基於機器學習的人工智慧,近幾年席捲整個科技產業,幾乎所有科技業者都不敢忽視人工智慧的應用商機跟未來發展潛力,FPGA業者也不例外。包含賽靈思(Xilinx)、英特爾(Intel)與萊迪思(Lattice)、微芯(Microchip)等國際知名大廠,均已針對機器學習推出對應的解決方案。不過,由於各家業者的核心技術與競爭優勢不同,因此在產品定位的選擇上,很明顯地出現「雲」、「端」通吃與集中火力,強攻邊緣運算兩條不同的發展路徑。
由於「雲」與「端」的需求存在極大差異,加上大容量、高效能FPGA市場一直以來都是由賽靈思與英特爾兩強寡占,因此產品布局能涵蓋兩個不同應用市場的業者,僅賽靈思與英特爾兩家。但由於邊緣推論是一個非常龐大的市場,因此許多原本專注於發展低功耗、小容量FPGA/PLD的晶片業者,也紛紛展開布局,並且不約而同地將重點放在與影像辨識相關的應用上。
AI帶來極致效能需求賽靈思/英特爾強攻資料中心
人工智慧的興起,對資料中心市場帶來了極大的影響。由於機器學習的模型訓練需要極大的運算能力,因此在伺服器內部,除了CPU之外,開始出現各式各樣的硬體加速器或協處理器。另一方面,為了因應暴增的資料流量,不僅資料中心內部使用的乙太網路規格升級腳步未見停歇,許多大廠也開始倡導SmartNIC的概念,以實現更靈活、彈性的網路互連。
對高效能、大容量FPGA的供應商而言,網通一直是非常重要的應用市場,特別是電信與雲端機房所使用的高階產品。由於高階路由器、交換器等設備的市場需求規模不大,專門為這類應用開發ASIC的成本效益不見得划算,因此很多高階網通設備內部都會用到FPGA。從供應商的角度來看,網通設備也確實是公司營收很重要的來源,不管是英特爾的FPGA事業部門(原Altera)或賽靈思,來自網通應用的營收長期以來都在三到四成之間,可見網通是FPGA一個非常重要的應用市場。
人工智慧應用的需求竄起,為資料中心的內部網路架構帶來極大的升級推力。由於機器學習模型的訓練跟推理都會產生龐大的資料流,因此顯而易見的是,資料中心內部網路設備的頻寬還需繼續向上攀升。但除了頻寬升級外,許多雲端服務供應商也開始思考,要如何讓資料中心內部的資源調度更加彈性靈活,以提高資本支出的投資報酬率,SmartNIC的概念也因而誕生。
傳統的網路介面卡(Network Interface Card, NIC)跟SmartNIC最大的差別,在於SmartNIC把原本必須靠CPU處理的一部分網路功能,主要是網路虛擬化(Network Virtualization),轉移到NIC的主晶片上執行。這不僅有助於減輕CPU的工作負荷,也能讓資料路徑明顯縮短,有助於提高網路運作的效率。但這也意味著NIC上的主晶片必須具備一定的運算能力,否則原本由CPU負責的功能將無法實現。
因此,對FPGA業者來說,SmartNIC是一個相當重要的發展機會。相較於使用ASIC或SoC解決方案,基於FPGA的SmartNIC擁有最高的可編程彈性,這意味著開發者可以隨時調整資料路徑的配置與晶片功能。相較之下,ASIC或SoC在設計完成後,即便其資料路徑具有一定的可編程能力,有些電路功能還是已經固化,無法隨應用需求彈性調整。
由於看好SmartNIC的發展趨勢,賽靈思在2019年購併SolarFlare之後,旋即推出了基於自家FPGA、MPSoC與ACAP可編程方案的SmartNIC產品。同樣的,原本就是高階NIC晶片與板卡主要供應商之一的英特爾,也已推出基於FPGA的SmartNIC產品。
至於在資料處理、運算端,人工智慧所帶起的最重要趨勢,莫過於領域專用運算架構的興起。如果從更宏觀的角度來觀察,SmartNIC本質上也是一種領域專用運算架構,只是其側重的面向是資料傳輸跟資料路徑的配置,而不是資料處理的效能。但對於人工智慧這類應用來說,資料傳輸的效率或資料處理的能力,是同樣重要的。
賽靈思(Xilinx)技術長辦公室研究員Ralph Wittig認為,人工智慧等對運算效能需求極高的應用,還是需要使用領域專用架構硬體來運算,才能在運算效能、功耗跟整體成本之間取得最佳平衡。
根據賽靈思的觀點,基於FPGA的領域專用架構有三個元素,分別是適應性硬體、近記憶體運算與可支援多樣化資料傳輸模式的晶片內互連。以賽靈思的Versal適應性運算加速平台(ACAP)為例(圖1),該晶片架構內含多顆AI核心、用來直接存取外部記憶體的DMA,同時每個核心都帶有小容量的記憶體,以及扮演晶片內部互聯骨幹的Network on Chip(NOC)。
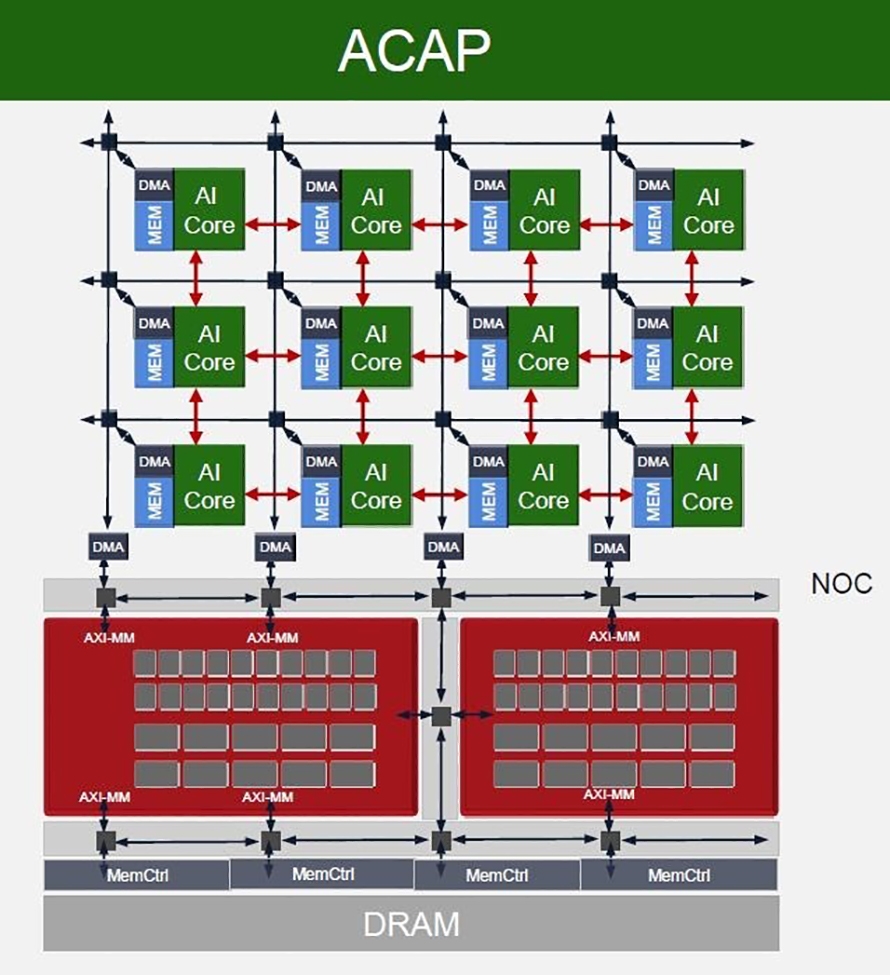 圖1 ACAP硬體架構
圖1 ACAP硬體架構
AI核心本身是軟體可編程的處理器,但藉由NOC,不同核心所配備記憶體是可以直接互聯的。這意味著如果使用者需要,可以把每個核心所帶有的記憶體互聯起來,視為一個容量超大的快取。
不像現有的CPU或GPU,採用階層式的快取記憶體,當核心要存取記憶體內的資料時,視資料存放的位置,可能會遇到得等待數十到數百個循環週期(Cycle Time)才能得到資料的情況。除了存取效率外,傳統基於快取記憶體的架構,還會有不必要的資料複製、浪費記憶體容量的問題(圖2)。
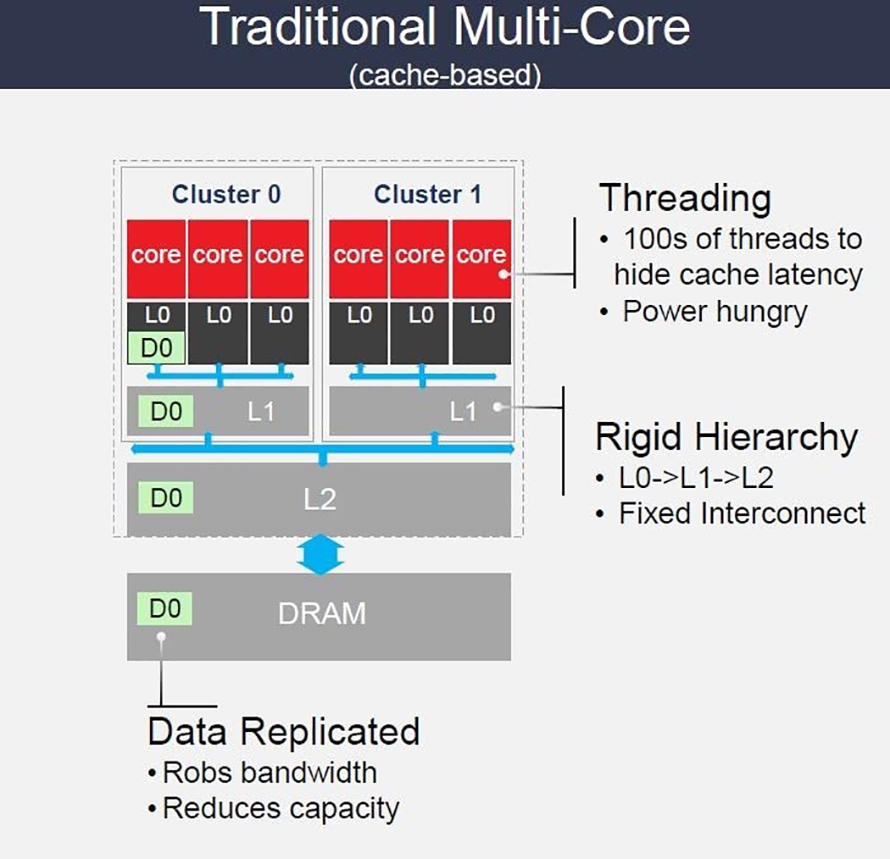 圖2 傳統多核心架構的資料存取
圖2 傳統多核心架構的資料存取
也因為FPGA內部的互聯是非常彈性的,使用者可以依照自己的應用需求,實現各種不同的資料搬移模式,從業界最熟悉的管線式(Pipeline)結構,到一對一/一對多串流式(Stream),甚至廣播式(Broadcast)結構都能支援(圖3)。這使得FPGA的使用者可以針對特定應用需求,使用效率最好的資料搬移模式來處理大量資料。
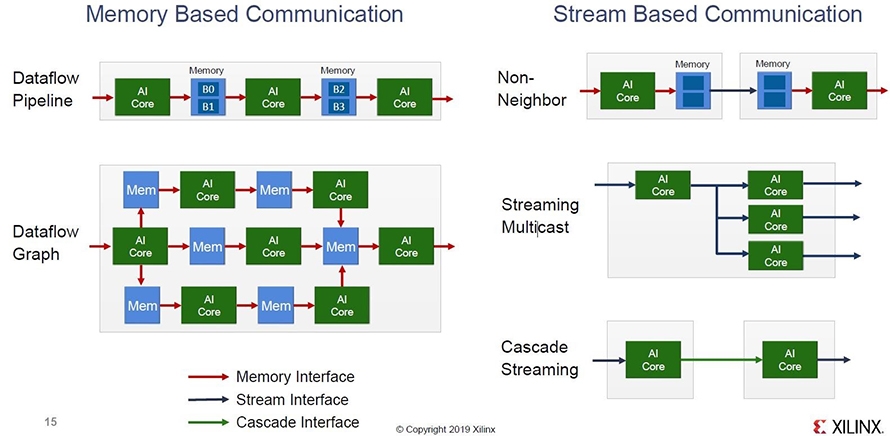 圖3 多樣化的資料搬移模式
圖3 多樣化的資料搬移模式
根據賽靈思的估計,這種架構讓Versal可以用存取L1快取的延遲,存取到10倍的記憶體容量。這不僅提升了運算效能,同時也降低晶片的功耗。事實上,存取記憶體是非常耗電的,以典型的45奈米、0.9伏特製程來說,處理器要存取8kByte SRAM,就要消耗10pJ能量;但如果是要存取1MByte SRAM,就要消耗100pJ;但如果處理器核心要存取外部DRAM,就至少要消耗1.3~2.6nJ,能量消耗可達2,000倍。
Wittig總結說,如果設計人員非常在意處理器功耗跟運算效能,應該注意以下三個原則:首先,讓資料保持流動,只有在必要的時候才作暫存;其次,如果要做資料暫存,應該盡可能使用容量最小的記憶體;第三,盡可能把資料存放在晶片內的記憶體,不要放到外部DRAM上。
事實上,這也是一種思維的翻轉。在通用運算架構裡,是處理器下指令,把資料搬到核心來處理,但在領域專用架構裡,為了追求更好的運算效能跟降低功耗,是處理單元要盡量貼近資料。
ACAP架構因為具有「適應性硬體」、「近記憶體運算」與可支援「多樣化資料傳輸模式的晶片內互連」這三大特性,目前已經是一個相當理想的適應性資料流處理器。接下來,ACAP架構會朝強化平行運算的方向前進,利用ACAP架構的適應性互聯跟低延遲特性,讓眾多AI核心有更大的發揮空間。
萊迪思/微芯強攻邊緣推論市場
相較於英特爾跟賽靈思同時擁有大容量/高性能與小容量/低功耗產品線,專攻低功耗可編程邏輯元件市場的萊迪思、微芯,在產品策略上很明顯地聚焦在邊緣推論市場上。
例如萊迪思近日便宣佈推出CrossLink-NX,為首款基於該公司Nexus FPGA技術平台的產品。全新FPGA為開發人員提供通訊、運算、工業、汽車和消費電子系統的創新嵌入式視覺和AI解決方案時所需的低功耗、小尺寸、可靠性和高效能特色。
萊迪思亞太區資深事業發展經理陳英仁表示,5G、雲端分析、工廠自動化和智慧家居等技術趨勢正推動市場對支援機器學習的嵌入式視覺解決方案的需求。然而,基於雲端的機器學習會帶來資料延遲、成本和隱私問題,開發人員需要將更多資料處理工作從雲端轉移到網路終端。但是這會需要OEM廠商使用擁有高效能資料處理、以低功耗運行且尺寸較小的網路終端AI/ML推理解決方案。由於FPGA具有平行處理能力,因此是嵌入式視覺和AI應用的絕佳硬體平台。這種平行架構大幅加快了資料推理等特定處理工作負載的效率。
然而,相較於雲端機房環境,位於網路終端的設備往往有更嚴格的功耗限制。也因為這點,適合雲端機房使用的FPGA,跟為邊緣運算應用開發的FPGA,在設計架構跟製程技術上,有很大的差異。以CrossLink-NX為例,該系列FPGA採用全新的Lattice Nexus平台,結合三星電子的28奈米FD-SOI製程,針對小尺寸、低功耗應用進行最佳化(圖4)。
 圖4 基於FD-SOI製程的FPGA,由於電晶體架構不同,不僅具有更省電的優勢,軟錯誤率也比傳統FPGA更高。
圖4 基於FD-SOI製程的FPGA,由於電晶體架構不同,不僅具有更省電的優勢,軟錯誤率也比傳統FPGA更高。
在功耗方面,由於FD-SOI製程先天就具備比CMOS製程更省電的優勢,因此CrossLink-NX與同類FPGA相比,功耗降低75%。在尺寸方面,跟其他同業的類似產品相比,CrossLink-NX的封裝尺寸約僅有其十分之一,能夠讓客戶進一步縮小系統產品的尺寸。
除了低功耗、小尺寸外,為了滿足機器視覺等AI相關應用的需求,高速I/O的支援與大容量記憶體也十分關鍵。CrossLink-NX FPGA支援各種高速I/O,包括MIPI、PCIe和DDR3記憶體,非常適合嵌入式視覺應用。在記憶體方面,CrossLink-NX的記憶體與邏輯比是同類產品中最高的,平均每個邏輯單元有170 bit儲存空間。
這是專門為了支援AI推論而做出的設計,因為AI推論也會使用到大量記憶體,而且這些記憶體必須非常靠近邏輯。如果完全靠外掛記憶體來儲存資料,一來運算延遲會明顯增加,二來資料搬移會消耗大量電力,與邊緣運算最注重的低功耗、低延遲特性產生矛盾。 無獨有偶,微芯在2018年收購Microsemi,取得其FPGA產品線跟技術後,也將FPGA業務的重心放在邊緣AI推論市場上,特別是與影像辨識有關的應用。在2019年台北國際電腦展(COMPUTEX)期間,微芯便在其攤位上公開展示了基於其PolarFlare FPGA的AI機器視覺方案。該解決方案的影像更新率可達24FPS以上,但完全不需要使用散熱片來幫助散熱,甚至在系統全速運轉的情況下,手指直接接觸晶片也僅感受到微溫,是該方案最大的特點。
微芯表示,目前邊緣AI推論的主要應用,大多與機器視覺有關,但因為這類設備必須設計成嵌入式系統,才能滿足應用場域的條件限制,因此功耗跟散熱是客戶最關心的技術指標。如果功耗過高、晶片發熱量太大,客戶在進行產品開發時,不是得使用風扇散熱,就是要靠笨重的散熱片來進行被動散熱,這都不是最理想的解決方案。
AI應用引領FPGA未來發展趨勢
FPGA是一個很特殊的行業,在其漫長的發展歷史中,主要應用市場已經歷過許多次轉變。一開始,FPGA是以軍工航太這類需求量極低,但又需要高度客製化晶片設計的市場需求而發展出來的技術。
很快的,眾多半導體IDM廠跟晶片設計公司的研發團隊發現,FPGA是一個絕佳的晶片設計驗證工具,並因而打開了FPGA走向商業市場的道路。隨後,FPGA開始被應用在各種電信級跟企業級通訊設備上,使得跟通訊息息相關的I/O性能,成為每家FPGA業者彼此競爭的重點。
正如同考試會引導教學,市場需求也會引導FPGA的設計趨勢。在FPGA作為晶片開發工具的年代,FPGA使用者最看重的是FPGA的邏輯容量,也引導了FPGA供應商的產品發展路線圖,因為要把SoC設計放進FPGA裡面,最常遇到的問題就是FPGA能提供的邏輯容量不足。至於FPGA內建的記憶體容量大小,則是次要的規格考量。而隨著FPGA開始被廣泛應用在通訊領域,FPGA業者又開始競相推出整合高速串列/解串列器(SERDES)的FPGA產品,以滿足客戶對高頻寬通訊的需求。
如今,AI的應用需求將再次改變FPGA設計的流行趨勢。首先,因為AI應用需要大量的記憶體,而且記憶體越接近邏輯單元越好,因此FPGA供應商除了開始導入HBM等高速記憶體,降低運算延遲外,FPGA內建的SRAM容量也明顯增加。其次,因為AI應用跟大數據脫不了關係,要應對大量資料流,不僅涉及到高速SERDES技術,FPGA的內部互聯也必須跟著改變。
可以預期的是,未來FPGA本身的設計架構,將因為AI的興起而再度翻新,未來FPGA業者之間的競爭,或將再度走向架構創新之爭。