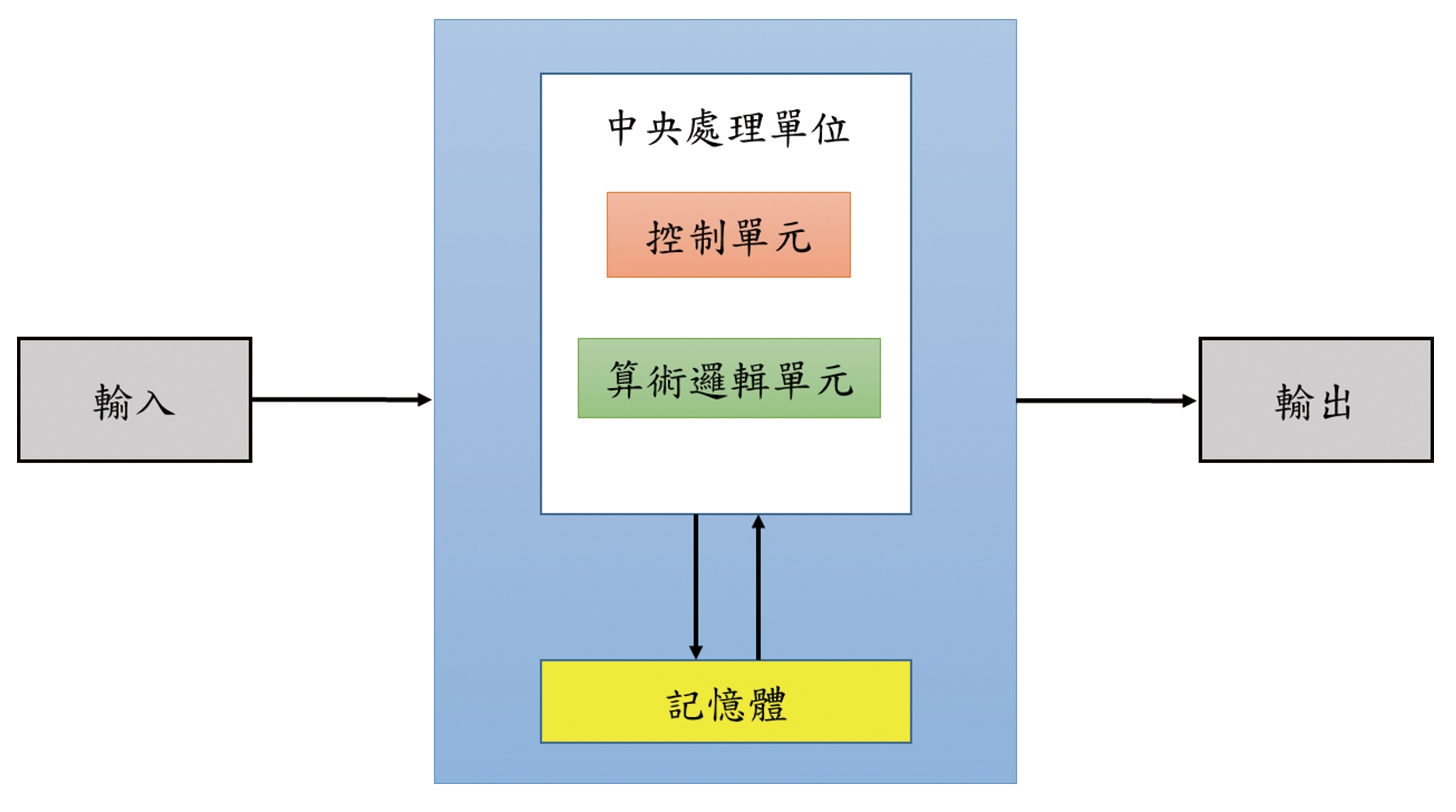 圖1 馮紐曼架構
圖1 馮紐曼架構
然而,這種將記憶體與中央處理單元分開的架構並非完美,對於需要龐大運算量的AI運算,會導致所謂的馮紐曼瓶頸(Von Neumann Bottleneck),且當中央處理器的運算速度和記憶體傳輸速率差距越巨大,瓶頸問題將越嚴重。特別是發展認知運算需要有效率處理大量的資料,這對傳統的馮紐曼架構而言是一大挑戰;因為採用馮紐曼架構執行AI應用時,中央處理器和記憶體之間往往因大量的傳輸資料而耗費大量資源產生嚴重的功耗,導致系統效能不佳。隨著人工智慧產業的興起,越來越多資料密集型的應用,例如神經網路已蔚為風潮,為了有效解決馮紐曼瓶頸,避免中央處理器在資料輸入或輸出記憶體時閒置,記憶體內運算技術的誕生堪稱是一大福音,其核心概念為直接在記憶體內執行運算,並將運算後之結果傳到中央處理器;也就是直接搬移運算後的結果而非只是搬移資料至中央處理器後再執行運算,從而減少搬運資料的時間。
Mythic採用類比式記憶體內運算
人工智慧的特色是要能處理大量資訊並執行運算,記憶體內運算能顯著減少處理器和記憶體間資料傳輸所需的時間,其速度大幅提升的優勢吸引不少AI晶片新創公司或IP供應商相繼投入該領域,換言之許多新創公司就是衝著AI浪潮來的,其中不少業者正推出或規畫某種形式的客戶端AI加速器晶片。Mythic所開發的快閃記憶體陣列,基本上正如上所述,免除了將資料從外部記憶體移出移入的需要,因此大幅節省功耗與資料傳輸時間。
Mythic緣起於David Fick和Mike Henry在密西根大學(University of Michigan)一起創立,在2012年成立於美國德州奧斯汀和加州矽谷紅木城,是一家經營人工智慧、機器學習、電腦視覺和神經網路的晶片設計新創公司。Mythic的新創團隊,成員包括來自德州儀器(TI)的類比專家、Microchip的快閃記憶體設計總監以及Netronome的實體設計專家,可謂專家組成的多元超強團隊,對其融資與募資助益不少。團隊成員不乏有軟體高手克服該領域的軟體障礙,使得晶片的記憶體陣列能處理更多樣化的卷積(Convolutional)或遞歸(Recurrent)神經網路。
Mythic成立宗旨在探索運算技術的新方向,致力於開發利用快閃記憶體的記憶體內處理器(Processor-in-memory)進行架構改變,目標是將神經網路映射至並聯式快閃記憶體(NOR-Flash)陣列,以或許可節省兩個數量等級功耗的方式來運算與儲存資料[1],以減少進行深度學習計算所耗費功率的方法。 Mythic聚焦結合AI與記憶體的全新運算架構,自2018年開始投入類比AI運算晶片的研究,採用類比式記憶體內運算(Analog Compute-in-memory)技術,利用快閃式記憶體(Flash Memory)創造記憶體內運算架構創新使用的模式,以類比運算來執行快閃記憶體陣列中深度神經網路(DNN)推論所需的計算,並試圖將類比AI運算晶片應用在雲端運算中。由於Mythic是採用類比式記憶體內運算技術執行類比資料的AI運算,消耗的功耗少,對於現有硬體架構而言,在功率、成本和效能上都是一種很大的突破。
實現混合訊號運算IC Mythic低功耗/低延遲專利技術
當實作類神經網路模型時,許多實作類神經網路模型或演算法的傳統電腦與系統,大多傾向使用大型電腦,以容納需要用來提供運算能力以及提升資料處理速度的巨量電路,且龐大的電路面積會產生更大的功耗,以加持運算能力。
因此,當神經網路模型實施一種或多種神經網路演算法時,往往會需要可觀的電路大小、消耗功率以及運算能力,來分類資料與推論或預測結果。舉例來說,加權求和計算普遍地使用在模式匹配(Pattern Matching)與機器學習應用(包含神經網路應用)中,但用於機器學習應用的一般加權求和計算包含上百或上千個權重,對於傳統數位電路來說,會使加權求和計算的運算量過於繁重,從而需要可觀的運算時間(換言之,增加延遲)與功率,導致神經網路模型或類似應用的加權求和運算所需要的傳統數位電路,傾向於龐大方能儲存神經網路模型所需要的權重,龐大的積體電路系統與所需功耗削弱了電腦的運算能力。
此外,這些用來實現人工智慧模型與類神經網路模型的傳統電腦與系統可能適合使用遠端運算,例如像是在分散式運算系統(例如雲端),或是使用許多現場的運算伺服器諸如此類。然而,無論是使用遠端邊緣運算或使用現場的設備,當這些遠端人工智慧處理系統用在運算推論結果時,延遲的問題便會顯現出來。也就是說,當這些傳統遠端系統試著去實現類神經網路模型,來產生推論以用於遠端現場設備,由於輸入資料通常必須要透過頻寬不一的網路來傳送,而且由遠端運算系統所產生的推論也必須由一樣或類似的網路回傳,因此由遠端現場設備接收輸入資料會有不可避免的延遲。
低延遲的好處是能夠將通訊網路上的延遲(Time Lag)降到最低,特別在講求安全性的自動駕駛、活躍於災害支援與工廠的機器人遠端操控,以及需要精確操作的遠距醫療等應用領域,具有顯著的效果。為了減少遠端人工智慧處理系統因實施神經網路模型進行運算推理的延遲,同時降低運算所需的功率及避免龐大電路數量的邊緣設備,AI晶片新創公司Mythic開發一種用於混合訊號運算的積體電路及運算混合訊號的方法[2],用於實現計算密集型程式,及其應用的混合訊號運算積體電路,使之具有必要的運算能力,來即時或近即時地進行預測或推論。
如圖2所示,該發明是有關用以實施混合訊號運算的混合訊號積體電路,其具有比較電路。該比較電路根據兩個求和節點(Summation Nodes)的輸出評估類比值,並根據評估結果產生二進位制輸出值。再者,為降低求和節點能耗,該混合信號電路透過控制器與差動電流電路(Differential Current Circuit)間之交互作用,以改變提供給正求和節點與負求和節點的電流之間的差值[3]。
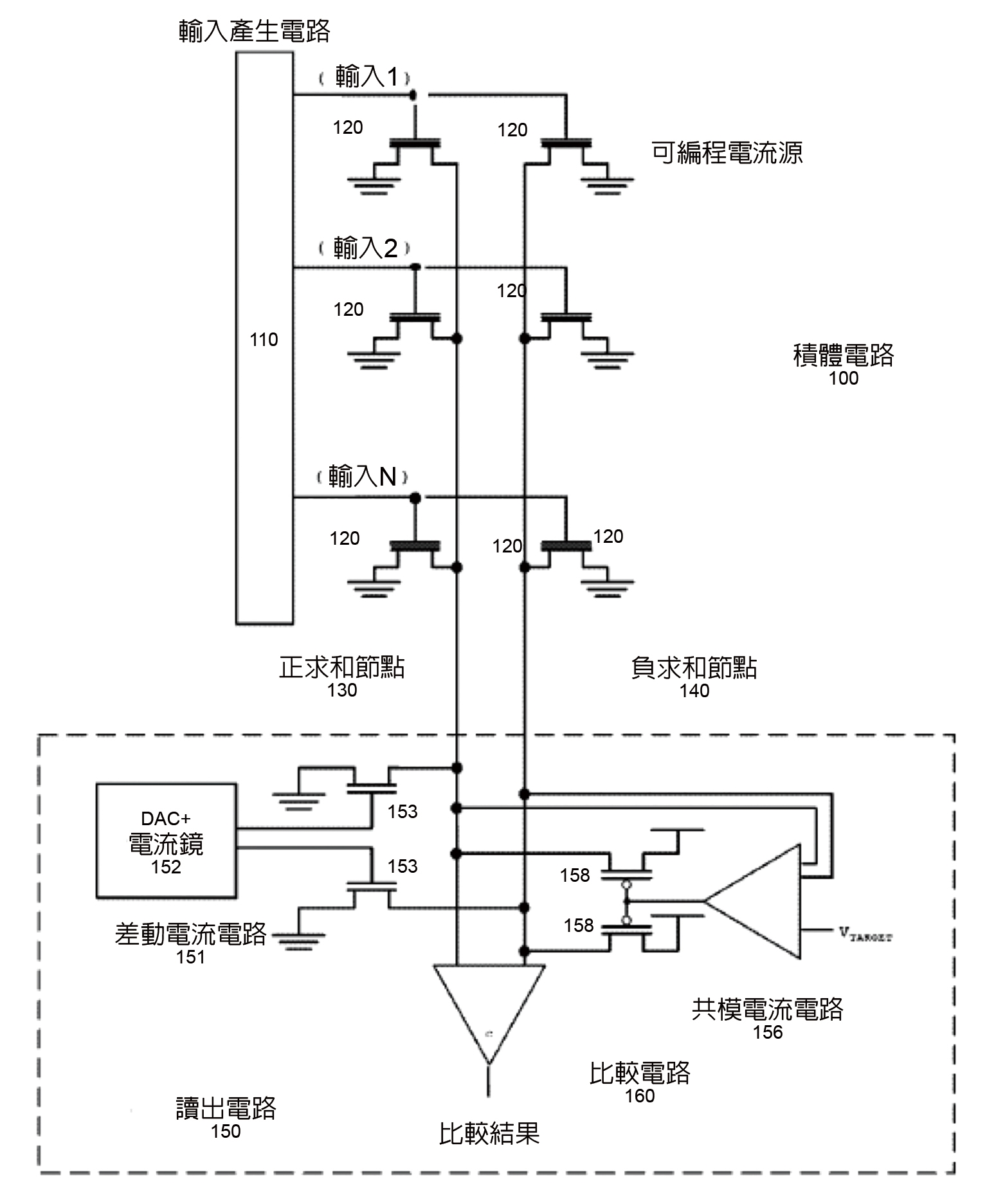 圖2 積體電路示意圖
圖2 積體電路示意圖
將矩陣計算映像至一矩陣乘法加速器的系統與方法
在某些情況下,即使積體電路的陣列包含足夠的記憶體可以儲存機器學習演算法的上百萬個權重,但積體電路的其他限制條件,例如固定數量的輸入及/或固定數量的輸出可能無法與機器學習演算法的權重的精確矩陣配置匹配或對齊,從而需要一種有彈性的方法來映像機器學習演算法(或其他計算密集的應用/程式)的權重的矩陣。因此,Mythic開發一種用於將矩陣計算映像至一矩陣乘法加速器的系統與方法,以最佳化該複數個矩陣乘法加速器的利用率及/或效能的方式,透過實施一個矩陣記憶體映像技術或一個矩陣結合記憶體映像技術可以被映像至該複數個矩陣乘法加速器[4]。換言之,其涉及根據一種係數記憶體映像技術來配置積體電路的矩陣乘法加速器的陣列,從而將矩陣計算映像至一矩陣乘法加速器的系統與方法。
圖3繪示了矩陣乘法加速器單元的示意圖。矩陣乘法加速器單元包含複數個內部記憶體元件210用以儲存於其中的係數來表現一矩陣。在此示例中,一輸入列向量一般可以與儲存於矩陣乘法加速器單元的內部記憶體元件210中的係數矩陣相乘以產生一輸出列向量。
在一實施例中,圖3的矩陣乘法加速器單元較佳包含M個輸入訊號,可由矩陣乘法加速器單元所接收的M個輸入訊號的數量取決於矩陣乘法加速器單元的列數量,使得M會與矩陣乘法加速器單元的列數量相等。再者,圖3的矩陣乘法加速器單元較佳包含N個輸出訊號,矩陣乘法加速器單元所能產生的N個輸出訊號的數量取決於矩陣乘法加速器單元的行數,使得數量N與矩陣乘法加速器單元的行數量相等。輸出訊號較佳基於輸入列向量的每一個輸入訊號乘以矩陣乘法加速器單元中給定的列/行位置的對應的矩陣係數來產生。結果的積可以再與矩陣乘法加速器單元的一行中所計算出的其他積一起被加總以形成矩陣乘法加速器單元之一給定行的N個輸出值。此計算方法一般被描述為矩陣乘法加速器單元的行乘積累加。
在圖3中,矩陣乘法加速器單元可以包含多工器選取電路(Multiplexer Select, MPS)220,多工器選取電路220可以具有多種設定其可使矩陣乘法加速器單元能選擇性地表達可以比給定的矩陣乘法加速器單元所產生的輸出(N)的數量更少的實體輸出。特別是,多工器選取電路220可以用來選取(或啟動/停用)矩陣係數行的子集來計算輸出。在一被選取或被啟動的狀態中,矩陣行被選取的子集可以被用來計算出一積來輸出。在一沒有被選取或停用的狀態,一個沒有被選取的矩陣行的子集可以被無效或暫時設成零數值,使得沒有乘積產生或者是乘積為零。 至於將矩陣計算映像至一矩陣乘法加速器的方法,包含基於運算一個或多個應用的屬性來從複數種區別利用率限制條件型態中識別出該固定的記憶體陣列的一種利用率限制條件型態;從複數種區別係數記憶體映像技術中識別出至少一種可以應付該利用率限制條件型態的係數記憶體映像技術;以及根據該至少一種係數記憶體映像技術來配置該固定的記憶體陣列。其中配置該陣列的步驟至少包含以該至少一種可最佳化固定的記憶體陣列的一計算利用率的係數記憶體映像技術所規定的排列來設定該陣列中該一個或多個應用的係數。
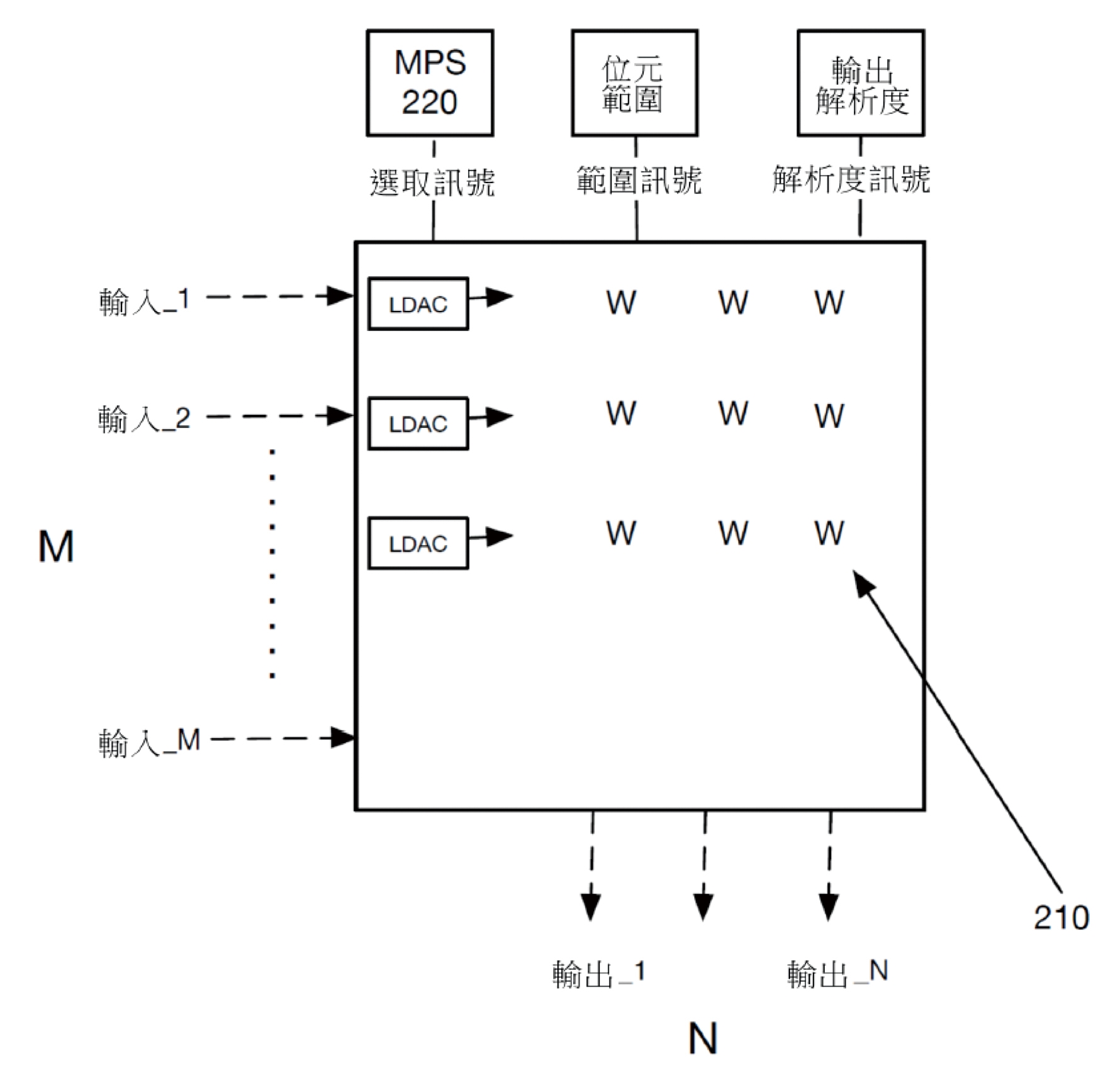 圖3 矩陣乘法加速器單元的示意圖
圖3 矩陣乘法加速器單元的示意圖
從Mythic的特色看AI新創公司發展記憶體內運算技術的條件與趨勢,可包含下述三項特點。
1. 新創團隊較佳擁有多元專長的組合:
機器學習使用的類比電腦基本上是一個整合性的龐大工程,其必須考量很多諸如不匹配(Mismath)、雜訊、溫度等的類比效應,相較於數位電腦更需要跨領域人才方能同時一起設計所有的東西,例如了解彼此領域的元件端設計與神經網路設計工程師。此外,團隊成員中軟體人才是關鍵,特別需要幾個深度學習科學家克服軟體障礙,但這類專家非常短缺、費用昂貴,且建立資料集與神經網路並進行訓練非常耗時、代價也很高,這些都是冒險進軍且投資此領域的限制。
2. �從學校獨立的新創公司會更容易成功量產:
當以研究所學生身份設計晶片,包括記憶體、合成、設計規則檢查變異(DRC Variations)等所有的步驟都得自己動手;反之,若是直接進入業界,可能看不到整個設計流程,所以很多從學校獨立的新創公司會更容易成功量產。
3. 類比AI運算技術有助於市場應用:
用類比資料來做AI運算(例如乘法運算或加法運算)是直接在終端分析即時且連續的類比資料,因為不需要轉存成數位資訊到記憶體,致使記憶體與處理器之間資料傳輸的功耗大大減少,因此在類比AI晶片的架構上所需要的電晶體數量就會少很多,功耗也大約是執行數位運算的1%而已。因此,類比AI運算技術開發的記憶體陣列,基本上可免除將資料從外部記憶體移出移入的需要,大幅節省運算功耗與晶片成本,應用市場包括可在所有設備中實現語音控制、電腦視覺和其他的AI技術,特別是需要透過複雜神經網路且相當耗能才能運作的應用。
簡言之,將類比運算AI晶片與各式終端感應器結合就是類比AI運算技術所要開發的市場應用,例如將類比AI晶片結合攝錄影機進行影像辨識以減少大量數位資料儲存、傳輸上雲所耗費的頻寬與記憶體空間,結合自駕車進行影像辨識以減少有線傳輸造成的判讀延遲,或者結合智慧音箱進行語音辨識來降低辨識的耗電量等等,都是類比AI運算技術具有潛力的市場應用。

(本文作者為工業技術研究院技術移轉與法律中心博士)