生成式AI對運算設備的記憶體容量、性能有極高要求。能協助客戶跨越這道記憶體高牆的業者,將在市場競爭中居於有利地位。而隨著邊緣AI的趨勢發展,這類邊緣裝置所帶來的記憶體需求,亦值得關注。
記憶體的容量與頻寬,會對生成式AI應用的效能表現造成決定性的影響。而且,在許多情況下,記憶體才是整個運算系統裡最主要的瓶頸所在。對記憶體供應商而言,能否協助客戶跨越這道記憶體高牆,已成為公司能否打入AI供應鏈,創造營運佳績的關鍵。
近期市場研究機構Counterpoint便指出,由於SK海力士(SK Hynix)在高頻寬記憶體(HBM)領域擁有領先優勢,因此以營業額計算,該公司已經以些微幅度超越三星電子(Samsung Electronics),成為全球最大的DRAM供應商。從這點亦可看出,針對AI應用的布局,對當前的記憶體產業來說,是多麼關鍵。
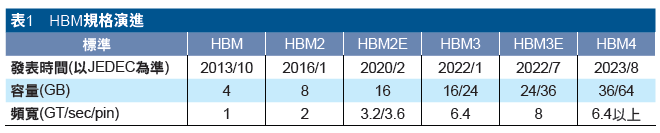
也因為AI應用已成為記憶體業者的兵家必爭之地,與AI相關的記憶體技術創新,正在明顯加速(表1)。但當前記憶體業者的AI戰場已不只局限於與GPU搭配的HBM,與伺服器CPU搭配的SOCAMM,也是一條新的戰線。同時,在邊緣設備端,不管是消費級/專業級顯卡使用的GDDR,或是小型AI工作站改採統一記憶體架構,都是記憶體產業日後必須特別留意的重點。
HBM/SOCAMM成兩大主戰場
美光副總裁暨運算與網路事業部運算產品事業群總經理Praveen Vaidyanathan表示,高效能、高頻寬的記憶體,是生成式AI應用的基礎。要充分發揮處理器執行AI運算任務的潛力,必須設法突破記憶體存取的瓶頸。因此,在處理器效能不斷成長之際,記憶體技術的創新步伐也必須快速跟上。
 美光副總裁Praveen Vaidyanathan表示,HBM與SOCAMM將是AI運算效能更上一層樓的關鍵
美光副總裁Praveen Vaidyanathan表示,HBM與SOCAMM將是AI運算效能更上一層樓的關鍵
目前AI伺服器上,主要搭載兩種不同的處理器,分別是負責執行大規模平行運算的GPU,以及負責通用運算的CPU。其中,因為GPU可以執行大規模平行運算,所以與其搭配的記憶體,必須具有最高的頻寬,且為了因應模型規模成長的趨勢,其儲存容量也要跟著增加。因此,在NVIDIA最新推出的HGX B300 NVL16和GB300 NVL 72上,都將搭載大量HBM3E記憶體,而美光也將為其提供採用12層堆疊,單一CUBE容量高達36GB的產品;8層堆疊、容量24GB的產品,則會用在HGX B200與GB200平台上。
至於在CPU方面,美光則會為NVIDIA提供基於LPDDR5X的SOCAMM產品(圖1)。先前SOCAMM曾在市場上引發許多討論,因為該技術規格並非記憶體產業的共通標準,而是專門設計來搭配NVIDIA GRACE CPU的記憶體技術規格。許多業界人士都指出,SOCAMM的出現,可能會引發產業碎片化的結果,因為其他處理器供應商,如英特爾(Intel)、超微(AMD)的平台,將無法支援SOCAMM。
 圖1 美光專為AI伺服器打造的SOCAMM模組。該模組上的記憶體顆粒為四組16層堆疊的LPDDR5X記憶體,單一模組的最大容量可達128GB。
圖1 美光專為AI伺服器打造的SOCAMM模組。該模組上的記憶體顆粒為四組16層堆疊的LPDDR5X記憶體,單一模組的最大容量可達128GB。
事實上,類似的事情先前曾在筆記型電腦上發生過。筆記型電腦用的記憶體模組標準規格為SO-DIMM,但這個標準已經存在超過20年,越來越難滿足未來行動運算的需求,因此業界開始討論一種名為壓縮附加記憶體模組(Compression Attached Memory Module, CAMM)的新標準。但在標準制定完成之前,三星電子就率先發表了基於自家LPDDR的模組產品,將其命名為LPCAMM,使得LPCAMM變成三星的自有規格。後來,各家記憶體業者在JEDEC上達成共識,推出LPCAMM2標準,才解決了標準分歧的問題。
Vaidyanathan表示,雖然SOCAMM是與NVIDIA合作的產品,但記憶體業界有共識,必須要有一個產業共通標準,才能把市場做大。因此,美光未來會與其他記憶體供應商合作,將SOCAMM發展成產業共通標準。
CPU仍為AI伺服器的關鍵要素
為何NVIDIA需要跟記憶體業者聯手,發展自有的記憶體規格?Vaidyanathan表示,最主要的原因還是效能考量。
提到AI伺服器,一般都會想到GPU,CPU則是配角,但在AI伺服器裡面,CPU仍扮演非常吃重的角色。AI資料中心的網路可以分成前端網路跟後端網路,前端網路主要的任務之一,是應對使用者需求,將其傳送到後端網路;後端網路則是由大量GPU處理器組成,其職責是利用其大規模平行運算能力來實現AI加速運算。而在前端網路裡承擔主要運算任務的晶片,就是CPU。因此,如果CPU的運算效能不足,不只會影響後端GPU網路運作,也會影響到AI服務的使用者體驗。
比起目前伺服器產業所採用的RDIMM,SOCAMM的效能、外觀尺寸、能源效率都更好。以美光的SOCAMM產品為例,首先,SOCAMM的匯流排寬度為128位元,RDIMM則是64位元,因此在每次傳輸能傳的基礎資料量方面,SOCAMM就比RDIMM多了一倍;同時,SOCAMM上搭載的記憶體顆粒為LPDDR5X,其每秒傳輸次數為8533MT,比典型RDIMM上的DDR5顆粒要快得多,因此SOCAMM模組的資料頻寬,可達到RDIMM的2.5倍。
此外,SOCAMM的擴充性也比RDIMM更好,因為其外觀尺寸更小,單一模組可支援的容量更大。而且,SOCAMM的設計有考慮到液冷的因素,因此對伺服器業者來說,改用SOCAMM,可以更輕鬆地實現液冷設計,資料中心的擁有者要維護這些液冷AI伺服器,也會更方便。
AI工作站需求演變值得觀察
除了在雲端的AI伺服器,在邊緣端的AI工作站,也有許多值得密切觀察的趨勢正在發生中。Vaidyanathan指出,工作站這類產品的定位向來介在伺服器與個人電腦之間,但美光傾向於將工作站看成具有更高效能的邊緣設備,而非低效能的雲端替代方案。因此,這類產品所使用的記憶體技術,還是會比較接近邊緣設備。
不過,AI工作站還是可以分成兩類,一類是搭載大量繪圖卡的典型工作站,另一類則將CPU與GPU整合成SoC,並使用統一記憶體架構的新型AI工作站,像NVIDIA的DGX Spark(原名為Project DIGITS)。
以典型工作站來說,GDDR會扮演比較關鍵的角色,因為這類工作站上往往會配置多張顯示卡,而且單一顯卡上搭載的GDDR記憶體容量會比主流消費性顯卡要大,因此對記憶體供應商而言,這類產品所帶動的GDDR需求是值得期待的,美光在GDDR領域也有對應的布局。至於像DGX Spark這類採用統一記憶體架構,專門為了跑大語言模型而生的工作站,將會以LPDDR作為主記憶體。這是一個全新的產品類別,市場接受度、需求規模會有多大,目前還不好斷言。
整體來說,在本地端執行AI運算的需求是存在的,因此AI工作站這類產品的市場規模將持續成長,而且這個市場會創造出多樣化的記憶體需求,像LPDDR、GDDR,甚至NVMe SSD,都有機會在邊緣AI的發展中找到機會。